Denne artikel giver instruktioner til implementering af Intelligent-Tiering for at optimere omkostningerne i S3-bøtten.
Hvad er Intelligent Tiering i S3 Bucket?
Data vokser eksponentielt over hele kloden. Nogle af disse data tilgås dagligt, mens resten kun kræves lejlighedsvis. Da S3 er en af AWS' mest populære tjenester til datalagring, har AWS introduceret en Storage Class kendt som “Intelligent niveaudeling” at skære i udgifterne til S3 på grund af datalagring. Lær mere om forskellige opbevaringsklasser af S3 spande ved at henvise til denne artikel: 'En oversigt over forskellige lagerklasser på S3' .
Intelligent-Tiering kan optimere S3-udgifterne ved at overvåge dataadgangsmønstrene. Denne funktion er effektiv nok til at bestemme, hvilke data der tilgås ofte eller lejlighedsvis. Baseret på disse mønstre identificerer den automatisk og placerer dem i det mest omkostningseffektive niveau uden driftsomkostninger eller reduktion af ydeevne.
Hvordan optimerer man datalagringsomkostninger i Amazon S3 med intelligent niveau?
Afhængigt af dataadgangsmønstrene vil de objekter, der sjældent tilgås, blive placeret i lavere omkostninger adgang tier til optimale omkostningsformål. Hvis objektet tilgås af brugeren, vil det automatisk og øjeblikkeligt blive flyttet tilbage til Hyppig adgangsniveau for tilgængelighed uden ekstra gebyrer:
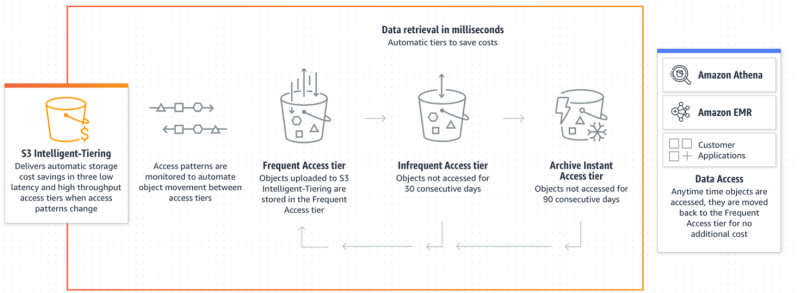
Intelligent Tiering er et gennemførligt og ideelt valg for brugere, når det kommer til at optimere omkostningerne til uforudsigelige dataadgangsmønstre. Følgende er de trin, hvor vi kan implementere Intelligent-Tiering Storage Class for omkostningseffektivitet:
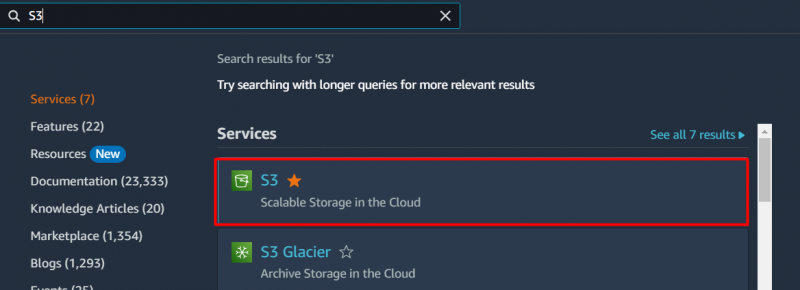
Trin 1: S3 Dashboard
For at opnå en omkostningsoptimal løsning til datalagring med S3-bøtten, søg i 'S3' tjeneste i AWS-søgelinjen og klik på den fra de viste resultater:
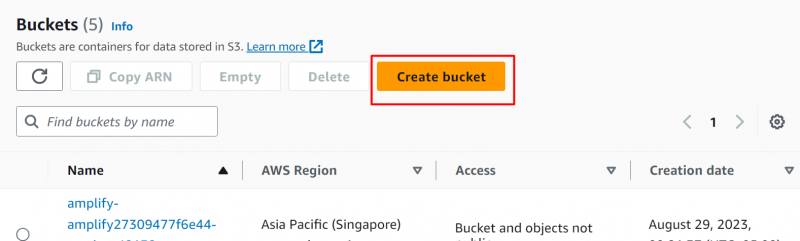
Trin 2: Opret spand
Klik på 'Opret spand' knappen på S3 konsol :
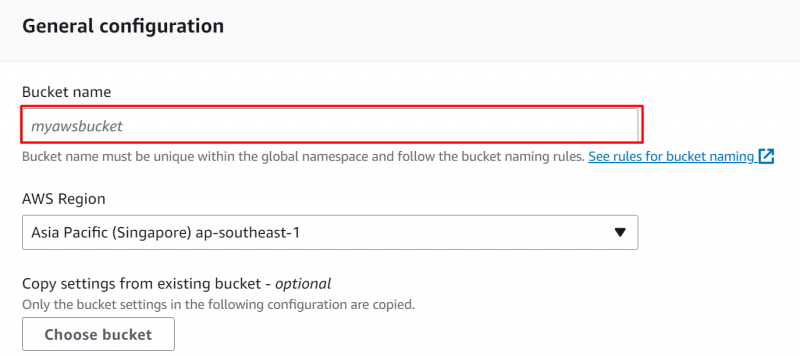
Trin 3: Generelle konfigurationer
Angiv en fra den viste grænseflade unik identifikator for S3 spanden i 'Generelle konfigurationer' afsnit:
