Dalle-mini er en deep learning-model, der kan generere billeder af høj kvalitet fra brugerinputtekst. Den er baseret på DALL-E modellen, som OpenAI udgav i januar 2021. DALL-E står for “ Usammenfiltret sprog og latent udtryk ” er et transformatorbaseret neuralt netværk, der kan kode tekst og billeder ind i et fælles latent rum og derefter afkode dem tilbage til begge modaliteter.
Denne artikel vil forklare følgende indhold:
Hvad er Dalle-mini?
Giv hende en mini er en mindre og hurtigere version af DALL-E, som blev skabt af EleutherAI, et open source-forskningskollektiv. Dalle-mini bruger kun 6 milliarder parametre, sammenlignet med DALL-E’s 12 milliarder, og den kan køre på en enkelt GPU. Dalle-mini bruger også en anden tokenizer og et andet ordforråd til tekstinput, hvilket gør det mere kompatibelt med forskellige sprog og domæner:

Bemærk : Brugere kan generere gratis billeder ved hjælp af Dalle-mini ved at følge link .
Hvordan fungerer Dalle-mini?
Hovedideen bag Dalle-mini er kraften i transformatorer, som er neurale netværk. De kan lære langtrækkende afhængigheder og komplekse mønstre i sekventielle data, såsom tekst eller billeder.
Transformere består af to hoveddele: en koder og en dekoder. Den første del tager et input (en tekstbeskrivelse) og ændrer det til skjulte vektorer. Derefter tager dekoderen det og genererer et output (et billede), der er relevant for inputtet.
Hvad er forskellen mellem Dalle-mini og DALL-E?
Dalle-mini og DALL-E bruger en delt encoder-dekoder-arkitektur til både tekst og billeder. De kan indkode og afkode begge modaliteter ved hjælp af det samme netværk. Dette giver dem mulighed for at lære et fælles latent rum, der fanger det semantiske forhold mellem tekst og billeder. Derefter gør det dem i stand til at udføre cross-modal generation, såsom at skabe billeder fra tekst eller omvendt.
Hvordan virker Dalle-mini?
For at generere et billede ud fra en tekstbeskrivelse, tokeniserer Dalle-mini først teksten ved hjælp af en byte-pair encoding (BPE) algoritme, som opdeler teksten i underordsenheder baseret på deres frekvens og samtidige forekomst:
Lad os gå nærmere ind på Dalle-minis interne arbejde:
Internt arbejde i Dalle-mini
Lad os antage, at ordet ' spiller ' kan opdeles i ' pla ' og ' ying '. Tokens bliver derefter kortlagt til numeriske ID'er ved hjælp af et ordforråd på 8192 tokens. ID'erne føres ind i indkoderen og producerer en latent repræsentation af størrelsen 256 x 64:
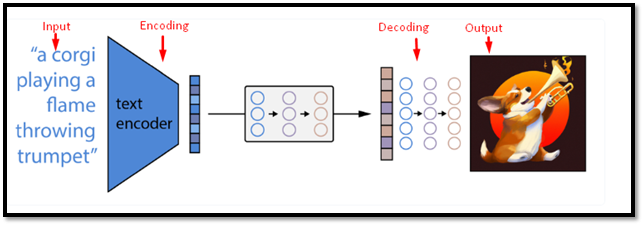
Dekoderen tager derefter den latente repræsentation og genererer et billede med størrelsen 256 x 256 pixels. Dekoderen bruger en autoregressiv proces, hvilket betyder, at den genererer hver pixel én efter én, betinget af de foregående pixels og den latente repræsentation.
Hvordan genererer man billede fra tekstbeskrivelse ved hjælp af Dalle-mini?
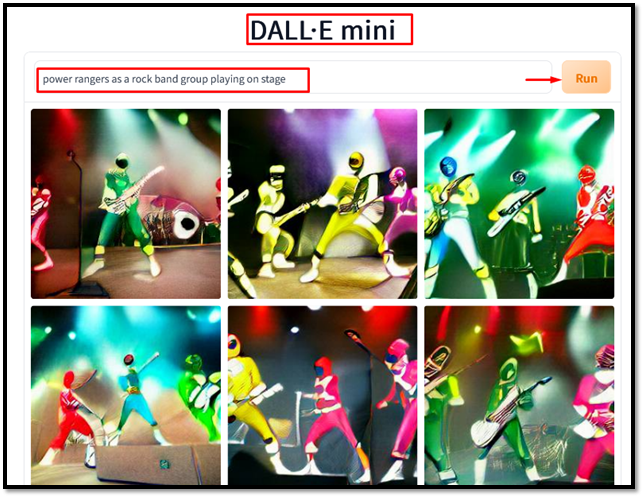
For at generere en tekstbeskrivelse fra et billede ved hjælp af Dalle-mini skal du indtaste teksten i promptvinduet. Skriv for eksempel ' Et maleri af tilfældige blomster ' i prompten og tryk på ' Løb ” knap:
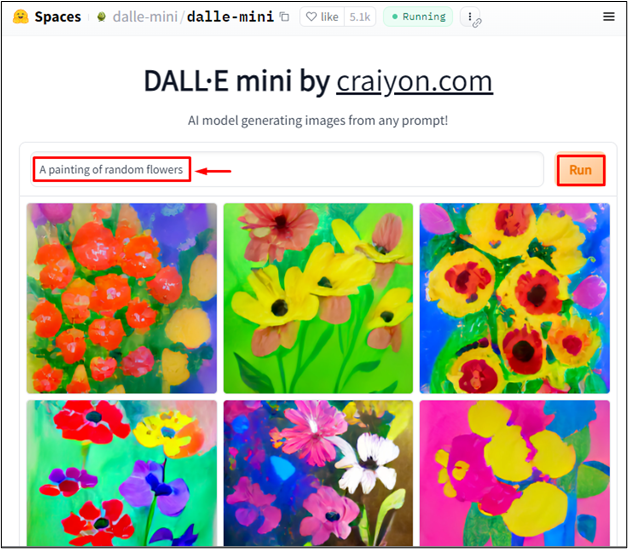
Outputtet viser, at Dalle-mini har genereret relevante billeder i henhold til inputteksten.
Konklusion
Dalle-mini er en bemærkelsesværdig model, der demonstrerer potentialet i transformere til cross-modal generation. De kan skabe realistiske og mangfoldige billeder ud fra naturlige sprogbeskrivelser, samt sammenhængende og relevante tekster fra billeder. De kan også håndtere komplekse kompositioner, såsom at kombinere flere objekter eller attributter i ét billede eller en tekst. Denne artikel har forklaret Dalle-mini og dens funktion i detaljer.