6.1 Indledning
Moderne almindelige computere er af to typer: CISC og RISC. CISC står for Complex Instruction Set Computer. RISK står for Reduced Instruction Set Computer. 6502- eller 6510-mikroprocessorerne, som det er relevant for Commodore-64-computeren, minder mere om RISC-arkitekturen end en CISC-arkitektur.
RISC-computere har generelt kortere assemblersprog-instruktioner (efter antal bytes) sammenlignet med CISC-computere.
Bemærk : Uanset om det drejer sig om CISC, RISC eller gammel computer, starter en perifer enhed fra en intern port og går udad gennem en ekstern port på den lodrette overflade af computerens systemenhed (basisenhed) og til den eksterne enhed.
En typisk instruktion af en CISC-computer kan ses som at sammenføje flere korte assembly-sprog-instruktioner til en længere assembler-instruktion, hvilket gør den resulterende instruktion kompleks. Især en CISC-computer indlæser operanderne fra hukommelsen i mikroprocessorregistrene, udfører en operation og gemmer derefter resultatet tilbage i hukommelsen, alt sammen i én instruktion. På den anden side er dette mindst tre instruktioner (kort) til RISC-computeren.
Der er to populære serier af CISC-computere: Intel-mikroprocessor-computere og AMD-mikroprocessor-computere. AMD står for Advanced Micro Devices; det er en halvlederfremstillingsvirksomhed. Intels mikroprocessorserier, i rækkefølge efter udvikling, er 8086, 8088, 80186, 80286, 80386, 80486, Pentium, Core, i Series, Celeron og Xeon. Monteringssprog instruktionerne for de tidlige Intel mikroprocessorer såsom 8086 og 8088 er ikke særlig komplekse. De er dog komplekse for de nye mikroprocessorer. De seneste AMD-mikroprocessorer til CISC-serien er Ryzen, Opteron, Athlon, Turion, Phenom og Sempron. Intel- og AMD-mikroprocessorerne er kendt som x86-mikroprocessorerne.
ARM står for Advanced RISC Machine. ARM-arkitekturerne definerer en familie af RISC-processorer, som er velegnede til brug i en lang række applikationer. Mens mange Intel- og AMD-mikroprocessorer bruges i stationære pc'er, fungerer mange ARM-processorer som indlejrede processorer i sikkerhedskritiske systemer såsom blokeringsfrie bremser til biler og som generelle processorer i smartwatches, bærbare telefoner, tablets og bærbare computere . Selvom begge typer mikroprocessorer kan ses i små og store enheder, findes RISC-mikroprocessorerne mere i små enheder end i store enheder.
Computer Word
Hvis en computer siges at være en computer med 32 bit ord, betyder det, at informationen lagres, overføres og manipuleres i form af 32-bit binære koder inde i den indre del af bundkortet. Det betyder også, at de generelle registre i computerens mikroprocessor er 32-bit brede. A-, X- og Y-registrene i 6502-mikroprocessoren er registre til generelle formål. De er otte-bits brede, og derfor er Commodore-64-computeren en otte-bit-ordcomputer.
Noget ordforråd
X86 computere
Betydningen af byte, word, doubleword, quadword og double-quadword er som følger for x86-computere:
- Byte : 8 bits
- Ord : 16 bit
- Dobbeltord : 32 bit
- Quadword : 64 bit
- Dobbelt quadword : 128 bit
ARM computere
Betydningerne af byte, halfword, word og doubleword er som følger for ARM-computere:
- Byte : 8 bits
- Bliv halvt : 16 bit
- Ord : 32 bit
- Dobbeltord : 64 bit
Forskellene og lighederne for x86- og ARM-navnene (og værdierne) skal bemærkes.
Bemærk : Heltallene for tegn i begge computertyper er tos komplement.