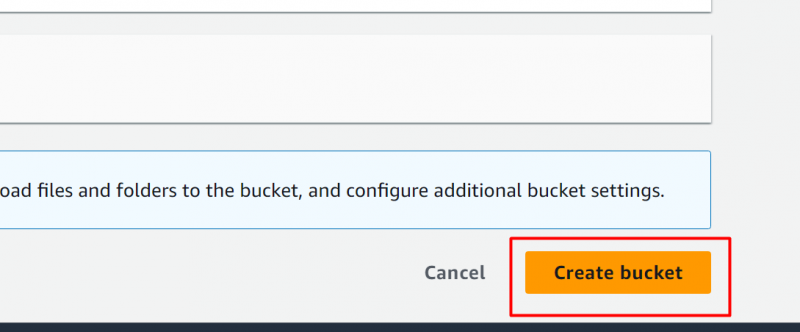
Trin 4: Tryk på knappen 'Opret spand'.
Ved at beholde standardindstillingerne skal du klikke på 'Opret spand' knap placeret i bunden af grænsefladen:
Bøtten er blevet oprettet. Dernæst uploader vi en fil til denne bøtte. Klik på bøttenavnet for at navigere til uploadfilgrænsefladen:
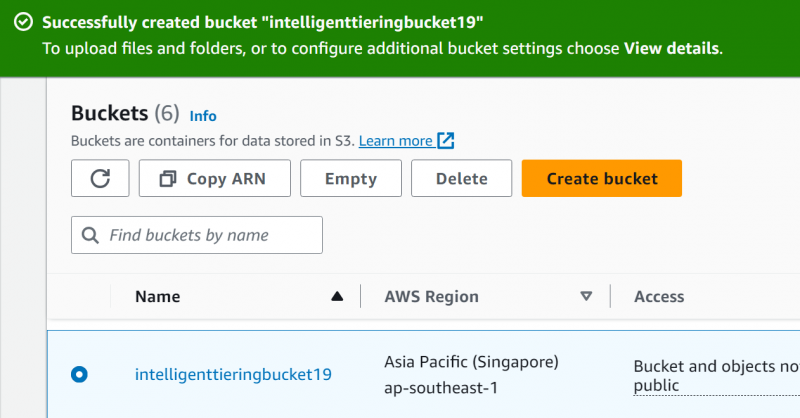
Trin 5: Upload filer
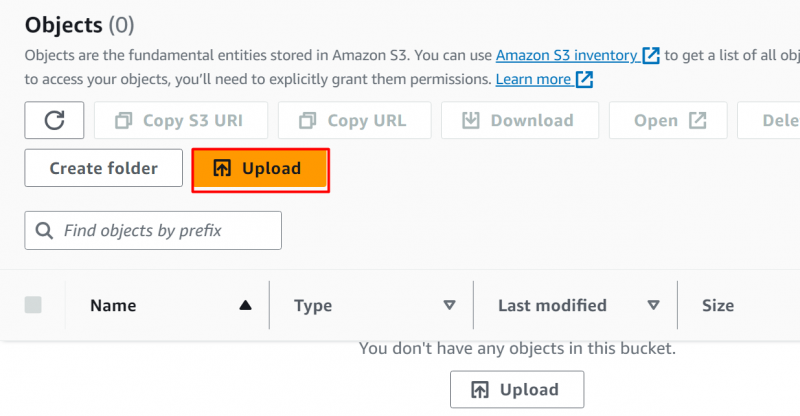
Klik på 'Upload' knap på den viste grænseflade:
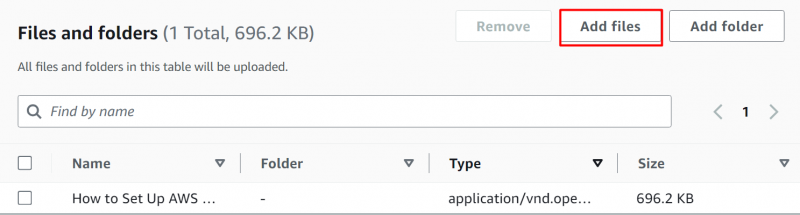
For at vælge filer skal du klikke på 'Tilføj filer' knappen og vælg derefter filerne/mapperne fra din enhed. Filen er blevet uploadet til S3-bøtten:
Naviger til 'Ejendomme' bloker og vælg ' Intelligent niveau” mulighed fra Opbevaringsklasse afsnit :
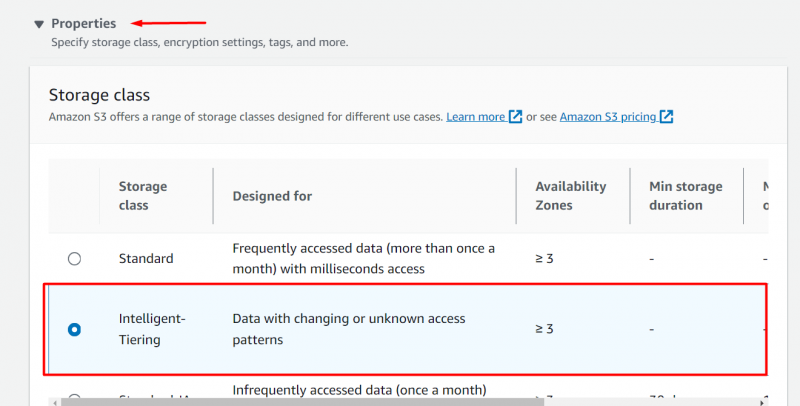
Ved at beholde resten af indstillinger uændrede , klik på 'Upload' knap placeret i bunden af grænsefladen:
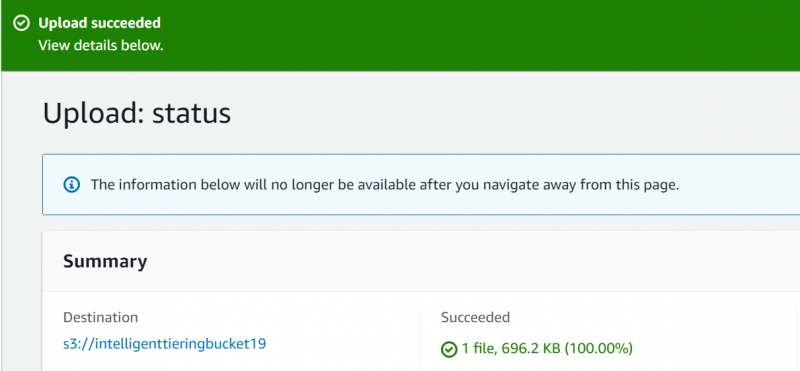
AWS vil vise en bekræftelsesmeddelelse hvilket indikerer, at filen er blevet uploadet:
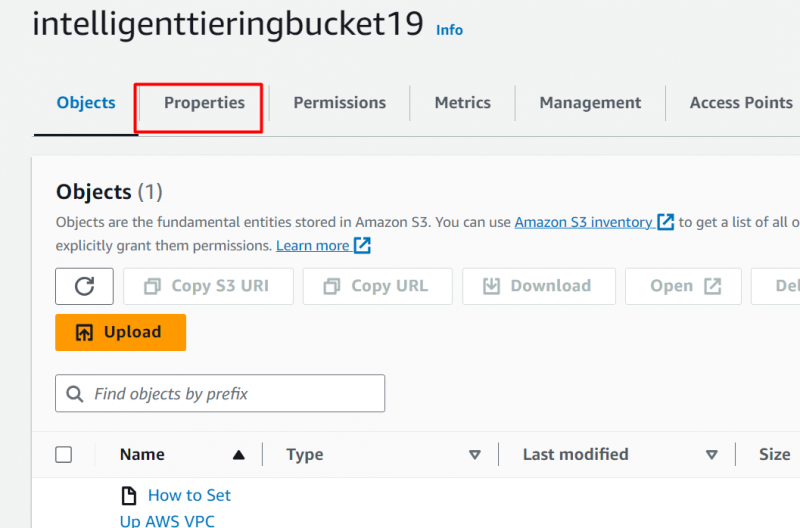
Trin 6: Tryk på fanen 'Egenskaber'.
Når filen er uploadet, skal du klikke på 'Ejendomme' fane:
Trin 7: Intelligent-Tiering-arkivkonfigurationer
Fra Ejendomme interface, rul ned til 'Intelligent-Tiering-arkivkonfigurationer' sektionen og klik på 'Opret konfigurationer' knap:
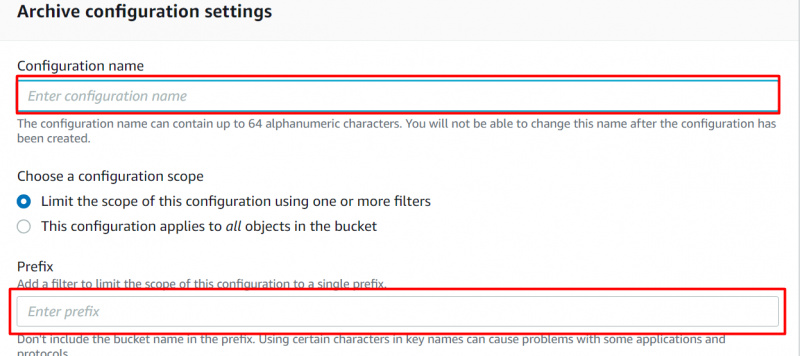
Giv den 'Navn' og 'Præfiks' for konfigurationer på den næste viste grænseflade:
Trin 8: Arkivadgangsniveau
Naviger til 'Arkiver regelhandlinger' sektion for at konfigurere, hvornår objekterne skal flyttes. Aktiver følgende mulighed og angiv et antal på hinanden følgende dage, hvorefter du vil flytte objekterne til 'Arkivadgangsniveau' :
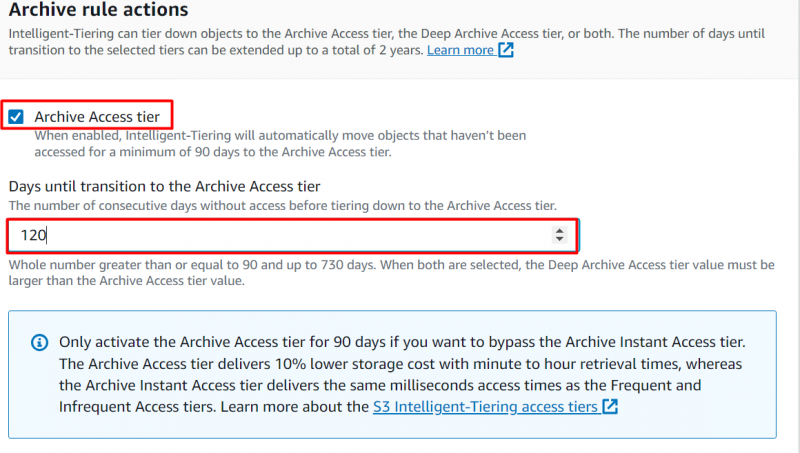
Bemærk : Hvis der ikke er adgang til et objekt i minimum 90 dage, objektet vil automatisk blive flyttet til arkivadgangsniveauet. Brugere kan forlænge denne periode til en maksimum af 730 dage.
Trin 9: Deep Archive Access Tier
