Dublerede data kan ofte føre til forvirring, fejl og skæv indsigt. Heldigvis giver Google Sheets os mange værktøjer og teknikker til at forenkle opgaven med at identificere og fjerne disse overflødige poster. Fra grundlæggende cellesammenligninger til avancerede formelbaserede tilgange vil du være udstyret til at omdanne rodede ark til organiserede, værdifulde ressourcer.
Uanset om du håndterer kundelister, undersøgelsesresultater eller ethvert andet datasæt, er eliminering af duplikerede poster et grundlæggende skridt mod pålidelig analyse og beslutningstagning.
I denne vejledning vil vi dykke ned i to metoder til at give dig mulighed for at identificere og fjerne duplikerede værdier.
Bordskabelse
Vi oprettede først en tabel i Google Sheets, som vil blive brugt i eksemplerne senere i denne artikel. Denne tabel har 3 kolonner: Kolonne A, med overskriften 'Navn', gemmer navne; Kolonne B har overskriften 'Alder', som indeholder folks aldre; og til sidst indeholder kolonne C, overskriften 'By', byer. Hvis vi observerer, er nogle poster i denne tabel duplikeret, såsom posterne for 'John' og 'Sara.'
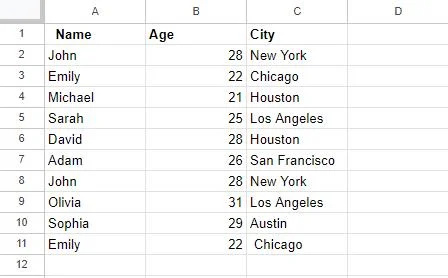
Vi vil arbejde på denne tabel for at fjerne disse duplikerede værdier med forskellige metoder.
Metode 1: Brug af funktionen 'Fjern dubletter' i Google Sheets
Den første metode, vi diskuterer her, er at fjerne de duplikerede værdier ved at bruge Google Sheets funktion 'Fjern dubletter'. Denne metode vil permanent eliminere duplikerede poster fra det valgte celleområde.
For at demonstrere denne metode vil vi igen overveje den ovenfor genererede tabel.
For at begynde at arbejde på denne metode skal vi først vælge hele rækken, der indeholder vores data, inklusive overskrifter. I dette scenarie har vi valgt celler A1:C11 .
Øverst i Google Sheets-vinduet kan du se en navigationslinje med forskellige menuer. Find og klik på 'Data'-indstillingen i navigationslinjen.
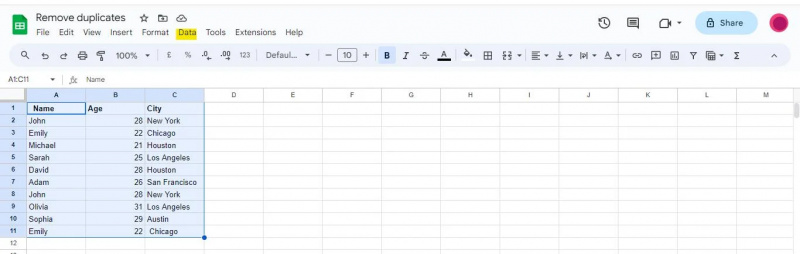
En rullemenu vises, når du klikker på 'Data', og præsenterer dig for forskellige datarelaterede værktøjer og funktioner, der kan bruges til at analysere, rense og manipulere dine data.
For dette eksempel skal vi have adgang til menuen 'Data' for at navigere til indstillingen 'Dataoprydning', som inkluderer funktionen 'Fjern dubletter'.