Hukommelsesplacering
Med Commodore-64-computeren er en hukommelsesplacering typisk en byte, men kan lejlighedsvis være to på hinanden følgende bytes, når man overvejer pointerne (indirekte adressering). Med en moderne x86-computer er en hukommelsesplacering 16 konsekutive bytes, når man har at gøre med et dobbelt quadword på 16 bytes (128 bit), 8 på hinanden følgende bytes, når man beskæftiger sig med quadword på 8 bytes (64 bit), 4 konsekutive bytes, når man har at gøre med doubleword of 4 bytes (32 bit), 2 på hinanden følgende bytes, når der er tale om et ord på 2 bytes (16 bit), og 1 byte, når der er tale om en byte (8 bit). Med en moderne ARM-computer er en hukommelsesplacering 8 på hinanden følgende bytes, når man har at gøre med et dobbeltord på 8 bytes (64 bit), 4 på hinanden følgende bytes, når man har at gøre med et ord på 4 bytes (32 bit), 2 på hinanden følgende bytes, når man har at gøre med et halvord på 2 byte (16 bit) og 1 byte, når der er tale om en byte (8 bit).
Dette kapitel forklarer, hvad der er almindeligt i CISC- og RISC-arkitekturerne, og hvad deres forskelle er. Dette gøres i sammenligning med 6502 µP og commodore-64 computeren, hvor det er relevant.
6.2 Bundkort blokdiagram af moderne pc
PC står for Personal Computer. Det følgende er et generisk grundlæggende blokdiagram for et moderne bundkort med en enkelt mikroprocessor til en personlig computer. Det repræsenterer et CISC- eller RISC-bundkort.
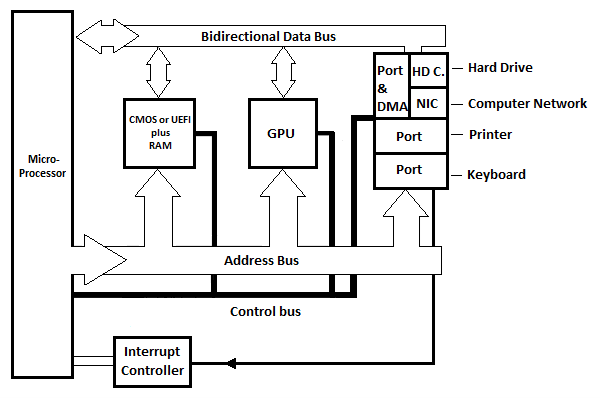
Fig. 6.21 Basisblokdiagram af bundkort for moderne pc
Tre interne porte er vist i diagrammet, men der er flere i praksis. Hver port har et register, der kan ses som selve porten. Hvert portkredsløb har mindst et andet register, som kan kaldes et 'statusregister'. Statusregisteret angiver porten til programmet, der sender afbrydelsessignalet til mikroprocessoren. Der er et interrupt controller-kredsløb (ikke vist), der skelner mellem de forskellige interrupt-linjer fra de forskellige porte og kun har nogle få linier til µP.
HD.C i diagrammet står for Hard Drive Card. NIC står for Network Interface Card. Harddiskkortet (kredsløbet) er forbundet til harddisken, som er inde i basisenheden (systemenheden) på den moderne computer. Netværksinterfacekortet (kredsløbet) er forbundet via et eksternt kabel til en anden computer. I diagrammet er der én port og en DMA (se følgende illustration), som er forbundet til harddiskkortet og/eller netværkskortet. DMA står for Direct Memory Access.
Husk fra Commodore-64 computerkapitlet, at for at sende bytes fra hukommelsen til diskdrevet eller en anden computer, skal hver byte kopieres til et register i mikroprocessoren, før den kopieres til den tilsvarende interne port, og derefter automatisk til enheden. For at modtage bytes fra diskdrevet eller en anden computer til hukommelsen, skal hver byte kopieres fra det tilsvarende interne portregister til et mikroprocessorregister, før den kopieres til hukommelsen. Dette tager normalt lang tid, hvis antallet af bytes i strømmen er stort. Løsningen til hurtig overførsel er brugen af Direct Memory Access (kredsløb) uden at passere gennem mikroprocessoren.
