Denne artikel giver sine brugere en dybere forståelse for implementering af Data Warehouse med AWS Redshift.
Hvad er AWS Redshift?
AWS Redshift giver sine brugere mulighed for at hente og manipulere dataene uden alle konfigurationer af en traditionel database. Den skalerer kapaciteten intelligent afhængigt af applikationens krav, giver hurtige og præcise svar og styres fuldt ud af AWS. AWS Redshift er meget udbredt til dets omfattende anvendelser af Big Data Analysing. Desuden følger den betal-som-du-brug-modellen og medfører ingen ekstra omkostninger, når lageret står stille:
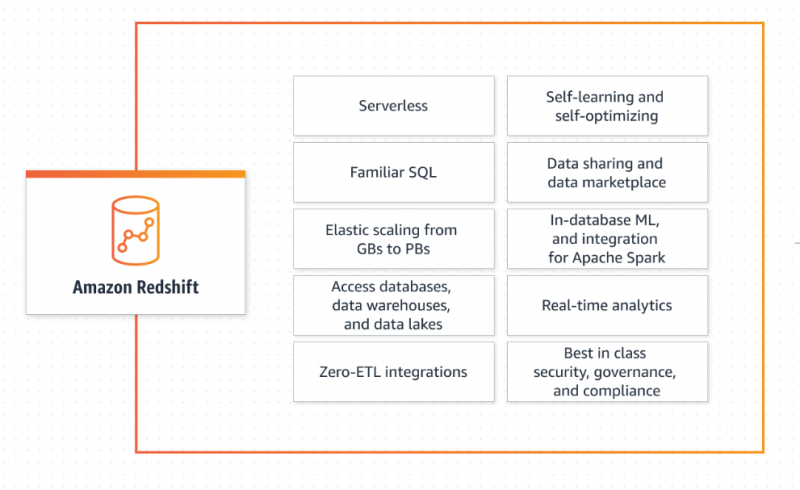
Lær mere om Redshift ved at henvise til denne artikel: 'Hvad er Amazon Redshift-datatyperne' :
Hvordan implementerer man data warehousing med Amazon Redshift?
Amazon Redshift bruger Standard Query Language (SQL) på tværs af forskellige varehuse til at udføre forespørgsler. Det er trættende at udtrække maksimale værdier, mens du overvåger omkostningerne