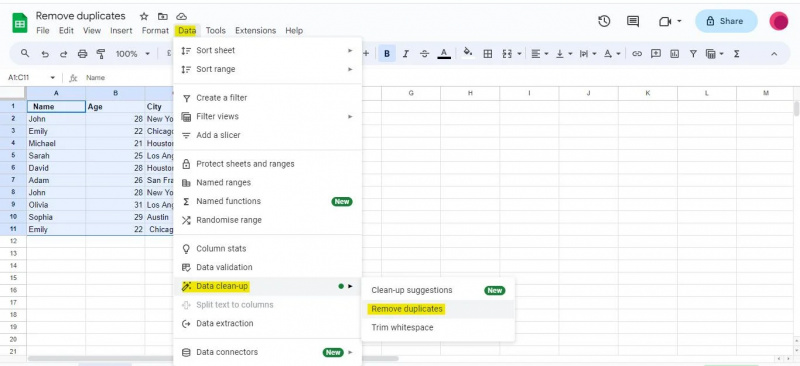
Efter at vi har åbnet dialogboksen 'Fjern dubletter', vil vi blive præsenteret for en liste over kolonner i vores datasæt. Baseret på disse kolonner vil dubletter blive fundet og fjernet. Vi markerer de tilsvarende afkrydsningsfelter i dialogboksen afhængigt af hvilke kolonner vi vil bruge til at identificere dubletter.
I vores eksempel har vi tre kolonner: 'Navn', 'Alder' og 'By'. Da vi ønsker at identificere dubletter baseret på alle tre kolonner, har vi markeret alle tre afkrydsningsfelter. Bortset fra det skal du markere afkrydsningsfeltet 'Data har overskriftsrække', hvis din tabel har overskrifter. Da vi har overskrifter i den ovenfor angivne tabel, har vi markeret afkrydsningsfeltet 'Data har overskriftsrække'.
Når vi har valgt kolonnerne til at identificere dubletter, kan vi fortsætte med at fjerne disse dubletter fra vores datasæt.
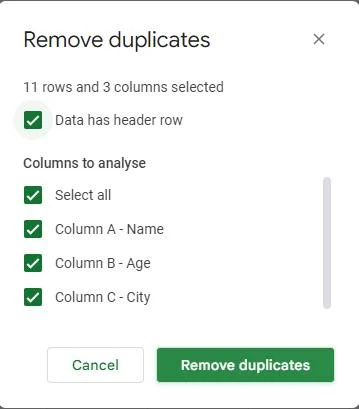
Du finder en knap i bunden af dialogboksen 'Fjern dubletter' mærket 'Fjern dubletter.' Klik på denne knap.
Når du har klikket på 'Fjern dubletter', behandler Google Sheets din anmodning. Kolonnerne vil blive scannet, og alle rækker med duplikerede værdier i disse kolonner vil blive fjernet, hvilket med succes eliminerer dubletter.
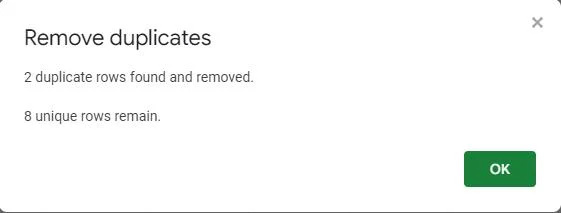
En pop op-skærm bekræfter, at de duplikerede værdier er blevet fjernet fra tabellen. Det viser, at to duplikerede rækker blev fundet og fjernet, hvilket efterlader tabellen med otte unikke poster.
Efter at have brugt funktionen 'Fjern dubletter' er vores tabel opdateret som følger:
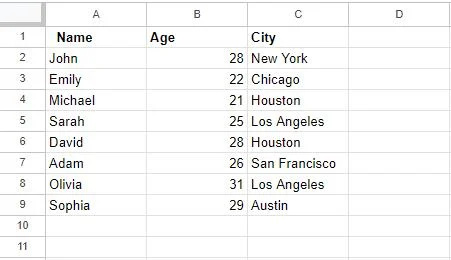
En vigtig note at overveje her er, at fjernelse af dubletter ved hjælp af denne funktion er en permanent handling. Dublerede rækker slettes fra dit datasæt, og du vil ikke kunne fortryde denne handling, medmindre du har en sikkerhedskopi af data. Så sørg for, at du har valgt de rigtige kolonner for at finde dubletter ved at dobbelttjekke dit valg.