DMA-kredsløbet er mellem porten og HD. C eller NIC. Med DMA-kredsløbets direkte hukommelsesadgang sker overførslen af store strømme af bytes direkte mellem DMA-kredsløbet og hukommelsen (RAM) uden mikroprocessorens fortsatte deltagelse. DMA'en bruger adressebussen og databussen i stedet for µP. Den samlede varighed af overførslen er kortere, end hvis µP hard skal bruges. Både HD C. eller NIC bruger DMA, når de har en stor strøm af data (bytes) til overførsel med RAM (hukommelsen).
GPU står for Graphics Processing Unit. Denne blok på bundkortet er ansvarlig for at sende teksten og de bevægelige eller stillbilleder til skærmen.
Med de moderne computere (pc'er) er der ingen Read Only Memory (ROM). Der er dog BIOS eller UEFI, som er en slags ikke-flygtig RAM. Oplysningerne i BIOS vedligeholdes faktisk af et batteri. Batteriet er det, der faktisk også vedligeholder urtimeren på det rigtige tidspunkt og dato for computeren. UEFI blev opfundet efter BIOS og har erstattet BIOS, selvom BIOS stadig er ret relevant i moderne pc'er. Vi vil diskutere mere om disse senere!
I moderne pc'er er adresse- og databusserne mellem µP og de interne portkredsløb (og hukommelse) ikke parallelle busser. De er serielle busser, der har brug for to ledere til transmission i én retning og yderligere to ledere til transmission i den modsatte retning. Det betyder for eksempel, at 32-bit kan sendes i serie (den ene bit efter den anden) i begge retninger.
Hvis den serielle transmission kun er i én retning med to ledere (to linjer), siges det at være halv-dupleks. Hvis den serielle transmission er i begge retninger med fire ledere, et par i begge retninger, siges det at være fuld-dupleks.
Hele den moderne computers hukommelse består stadig af en række byteplaceringer: otte bits pr. byte. En moderne computer har en hukommelsesplads på mindst 4 gigabytes = 4 x 210 x 2 10 x 2 10 = 4 x 1.073.741.824 10 bytes = 4 x 1024 10/sub> x 1024 10 x 1024 10 = 4 x 1.073.741.824 10 .
Bemærk : Selvom der ikke er vist noget timerkredsløb på det tidligere bundkort, har alle moderne bundkort timerkredsløb.
6.3 Grundlæggende om x64 computerarkitektur
6.31 x64-registreringssættet
64-bit mikroprocessoren i x86-serien af mikroprocessorer er en 64-bit mikroprocessor. Det er ret moderne at erstatte 32-bit processoren i samme serie. 64-bit mikroprocessorens generelle registre og deres navne er som følger:
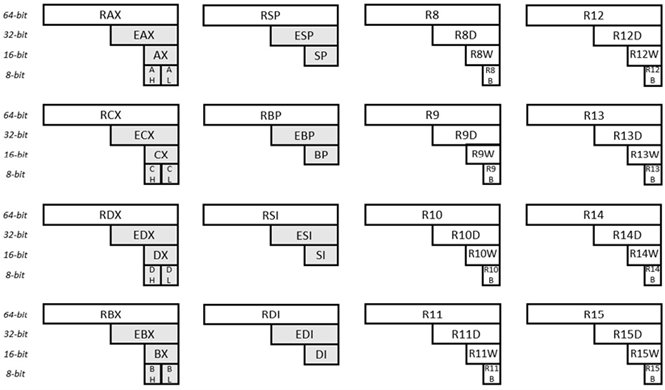
Fig. 6.31 Generelle registre til x64
Seksten (16) registre til generelle formål er vist i den givne illustration. Hvert af disse registre er 64-bit bredt. Ser man på registret i øverste venstre hjørne, identificeres de 64 bits som RAX. De første 32 bit af det samme register (fra højre) er identificeret som EAX. De første 16 bit af det samme register (fra højre) er identificeret som AX. Den anden byte (fra højre) af det samme register er identificeret som AH (H betyder her høj). Og den første byte (af dette samme register) er identificeret som AL (L betyder her lav). Ser man på registret i nederste højre hjørne, er de 64 bit identificeret som R15. De første 32 bit af det samme register er identificeret som R15D. De første 16 bit af det samme register er identificeret som R15W. Og den første byte er identificeret som R15B. Navnene på de andre registre (og underregistre) forklares på samme måde.