Ligesom Archive Access Tier kan brugeren også konfigurere Deep Archive Access Tier. Ved at aktivere følgende mulighed, angiv det antal dage, hvorefter objektet skal flyttes til Deep Archive Access Tier. Når du har angivet antallet af dage, skal du klikke på 'Skab' knap:
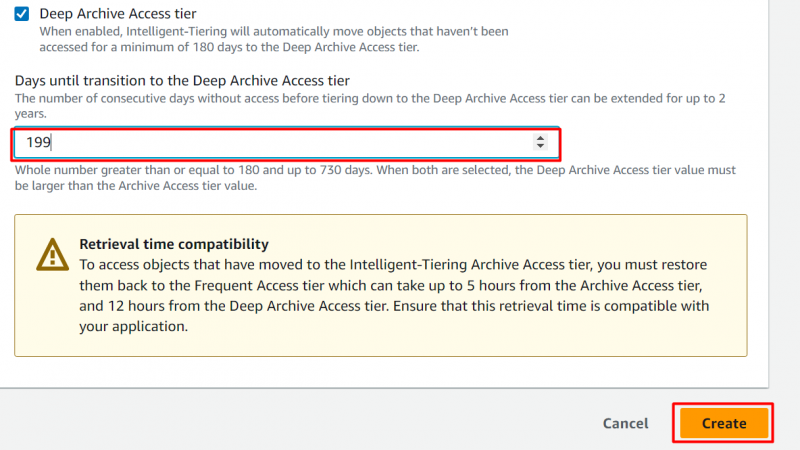
Bemærk : I Deep Archive Access Tier er de objekter, der ikke blev tilgået i en minimum 180 dage flyttes til dette niveau. Brugere kan tilpasse dette antal dage til en højst 730 dage .
Konfigurationerne er udført med succes. Nu, når de uploadede objekter ikke er tilgået af brugeren i det angivne tidsrum, vil dataene automatisk blive flyttet til forskellige niveauer for at minimere udgifterne:
Det er alt fra denne guide.
Konklusion
For omkostningsoptimering med S3-spanden skal du vælge Intelligent niveauklasse når du uploader filer og derefter angive tiden for de respektive niveauer. Intelligent-Tiering sparer omkostningerne ved at bestemme de ofte og sjældent tilgåede objekter til de respektive niveauer. Denne artikel giver trin-for-trin instruktioner til at opnå den omkostningsoptimale løsning med en S3 skovl.