Denne vejledning vil illustrere processen med at bruge enhedshukommelse i LangChain.
Hvordan bruger man Entity Memory i LangChain?
Enheden bruges til at opbevare nøglefaktaerne i hukommelsen for at udtrække, når det bliver spurgt af mennesket ved hjælp af forespørgsler/prompter. For at lære processen med at bruge enhedshukommelsen i LangChain skal du blot besøge følgende guide:
Trin 1: Installer moduler
Først skal du installere LangChain-modulet ved hjælp af pip-kommandoen for at få dets afhængigheder:
pip installer langkæde
Installer derefter OpenAI-modulet for at få dets biblioteker til at bygge LLM'er og chatmodeller:
pip installer openai
Konfigurer OpenAI-miljøet ved hjælp af API-nøglen, som kan udtrækkes fra OpenAI-kontoen:
importere du
importere getpass
du . rundt regnet [ 'OPENAI_API_KEY' ] = getpass . getpass ( 'OpenAI API-nøgle:' )
Trin 2: Brug af enhedshukommelse
For at bruge enhedshukommelsen skal du importere de nødvendige biblioteker til at bygge LLM'et ved hjælp af OpenAI()-metoden:
fra langkæde. llms importere OpenAIfra langkæde. hukommelse importere ConversationEntityMemory
llm = OpenAI ( temperatur = 0 )
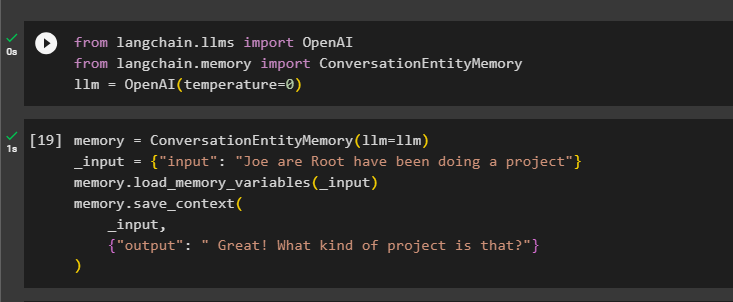
Derefter skal du definere hukommelse variabel ved hjælp af metoden ConversationEntityMemory() til at træne modellen ved hjælp af input- og outputvariablerne:
hukommelse = ConversationEntityMemory ( llm = llm )_input = { 'input' : 'Joe are Root har lavet et projekt' }
hukommelse. load_memory_variables ( _input )
hukommelse. gem_kontekst (
_input ,
{ 'produktion' : 'Fantastisk! Hvad er det for et projekt?' }
)
Test nu hukommelsen ved at bruge forespørgslen/prompten i input variabel ved at kalde load_memory_variables() metoden:
hukommelse. load_memory_variables ( { 'input' : 'hvem er root' } ) 
Giv nu nogle flere oplysninger, så modellen kan tilføje et par flere entiteter i hukommelsen:
hukommelse = ConversationEntityMemory ( llm = llm , return_beskeder = Rigtigt )_input = { 'input' : 'Joe are Root har lavet et projekt' }
hukommelse. load_memory_variables ( _input )
hukommelse. gem_kontekst (
_input ,
{ 'produktion' : 'Fantastisk! Hvad er det for et projekt' }
)
Udfør følgende kode for at få output ved hjælp af de entiteter, der er gemt i hukommelsen. Det er muligt gennem input indeholdende prompten:
hukommelse. load_memory_variables ( { 'input' : 'hvem er Joe' } ) 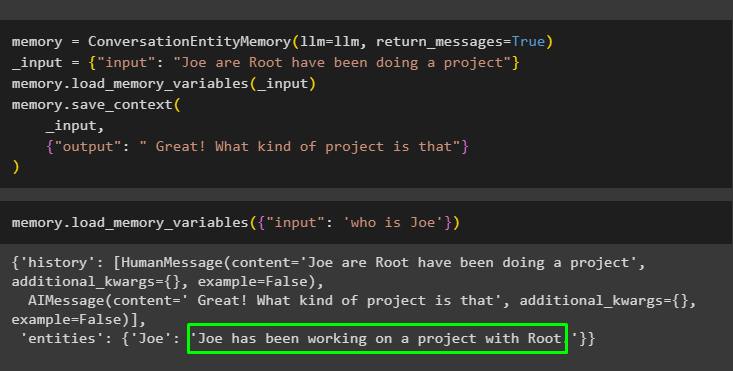
Trin 3: Brug af enhedshukommelse i en kæde
For at bruge enhedshukommelsen efter at have bygget en kæde, skal du blot importere de nødvendige biblioteker ved hjælp af følgende kodeblok:
fra langkæde. kæder importere Samtalekædefra langkæde. hukommelse importere ConversationEntityMemory
fra langkæde. hukommelse . hurtig importere ENTITY_MEMORY_CONVERSATION_TEMPLATE