Der er nogle forskelle mellem Intel og AMD µP'erne. Oplysningerne i dette afsnit er for Intel.
Med 6502 µP er programtællerregisteret (ikke tilgængeligt direkte), som indeholder den næste instruktion, der skal udføres, 16-bit bredt. Her (x64) kaldes programtælleren Instruction Pointer, og den er 64-bit bred. Det er mærket som RIP. Dette betyder, at x64 µP kan adressere op til 264 = 1,844674407 x 1019 (faktisk 18.446.744.073.709.551.616) hukommelsesbyteplaceringer. RIP er ikke et almindeligt register.
Stack Pointer Register eller RSP er blandt de 16 generelle registre. Det peger på den sidste stakindgang i hukommelsen. Ligesom med 6502 µP vokser stakken for x64 nedad. Med x64'eren bruges stakken i RAM til at gemme returadresserne for subrutiner. Det bruges også til at gemme 'skyggerummet' (se den følgende diskussion).
6502 µP har et 8-bit processorstatusregister. Det tilsvarende i x64 kaldes RFLAGS-registret. Dette register gemmer de flag, der bruges til resultaterne af operationer og til at styre processoren (µP). Den er 64-bit bred. De højere 32 bit er reserveret og bruges ikke i øjeblikket. Følgende tabel giver navne, indeks og betydninger for de almindeligt anvendte bits i RFLAGS-registret:
| Tabel 6.31.1 Mest brugte RFLAGS-flag (bits) |
|||
|---|---|---|---|
| Symbol | Bit | Navn | Formål |
| CF | 0 | Bære | Det indstilles, hvis en aritmetisk operation genererer en carry eller et lån ud af den mest signifikante del af resultatet; ryddet ellers. Dette flag angiver en overløbsbetingelse for aritmetik uden fortegn. Det bruges også i aritmetik med flere præcision. |
| PF | 2 | Paritet | Den indstilles, hvis den mindst signifikante byte af resultatet indeholder et lige antal på 1 bit; ryddet ellers. |
| AF | 4 | Justere | Det indstilles, hvis en aritmetisk operation genererer en carry eller et lån ud af bit 3 af resultatet; ryddet ellers. Dette flag bruges i binært kodet decimal (BCD) aritmetik. |
| ZF | 6 | Nul | Den indstilles, hvis resultatet er nul; ryddet ellers. |
| SF | 7 | Skilt | Den indstilles, hvis den er lig med den mest signifikante bit af resultatet, som er fortegnsbitten af et heltal med fortegn (0 angiver en positiv værdi og 1 angiver en negativ værdi). |
| AF | elleve | Flyde over | Det indstilles, hvis heltalsresultatet er et for stort positivt tal eller et for lille negativt tal (eksklusive fortegnsbitten) til at passe ind i destinationsoperanden; ryddet ellers. Dette flag angiver en overløbsbetingelse for regnestykket med fortegns-heltal (to-komplement). |
| DF | 10 | Retning | Det indstilles, om retningsstrenginstruktionerne fungerer (øger eller formindsker). |
| ID | enogtyve | Identifikation | Den indstilles, hvis den kan ændres, angiver tilstedeværelsen af CPUID-instruktionen. |
Ud over de atten 64-bit registre, der tidligere er angivet, har x64-arkitekturen µP otte 80-bit brede registre til flydende komma-aritmetik. Disse otte registre kan også bruges som MMX-registre (se den følgende diskussion). Der er også seksten 128-bit registre til XMM (se den følgende diskussion).
