Elasticsearch er en robust, vellidt løsning til at gemme omfangsrige, ustrukturerede og semi-strukturelle data. Det er udelukkende en NoSQL-database og bruger en helt anden tilgang til at gemme, administrere og hente data. Det gemmer data i et dokument i JSON-format og bruger hvile-API'er til at udføre forskellige operationer på lagrede data.
I denne blog vil vi demonstrere:
- Hvordan fungerer Elasticsearch til at gemme og søge data?
- Hvad er Elasticsearch-dokumenter?
- Hvordan gemmer man data i et Elasticsearch-dokument?
Hvordan fungerer Elasticsearch til at gemme og søge data?
Elasticsearch-hovedkomponenterne eller -hierarkiet, der bruges til at gemme data, er angivet nedenfor:
- Dokument: Dokumentet er hoveddelen af Elasticsearch, der gemmer data i JSON-format. Synes godt om
- Indeks: Indekser omtales som indekser. Det er en samling af dokumenter. Ligesom i SQL omtales det som en database.
- Inverterede indekser: Det understøtter meget hurtig fuldtekstsøgning. Det gemmer ordet som et indeks og navnet på dokumentet som reference.
Hvad er Elasticsearch-dokumenter?
Elasticsearch-dokumentet er en lagerenhed af data i JSON-format. Ligesom i relationelle databaser kan dokumentet omtales som en tabel eller en række af en database, der er gemt i et eller andet indeks. Indekset kan have flere dokumenter og omtales som en database, der har flere tabeller. Det gemmer normalt en kompleks datastruktur og steriliserer dataene i JSON-format.
Derudover kan hvert dokument indeholde flere felter, som er ' nøgle:værdi ” parrer for at gemme dataene, ligesom en tabel har flere kolonner eller felter i en relationsdatabase. Derefter formodes disse nøgleværdi-par at blive indekseret på en måde, der bestemmer dokumenttilknytningen. Kortlægningen definerer derefter dokumentets datatype i henhold til feltdataene såsom tekst, flydende, geopunkt, tid og mange flere.
Elasticsearch har aldrig bundet os til at foruddefinere indeksfeltstrukturen, og dokumenterne kan have forskellig feltstruktur i et indeks. Men hvis kortlægningen af feltet er defineret for en specifik datatype, så skal alle Elasticsearch-dokumenter i et indeks følge den samme kortlægningstype. For at se, hvordan dokumentet fungerer for at gemme data i Elasticsearch, skal du gå gennem næste afsnit.
Hvordan gemmer man data i et Elasticsearch-dokument?
For at gemme data i Elasticsearch skal brugeren først oprette et indeks. Angiv derefter felterne for at gemme dataene i Elasticsearch-dokumentet. For demonstrationen skal du gennemgå de anførte trin.
Trin 1: Start Elasticsearch
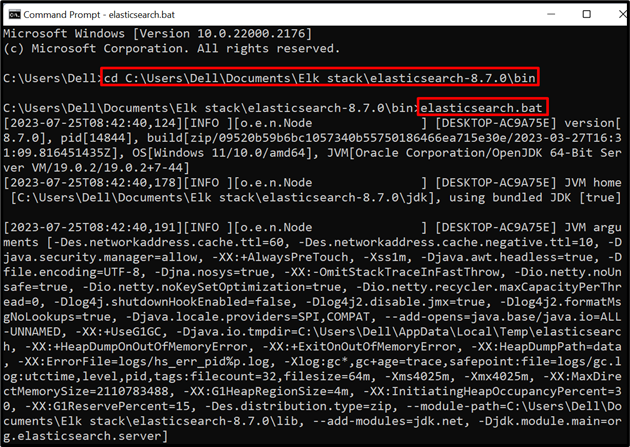
For at køre Elasticsearch-databasen eller -motoren på systemet skal du starte systemterminalen, såsom kommandoprompt. Besøg derefter ' beholder '-mappe af Elasticsearch gennem ' cd kommando:
cd C:\Users\Dell\Documents\Elk stack\elasticsearch-8.7.0\bin
Derefter skal du udføre batchfilen af Elasticsearch for at køre databasen på systemet:
elasticsearch.bat
Trin 2: Start Kibana
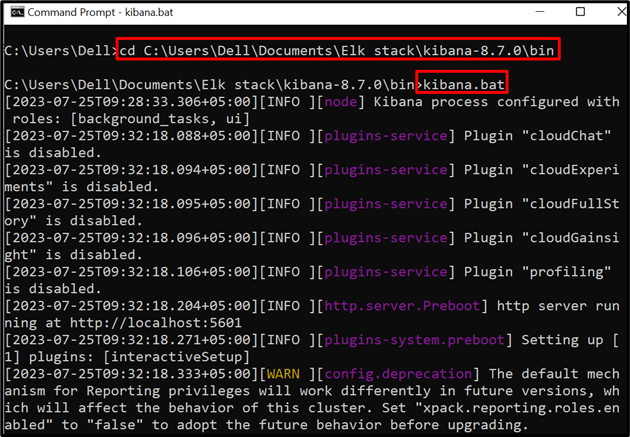
Udfør derefter Kibana på systemet. For at gøre det, besøg dens ' beholder mappe fra kommandoprompt:
cd C:\Users\Dell\Documents\Elk stack\kibana-8.7.0\bin
Kør derefter nedenstående kommando for at begynde at udføre Kibana:
kibana.bat
Bemærk: Hvis du ikke har installeret og opsat Elasticsearch og Kibana på systemet, skal du navigere til vores indlæg og tjekke trin-for-trin-proceduren for at installere dem på systemet.