Metode 2: Brug af funktionen UNIK til at fjerne dubletter
Den anden metode, vi vil diskutere her, er at bruge ENESTÅENDE funktion i Google Sheets. Det ENESTÅENDE funktion henter forskellige værdier fra et specificeret interval eller kolonne af data. Selvom det ikke direkte fjerner dubletter fra de originale data, opretter det en liste over unikke værdier, som du kan bruge til datatransformation eller -analyse uden dubletter.
Lad os skabe et eksempel for at forstå denne metode.
Vi vil bruge tabellen, der blev genereret i den indledende del af denne øvelse. Som vi allerede ved, indeholder tabellen visse data, der er duplikeret. Så vi har valgt en celle, 'E2,' til at skrive ENESTÅENDE formel ind. Formlen vi har skrevet er som følger:
=UNIK(A2:A11)
Når den bruges i Google Sheets, henter UNIQUE-formlen unikke værdier i en separat kolonne. Så vi har givet denne formel et område fra celle A2 til A11 , som vil blive anvendt i kolonne A. Denne formel udtrækker således de unikke værdier fra kolonne EN og viser dem i kolonnen, hvor formlen er skrevet.
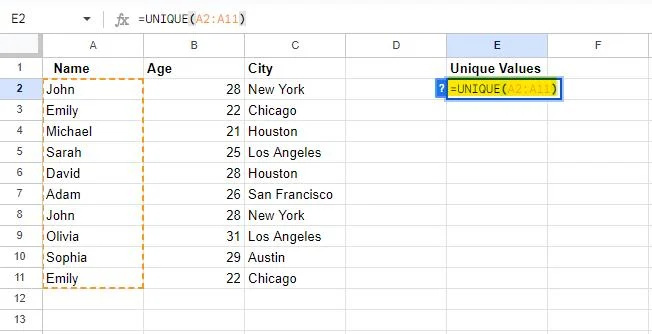
Formlen vil blive anvendt på det angivne område, når du trykker på Enter-tasten.
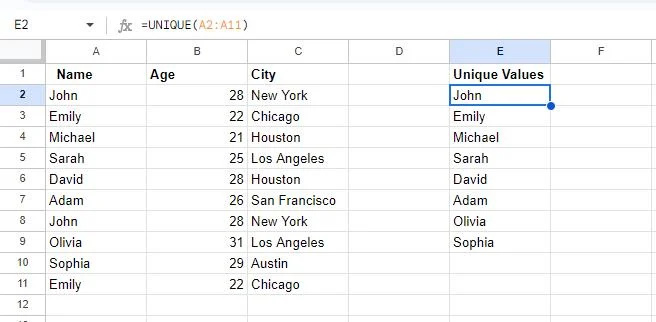
I dette øjebliksbillede kan vi se, at to celler er tomme. Dette skyldes, at to værdier er blevet duplikeret i tabellen, nemlig John og Emily. Det ENESTÅENDE funktion viser kun en enkelt forekomst af hver værdi.
Denne metode fjernede ikke de duplikerede værdier direkte fra den angivne kolonne, men oprettede en anden kolonne for at give os de unikke poster i den kolonne, hvilket eliminerede dubletterne.
Konklusion
Fjernelse af dubletter i Google Sheets er en fordelagtig metode til at analysere data. Denne vejledning demonstrerede to metoder, der gør dig i stand til nemt at fjerne duplikerede poster fra dine data. Den første metode forklarede brugen af Google Sheets til at fjerne duplikatfunktionen. Denne metode scanner det angivne celleområde og eliminerer dubletter. Den anden metode, vi har diskuteret, er at bruge formlen til at hente duplikerede værdier. Selvom det ikke direkte fjerner dubletter fra området, viser det i stedet de unikke værdier i en ny kolonne.