Det handler ikke kun om registre. Der er flere x64-registre, som er segmentregistre (for det meste ubrugte i x64), kontrolregistre, hukommelsesstyringsregistre, fejlretningsregistre, virtualiseringsregistre, ydeevneregistre, der sporer alle mulige interne parametre (cache-hits/-misser, udførte mikrooperationer, timing , og meget mere).
SIMD
SIMD står for Single Instruction Multiple Data. Dette betyder, at én assemblersprogsinstruktion kan virke på flere data på samme tid i én mikroprocessor. Overvej følgende tabel:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| + | 9 | 10 | elleve | 12 | 13 | 14 | femten | 16 |
| = | 10 | 12 | 14 | 16 | 18 | tyve | 22 | 24 |
I denne tabel tilføjes otte par tal parallelt (i samme varighed) for at give otte svar. Én assemblersprogsinstruktion kan udføre de otte parallelle heltalsadditioner i MMX-registrene. En lignende ting kan gøres med XMM-registrene. Så der er MMX instruktioner for heltal og XMM instruktioner for float.
6.32 Hukommelseskort og x64
Med instruktionsmarkøren (programtælleren) med 64 bit, betyder det, at 264 = 1,844674407 x 1019 hukommelsesbyte-placeringer kan adresseres. I hexadecimal er den højeste byteplacering FFFF,FFFF,FFFF,FFFF16. Ingen almindelig computer i dag kan give så stor en hukommelse (komplet) plads. Så et passende hukommelseskort til x64-computeren er som følger:

Bemærk, at afstanden fra 0000,8000,0000,000016 til FFFF,7FFF,FFFF,FFFF16 ikke har nogen hukommelsesplaceringer (ingen hukommelses-RAM-banker). Dette er en forskel på FFFF,0000,0000,000116, hvilket er ret stort. Den kanoniske høje halvdel har operativsystemet, mens den kanoniske lave halvdel har brugerprogrammerne (applikationer) og data. Styresystemet består af to dele: en lille UEFI (BIOS) og en stor del, der indlæses fra harddisken. Det næste kapitel fortæller mere om de moderne operativsystemer. Bemærk ligheden med dette hukommelseskort og det for Commodore-64, når 64KB kunne have lignet meget hukommelse.
I denne sammenhæng kaldes operativsystemet groft for 'kernen'. Kernen ligner kernen på Commodore-64-computeren, men har langt flere underrutiner.
Endianiteten for x64 er little endian, hvilket betyder, at for en placering peger den nederste adresse på den lavere indholdsbyte i hukommelsen.