For Elasticsearch, besøg vores ' Installer og opsæt Elasticsearch med .zip på Windows ' artikel. For at konfigurere Kibana på Windows skal du følge ' Konfigurer Kibana til Elasticsearch ' artikel.
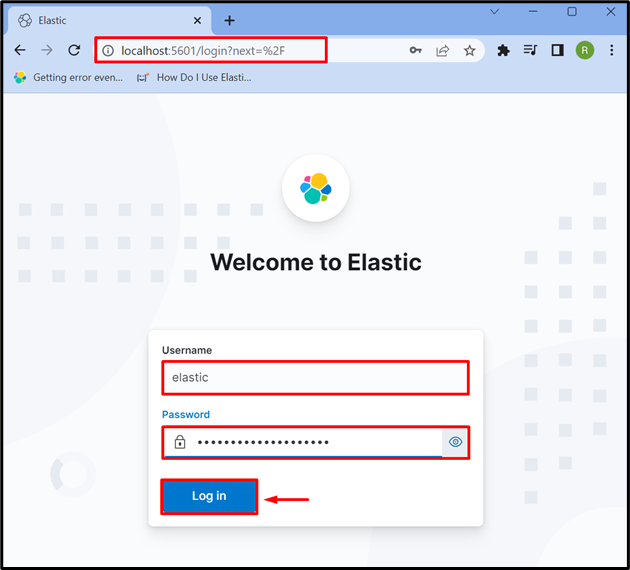
Trin 3: Log ind på Kibana
Når du har startet Kibana på systemet, skal du navigere til standardadressen for Kibana ' lokal vært: 5601 ” i browseren, og angiv loginoplysningerne for Elasticsearch som f.eks. elastik ” bruger og adgangskode. Tryk derefter på ' Log på ” knap:
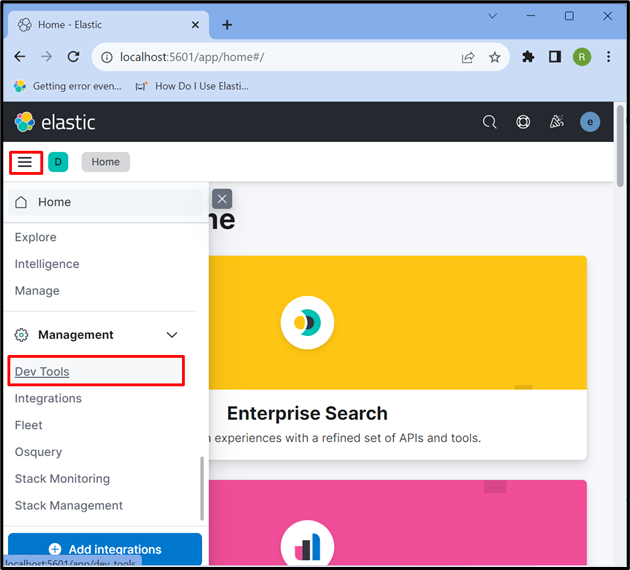
Trin 4: Åbn Kibana 'Dev Tool'
Derefter skal du klikke på ' Tre vandrette stænger ' ikon og åbn Kibana ' Udviklerværktøj ' for at bruge API'er til at gemme, hente og opdatere dataene:
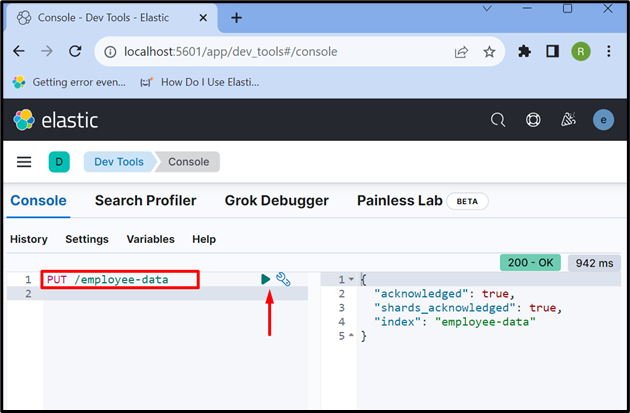
Trin 5: Opret indeks
Opret nu et nyt indeks ved hjælp af ' PUT /
Outputtet viser, at ' medarbejder-data ” indeks er oprettet:
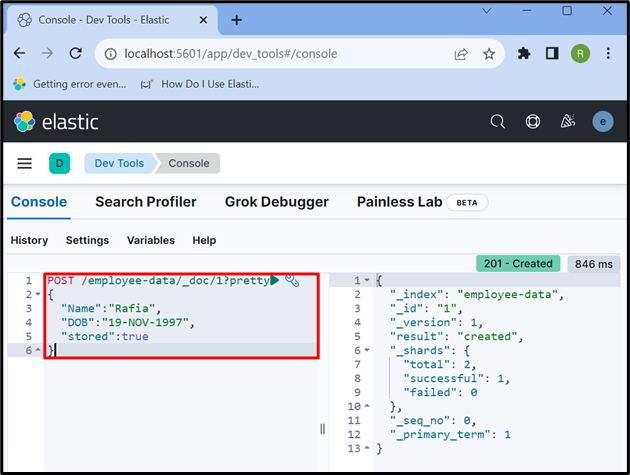
Trin 6: Indsæt data i dokumentet