ved manuel opsætning af et datavarehus. Derfor fremskynder AWS Redshift præcist og intelligent din datarelaterede forretningsopgave og hjælper dig med at fremskynde din tid til at få indsigt i data på en hurtig, nem, pålidelig og sikker måde. Der er mange fordele ved at implementere Data Warehousing med Amazon Redshift:
- Datakryptering
- Intelligent optimering
- Omkostningsoptimal
- Automatiser gentagne opgaver
- Automatisk skaleringskapacitet
- Support til forskellige AWS-ressourcer
Nedenfor er nogle trin, hvor vi kan implementere Data Warehousing med Amazon Redshift:
Trin 1: Opret en IAM-rolle
Det første skridt i implementeringen af et Data Warehouse på AWS rødforskydning begynder med at skabe en IAM-rolle. Til dette formål skal du søge og vælge IAM-rollen på AWS Management Console :
Klik på 'Roller' mulighed fra sidebjælken i IAM-rollen:
Klik på 'Skab rolle' knap næste:
I den Pålidelig enhedstype sektionen skal du klikke på “AWS service” mens vi skaber denne IAM-rolle for Redshift:
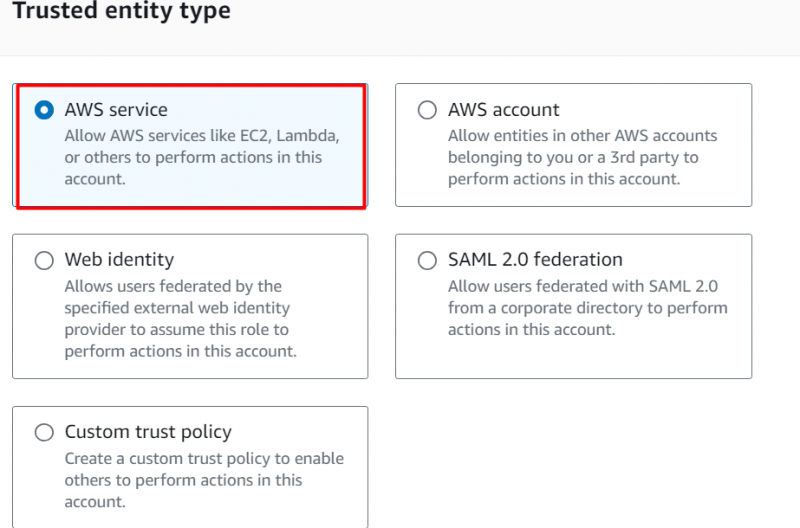
I den Use case afsnit , Vælg 'Rødskift' i det fremhævede felt, og fortsæt med at vælge den følgende fremhævede mulighed. Klik på 'Næste' knap bagefter:
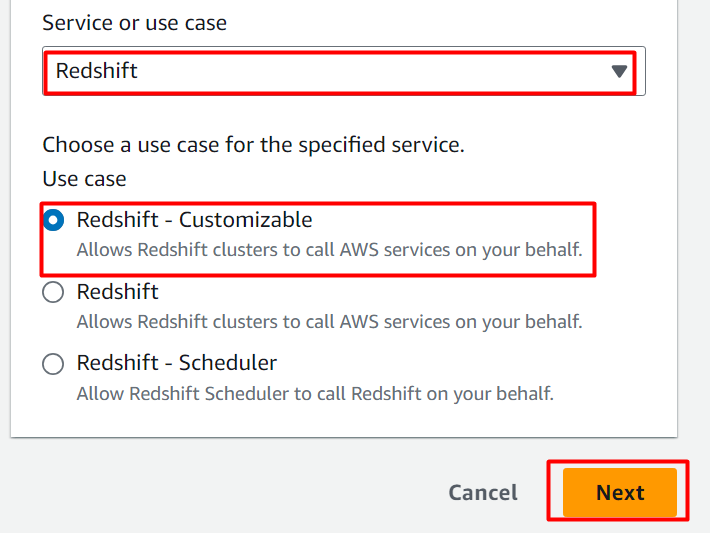
I den Tilladelsespolitik afsnit , søg og vælg 'AmazonS3ReadOnly Access' mulighed. Og klik derefter på 'Næste' knap bagefter:
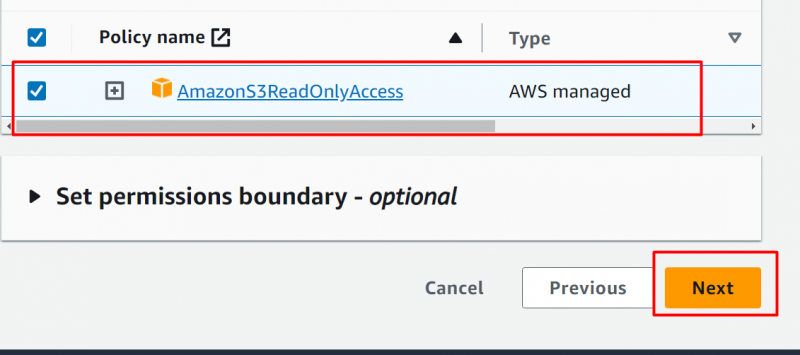
I den Rolledetaljer afsnit , angiv navnet på rollen:
At beholde resten af indstillinger som standard, klik på 'Skab rolle' knap i bunden af grænsefladen:
Rollen har været succesfuldt oprettet. Klik på 'Se rolle' knap:
I den Se rolle afsnit, kopiere RNA og gem det i Notesblok til fremtidig brug:
Trin 2: Opret Redshift Cluster
På AWS Management Console skal du søge og derefter vælge 'Rødskift' service:
Rul ned 'Rødskift' hovedkonsollen og klik på 'Opret klynge' knap:
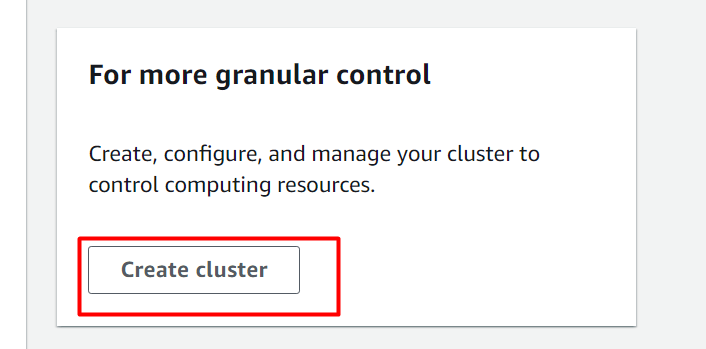