6.33 Assembly Language Addressing Modes for x64
Adresseringstilstande er de måder, hvorpå en instruktion kan få adgang til µP-registrene og hukommelsen (inklusive de interne portregistre). x64 har mange adresseringstilstande, men kun de almindeligt anvendte adresseringstilstande adresseres her. Den generelle syntaks for en instruktion her er:
opcode destination, kilde
Decimaltallene skrives uden præfiks eller suffiks. Med 6502 er kilden implicit. x64 har flere op-koder end 6502, men nogle af opkoderne har de samme mnemonics. De individuelle x64-instruktioner er af variabel længde og kan variere i størrelse fra 1 til 15 bytes. De almindeligt anvendte adresseringstilstande er som følger:
Øjeblikkelig adresseringstilstand
Her er kildeoperanden en faktisk værdi og ikke en adresse eller etiket. Eksempel (læs kommentaren):
TILFØJ EAX, 14 ; tilføj decimal 14 til 32-bit EAX af 64-bit RAX, svaret forbliver i EAX (destination)
Registrer for at registrere adresseringstilstand
Eksempel:
ADD R8B, AL; tilføj 8-bit AL af RAX til R8B af 64-bit R8 – svarene forbliver i R8B (destination)
Indirekte og indekseret adresseringstilstand
Indirekte adressering med 6502 µP betyder, at placeringen af den givne adresse i instruktionen har den effektive adresse (pointer) for den endelige placering. En lignende ting sker med x64. Indeksadressering med 6502 µP betyder, at indholdet af et µP register tilføjes til den givne adresse i instruktionen for at have den effektive adresse. En lignende ting sker med x64. Med x64 kan indholdet af registret også ganges med 1 eller 2 eller 4 eller 8, før det føjes til den givne adresse. mov (kopi) instruktionen på x64 kan kombinere både indirekte og indekseret adressering. Eksempel:
MOV R8W, 1234[8*RAX+RCX] ; flyt ord på adresse (8 x RAX + RCX) + 1234
Her har R8W de første 16-bits af R8. Den givne adresse er 1234. RAX-registeret har et 64-bit tal, der ganges med 8. Resultatet lægges til indholdet af 64-bit RCX-registeret. Dette andet resultat føjes til den givne adresse, som er 1234 for at opnå den effektive adresse. Nummeret på placeringen af den effektive adresse flyttes (kopieres) til det første 16-bit sted (R8W) i R8 registeret, og erstatter det, der var der. Bemærk brugen af firkantede parenteser. Husk, at et ord i x64 er 16-bit bredt.
RIP relativ adressering
For 6502 µP bruges relativ adressering kun med greninstruktioner. Der er den enkelte operand af opkoden en offset, der tilføjes eller trækkes fra programtællerens indhold for den effektive instruktionsadresse (ikke dataadresse). En lignende ting sker med x64, hvor programtælleren kaldes som instruktionsmarkør. Instruktionen med x64 behøver ikke kun at være en greninstruktion. Et eksempel på RIP-relativ adressering er:
MOV AL, [RIP]
AL i RAX har et 8-bit signeret tal, som tilføjes eller trækkes fra indholdet i RIP (64-bit instruktionsmarkør) for at pege på den næste instruktion. Bemærk, at kilden og destinationen undtagelsesvis er byttet om i denne instruktion. Bemærk også brugen af de firkantede parenteser, som refererer til indholdet af RIP.
6.34 Almindeligt brugte instruktioner til x64
I den følgende tabel betyder * forskellige mulige suffikser af en undergruppe af opkoder:
| Tabel 6.34.1 Almindeligt brugte instruktioner i x64 |
|
|---|---|
| Opkode | Betyder |
| MOV | Flyt (kopier) til/fra/mellem hukommelse og registre |
| CMOV* | Forskellige betingede træk |
| XCHG | Udveksle |
| BSWAP | Byte swap |
| PUSH/POP | Stakbrug |
| TILFØJ/ADC | Tilføj/med bære |
| SUB/SBC | Træk fra/med bære |
| MUL/IMUL | Multiplikér/ufortegn |
| DIV/IDIV | Opdel/usigneret |
| INC/DEC | Øge/reducere |
| NEG | Negere |
| CMP | Sammenligne |
| OG/ELLER/XOR/NOT | Bitvise operationer |
| SHR/SAR | Skift til højre logisk/aritmetisk |
| SHL/SAL | Skift logisk/aritmetik til venstre |
| ROR/ROLE | Drej til højre/venstre |
| RCR/RCL | Drej til højre/venstre gennem bærebit |
| BT/BTS/BTR | Bit test/og sæt/og nulstil |
| JMP | Ubetinget spring |
| JE/JNE/JC/JNC/J* | Hop hvis lige/ikke ens/bære/ikke bære/mange andre |
| GÅ/GÅ/GÅ/GÅ | Loop med ECX |
| RING/RET | Ring subrutine/retur |
| INTET P | Ingen operation |
| CPUID | CPU-oplysninger |
x64 har multiplikations- og dividerinstruktioner. Den har multiplikations- og divisionshardwarekredsløb i sin µP. 6502 µP har ikke multiplikations- og divisionshardwarekredsløb. Det er hurtigere at udføre multiplikation og division med hardware end med software (inklusive forskydning af bits).
