Dette indlæg illustrerer metoden til brug af output-parser-funktioner og klasser gennem LangChain-rammeværket.
Hvordan bruger man outputparseren gennem LangChain?
Output-parserne er de output og klasser, der kan hjælpe med at få det strukturerede output fra modellen. For at lære processen med at bruge outputparserne i LangChain skal du blot gå gennem de anførte trin:
Trin 1: Installer moduler
Start først processen med at bruge outputparserne ved at installere LangChain-modulet med dets afhængigheder for at gå gennem processen:
pip installere langkæde
Installer derefter OpenAI-modulet for at bruge dets biblioteker som OpenAI og ChatOpenAI:
pip installere openai
Indstil nu miljø for OpenAI ved hjælp af API-nøglen fra OpenAI-kontoen:
import os
importere getpass
os.miljø [ 'OPENAI_API_KEY' ] = getpass.getpass ( 'OpenAI API-nøgle:' )
Trin 2: Importer biblioteker
Det næste trin er at importere biblioteker fra LangChain for at bruge outputparserne i rammen:
fra langchain.prompts importer HumanMessagePromptTemplate
fra pydantic import Field
fra langchain.prompts importerer ChatPromptTemplate
fra langchain.output_parsers importer PydanticOutputParser
fra pydantic import BaseModel
fra pydantic import validator
fra langchain.chat_models importerer ChatOpenAI
fra langchain.llms importerer OpenAI
fra at skrive importliste
Trin 3: Opbygning af datastruktur
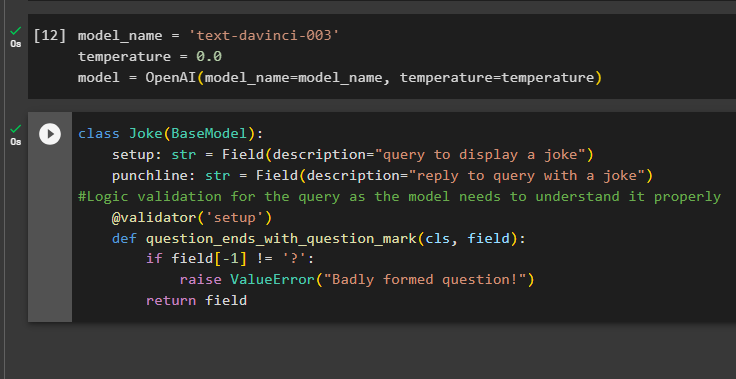
Opbygning af outputstrukturen er den vitale anvendelse af outputparserne i store sprogmodeller. Før du kommer til modellernes datastruktur, er det nødvendigt at definere navnet på den model, vi bruger for at få det strukturerede output fra outputparsere:
temperatur = 0,0
model = OpenAI ( model_name =model_navn, temperatur = temperatur )
Brug nu Joke-klassen, der indeholder BaseModel, til at konfigurere strukturen af output for at hente vittigheden fra modellen. Derefter kan brugeren nemt tilføje tilpasset valideringslogik med pydantic-klassen, som kan bede brugeren om at stille en bedre udformet forespørgsel/prompt:
klasse Joke ( Basismodel ) :opsætning: str = Felt ( beskrivelse = 'forespørgsel om at vise en vittighed' )
punchline: str = Felt ( beskrivelse = 'svar på forespørgsel med en vittighed' )
#Logisk validering for forespørgslen, da modellen skal forstå den korrekt
@ validator ( 'Opsætning' )
def question_ends_with_question_mark ( cls, felt ) :
hvis Mark [ - 1 ] ! = '?' :
hæve ValueError ( 'Dårligt formuleret spørgsmål!' )
Vend tilbage Mark
Trin 4: Indstilling af promptskabelon
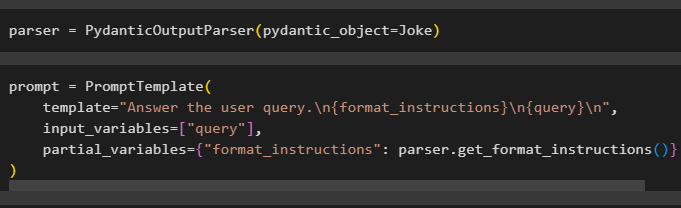
Konfigurer parservariablen, der indeholder PydanticOutputParser()-metoden, der indeholder dens parametre:
Efter at have konfigureret parseren skal du blot definere promptvariablen ved hjælp af PromptTemplate()-metoden med strukturen af forespørgslen/prompten:
prompt = PromptTemplate (skabelon = 'Besvar brugerforespørgslen. \n {format_instructions} \n {forespørgsel} \n ' ,
input_variables = [ 'forespørgsel' ] ,
partielle_variabler = { 'format_instructions' : parser.get_format_instructions ( ) }
)
Trin 5: Test outputparseren
Når du har konfigureret alle kravene, skal du oprette en variabel, der er tildelt ved hjælp af en forespørgsel, og derefter kalde format_prompt()-metoden:
_input = prompt.format_prompt ( forespørgsel =joke_forespørgsel )
Kald nu model()-funktionen for at definere outputvariablen:
output = model ( _input.to_string ( ) )Fuldfør testprocessen ved at kalde parser()-metoden med outputvariablen som parameter:
parser.parse ( produktion ) 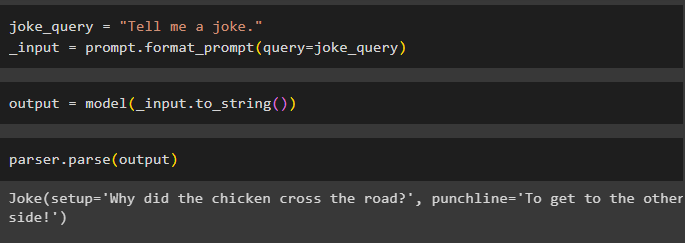
Det handler om processen med at bruge output-parseren i LangChain.
Konklusion
For at bruge output-parseren i LangChain skal du installere modulerne og opsætte OpenAI-miljøet ved hjælp af dens API-nøgle. Derefter skal du definere modellen og derefter konfigurere datastrukturen for output med logisk validering af forespørgslen fra brugeren. Når datastrukturen er konfigureret, skal du blot indstille promptskabelonen og derefter teste outputparseren for at få resultatet fra modellen. Denne guide har illustreret processen med at bruge output-parseren i LangChain-rammeværket.