Dette vil navigere brugeren til 'Opret klynge' interface. Her på denne grænseflade skal du angive et navn til klyngen og vælge 'dc.2 stor' for klyngetypen:
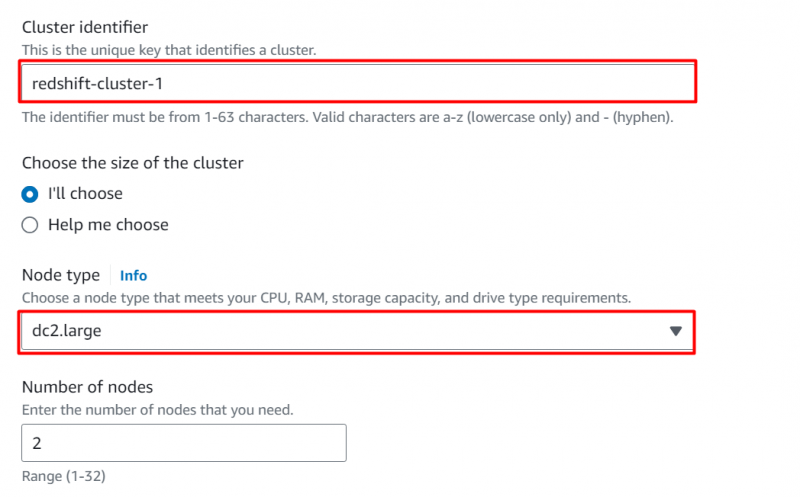
I den Database konfigurationer afsnit, give en brugernavn og adgangskode for klyngen:
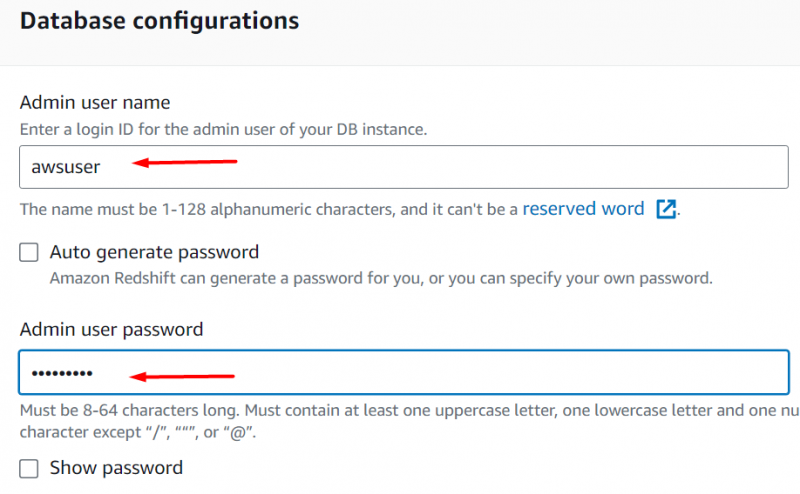
Rul ned til IAM roller afsnit. Vi vil vedhæfte IAM-rollen her, som vi oprettede tidligere i denne vejledning. Til dette formål skal du klikke på 'Associeret IAM-rolle' knap:
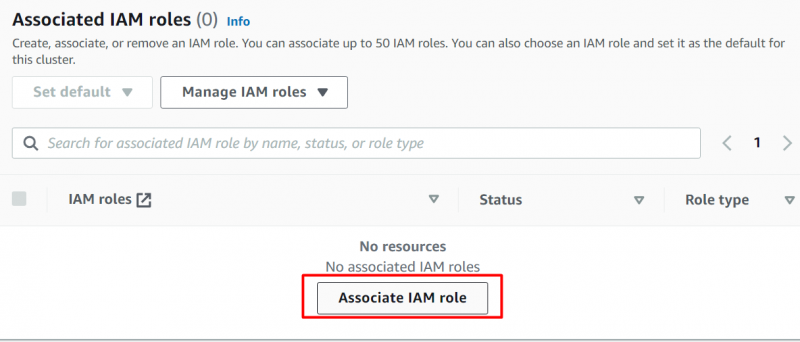
I dette afsnit har vi valgt den oprettede rolle og klikket på 'Associate IAM-roller' knap for at vedhæfte rollen:
Behold standardindstillingerne, klik på 'Opret klynge' knap i bunden af grænsefladen:
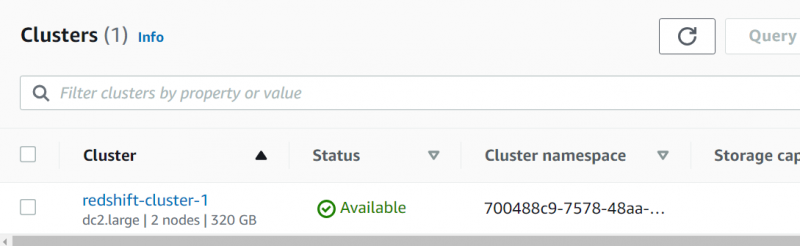
Det vil tage noget tid, før klyngen er tilgængelig. Klik på klyngens navn fra RDS Dashboard, efter at status vises 'Aktiv':
Trin 3: Tilføj tilladelser
Få adgang til IAM service fra AWS Management Console til konfigurere en ny politik i root-brugerkontoen:
Fra IAM Dashboard, klik på 'Brugere' mulighed fra venstre sidebjælke:
Klik på Rollenavn der har administratoradgang til kontoen:
Tryk på 'Tilføj tilladelser' knap placeret på grænsefladen:
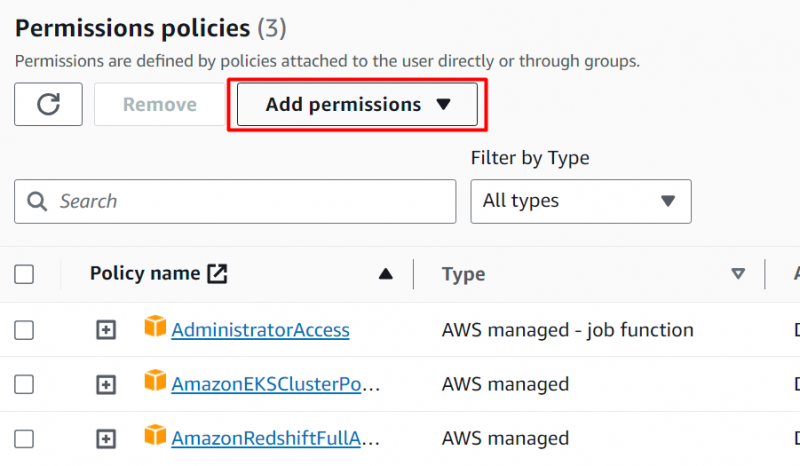
Klik på 'Vedhæft politikker direkte' mulighed under Tilladelsesmuligheder afsnit:
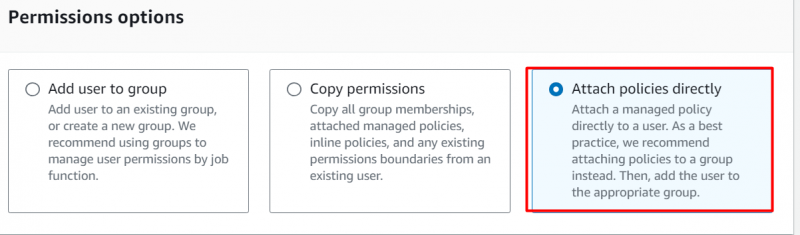
Tilføj følgende tilladelser til din konto:
- AmazonRedshiftQueryEditor
- AmazonRedshiftQueryEditorV2FullAccess
- AmazonRedshiftReadOnly Access
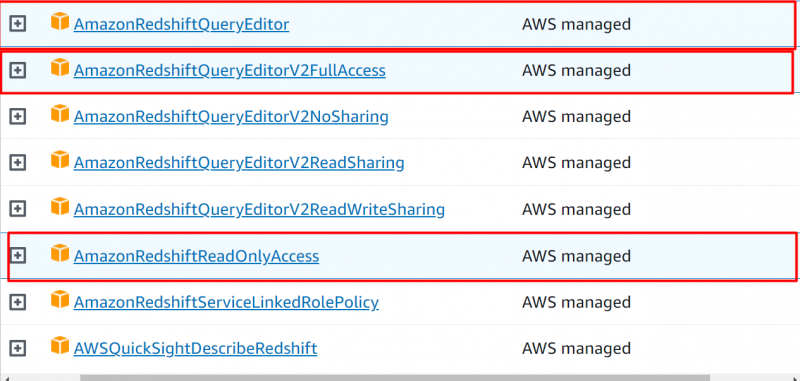
Når du har tilføjet følgende tilladelser, skal du klikke på 'Næste' knap:
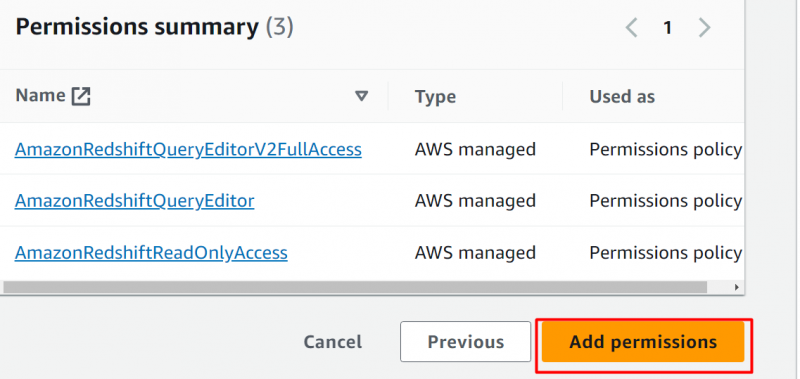
I den Oversigt over tilladelser sektionen skal du klikke på 'Tilføj tilladelser' knap:
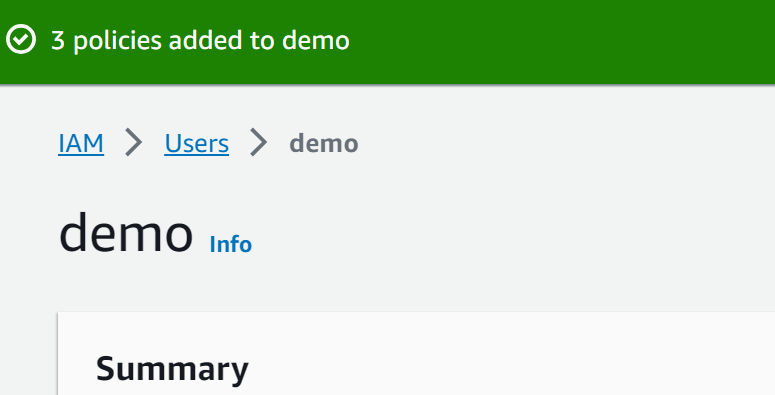
Her er tilladelserne konfigureret med succes:
Trin 4: Forespørgselseditor
På den AWS RDS Dashboard , klik på 'Forespørgselseditor v2' mulighed fra sidebjælken:
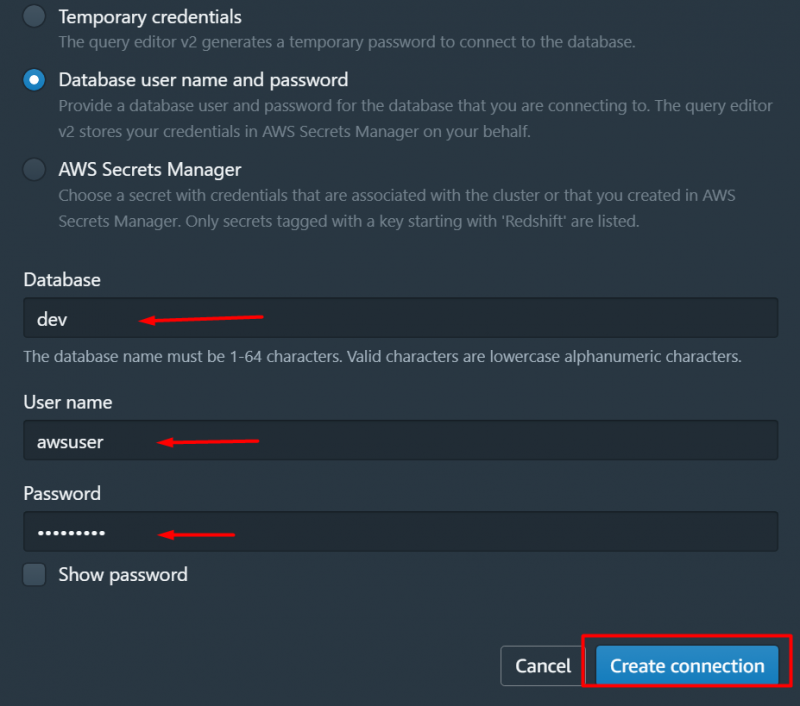