Brug nu ' STOLPE ” API til at gemme dataene i indekset. I nedenstående anmodning, ' medarbejder-data ' er et indeks over Elasticsearch, ' _dok ' bruges til at gemme data i Elasticsearch-dokumentet, og ' 1 ' er id'et:
STOLPE / medarbejder-data / _dok / 1 ?smuk{
'Navn' : 'Raffia' ,
'DOB' : '19-NOV-1997' ,
'gemt' :rigtigt
}
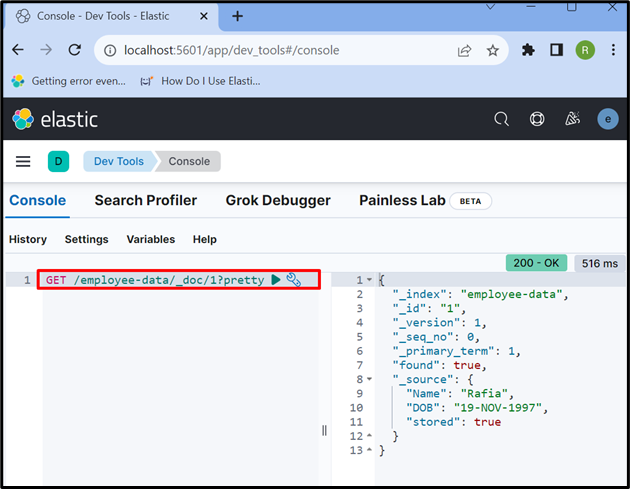
Trin 7: Hent data fra Elasticsearch-dokumentet
For at få adgang til data fra indekset eller Elasticsearch-dokumentet skal du bruge ' FÅ ' API som brugt nedenfor:
FÅ / medarbejder-data / _dok / 1 ?smuk
Outputtet viser, at vi med succes har udtrukket dataene fra Elasticsearch-dokumentet med id ' 1 ”:
Det handler om Elasticsearch-dokumentet.
Konklusion
Elasticsearch-dokumentet bruges normalt til at gemme data i JSON-format. Ligesom i relationelle databaser kan dokumentet omtales som en række, der er gemt i et eller andet indeks. Disse indekser kan have flere dokumenter ligesom databaser har forskellige tabeller. Disse dokumenter indeholder flere felter, som er ' nøgle:værdi ” parrer for at gemme dataene. Denne artikel har demonstreret, hvad der er Elasticsearch-dokumenter, og hvordan de fungerer i Elasticsearch.