fra pydantisk importere Basismodel
fra skrive importere Liste , Dict , Nogen
Byg samtalemodellen ved hjælp af metoden ConversationChain() ved hjælp af argumenter som llm:
samtale = Samtalekæde (llm = llm ,
ordrig = Rigtigt ,
hurtig = ENTITY_MEMORY_CONVERSATION_TEMPLATE ,
hukommelse = ConversationEntityMemory ( llm = llm )
)
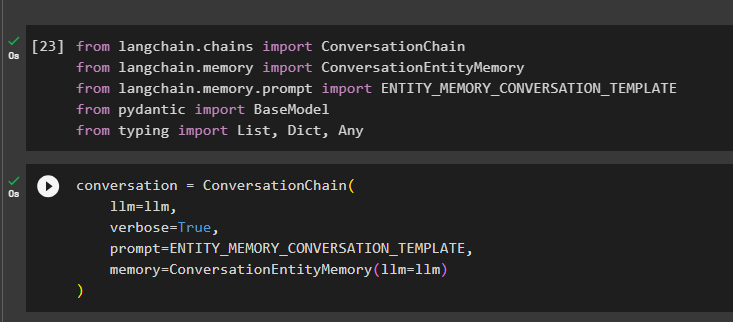
Kald metoden conversation.predict() med input initialiseret med prompten eller forespørgslen:
samtale. forudsige ( input = 'Joe are Root har lavet et projekt' ) 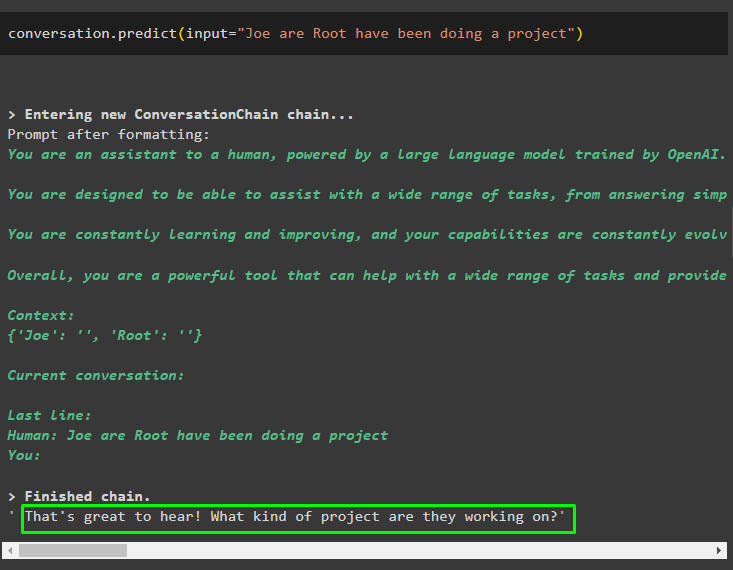
Få nu det separate output for hver enhed, der beskriver oplysningerne om det:
samtale. hukommelse . enhedsbutik . butik 
Brug outputtet fra modellen til at give input, så modellen kan gemme flere oplysninger om disse entiteter:
samtale. forudsige ( input = 'De forsøger at tilføje mere komplekse hukommelsesstrukturer til Langchain' ) 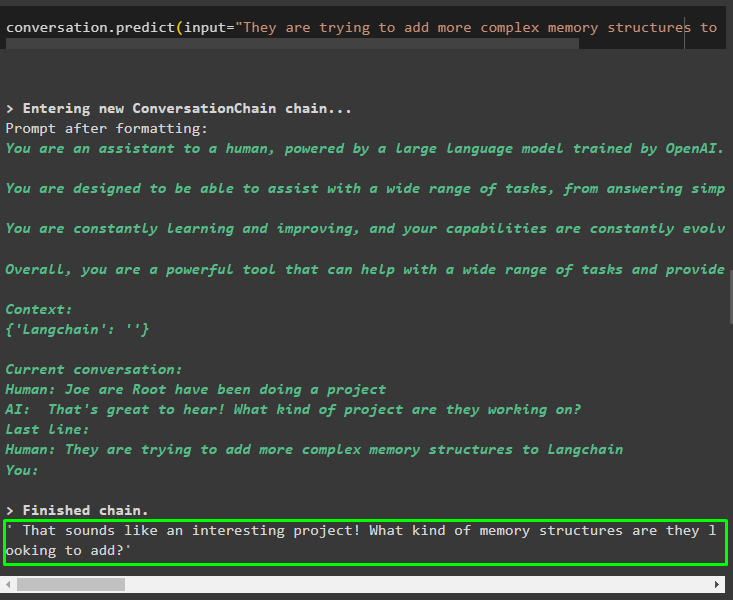
Efter at have givet den information, der bliver gemt i hukommelsen, skal du blot stille spørgsmålet for at udtrække den specifikke information om enheder:
samtale. forudsige ( input = 'Hvad ved du om Joe og Root' ) 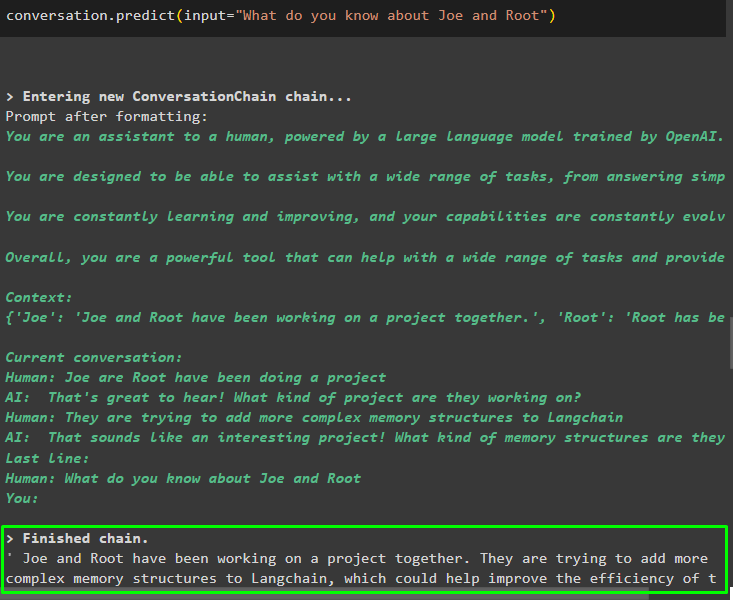
Trin 4: Test af Memory Store
Brugeren kan inspicere hukommelseslagrene direkte for at få oplysningerne gemt i dem ved hjælp af følgende kode:
fra Print importere PrintPrint ( samtale. hukommelse . enhedsbutik . butik )