Dette vil vise følgende grænseflade. På denne grænseflade skal du vælge navnet på din klynge og angive følgende detaljer for forbindelsen. Når du har angivet detaljerne, skal du klikke på 'Opret forbindelse' knap:
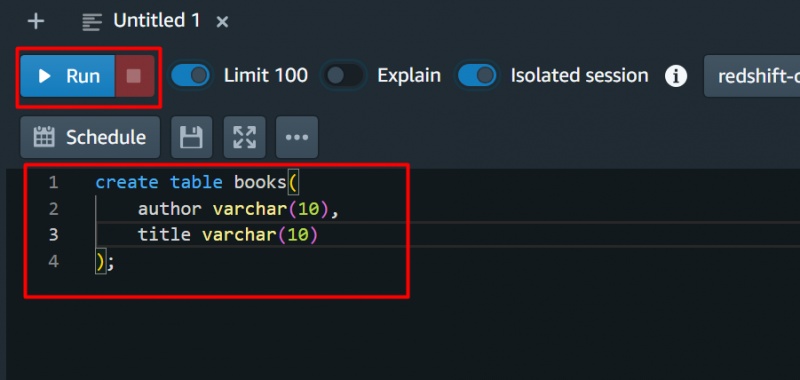
Til testformål vil vi give følgende forespørgsel og trykke på 'Løb' knap:
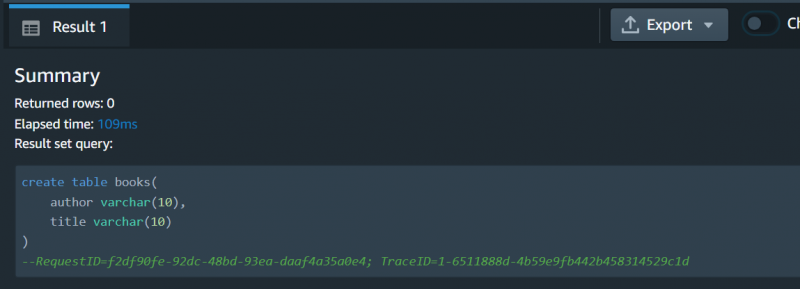
Forespørgslen er blevet udført succesfuldt:
Det er alt fra denne guide. Nu kan brugeren køre forskellige forespørgsler i denne konsol, f.eks. Opret, indsæt, slet, etc.
Konklusion
For at oprette Data Warehousing med Redshift skal du konfigurere en IAM-rolle og tilladelse med RDS-klyngen og klikke på ' Forespørgselsredaktør ' mulighed for at udføre forespørgsler. AWS Redshift er en cloud-baseret database, der følger syntaksen af SQL og udfører forespørgsler på store datasæt effektivt for høj ydeevne. Denne artikel giver instruktioner til implementering af data warehousing med Amazon Redshift.