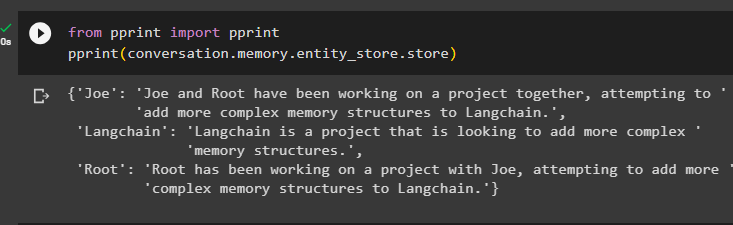
Angiv flere oplysninger, der skal gemmes i hukommelsen, da flere oplysninger giver mere nøjagtige resultater:
samtale. forudsige ( input = 'Root har grundlagt en virksomhed kaldet HJRS' ) 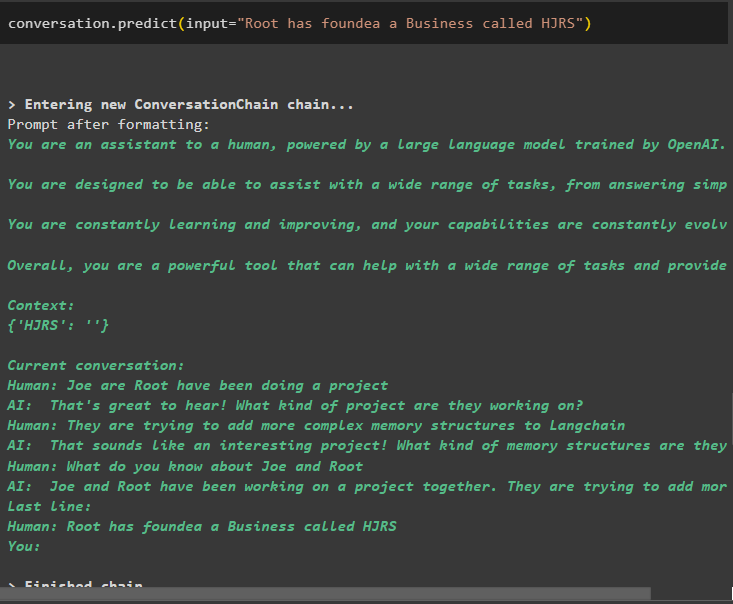
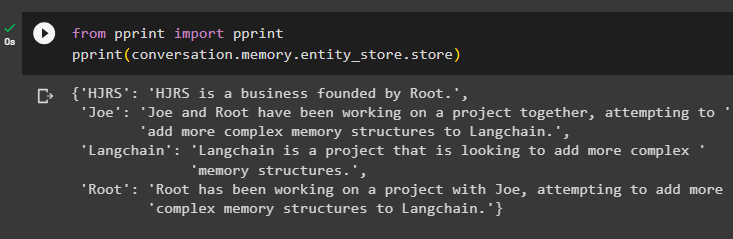
Udtræk oplysninger fra hukommelseslagret efter tilføjelse af flere oplysninger om enhederne:
fra Print importere PrintPrint ( samtale. hukommelse . enhedsbutik . butik )
Hukommelsen har information om flere entiteter som HJRS, Joe, LangChain og Root:
Udtræk nu information om en specifik enhed ved hjælp af forespørgslen eller prompten, der er defineret i inputvariablen:
samtale. forudsige ( input = 'Hvad ved du om Root' ) 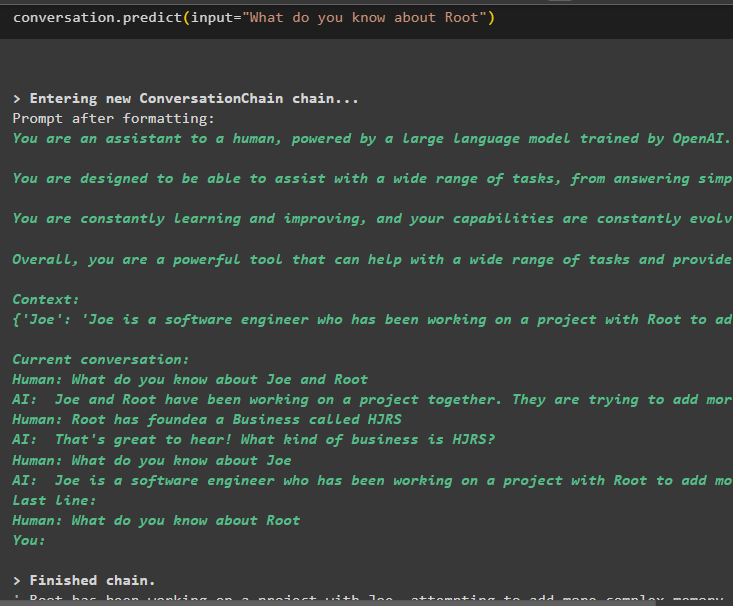
Det handler om at bruge entitetshukommelsen ved hjælp af LangChain-rammerne.
Konklusion
For at bruge enhedshukommelsen i LangChain skal du blot installere de nødvendige moduler for at importere biblioteker, der er nødvendige for at bygge modeller efter opsætning af OpenAI-miljøet. Byg derefter LLM-modellen og gem entiteter i hukommelsen ved at give oplysninger om entiteterne. Brugeren kan også udtrække information ved hjælp af disse entiteter og bygge disse minder i kæderne med omrørt information om entiteter. Dette indlæg har uddybet processen med at bruge enhedshukommelsen i LangChain.