Streng instruktioner
Der er en række strenginstruktioner, men den eneste, der skal diskuteres her, er MOVS-instruktionen (for move string) til at kopiere en streng, der starter på adressen C000 H . For at starte på adresse C100 H , brug følgende instruktion:
MOVS [C100H], [C000H]
Bemærk suffikset H for hexadecimal.
6.35 Looping i x64
6502 µP har greninstruktioner til looping. En greninstruktion hopper til en adresseplacering, som har den nye instruktion. Adresseplaceringen kan kaldes 'loop'. x64 har LOOP/LOOPE/LOOPNE instruktioner til looping. Disse reserverede samlesprogsord må ikke forveksles med 'loop'-etiketten (uden anførselstegn). Adfærden er som følger:
LOOP nedsætter ECX og kontrollerer, om ECX ikke er nul. Hvis denne betingelse (nul) er opfyldt, hopper den til en specificeret etiket. Ellers falder det igennem (fortsæt med resten af instruktionerne i den følgende diskussion).
LOOPE nedsætter ECX og kontrollerer, at ECX ikke er nul (kan f.eks. være 1), og ZF er sat (til 1). Hvis disse betingelser er opfyldt, hopper den på etiketten. Ellers falder det igennem.
LOOPNE nedsætter ECX og kontrollerer, at ECX ikke er nul, og ZF IKKE ER indstillet (dvs. være nul). Hvis disse betingelser er opfyldt, hopper den til etiketten. Ellers falder det igennem.
Med x64 holder RCX-registret eller dets underdele som ECX eller CX tællerheltallet. Med LOOP-instruktionerne tæller tælleren normalt ned og falder med 1 for hvert hop (loop). I det følgende looping-kodesegment stiger tallet i EAX-registeret fra 0 til 10 i ti iterationer, mens tallet i ECX tæller (reducerer) 10 gange (læs kommentarerne):
MOV EAX, 0 ;
MOV ECX, 10; tælle ned 10 gange som standard, én gang for hver iteration
etiket:
INC EAX ; forøg EAX som loop body
LOOP etiket ; formindsk EAX, og hvis EAX ikke er nul, genudfør loop body fra 'label:'
Sløjfekodningen begynder fra 'label:'. Bemærk brugen af tyktarmen. Sløjfekodningen slutter med 'LOOP-etiketten', som siger decrement EAX. Hvis indholdet ikke er nul, skal du gå tilbage til instruktionen efter 'label:' og gentage enhver instruktion (alle kropsinstruktioner), der kommer nedad, indtil 'LOOP-etiketten'. Bemærk, at 'label' stadig kan have et andet navn.
6.36 Input/Output af x64
Dette afsnit af kapitlet omhandler afsendelse af data til en output (intern) port eller modtagelse af data fra en input (intern) port. Chipsættet har otte-bit porte. Enhver to på hinanden følgende 8-bit-porte kan behandles som en 16-bit-port, og alle fire på hinanden følgende porte kan være en 32-bit-port. På denne måde kan processoren overføre 8, 16 eller 32 bits til eller fra en ekstern enhed.
Informationen kan overføres mellem processoren og en intern port på to måder: ved at bruge det, der er kendt som memory-mapped input/output eller ved at bruge et separat input/output adresserum. Den hukommelseskortede I/O er ligesom det, der sker med 6502-processoren, hvor portadresserne faktisk er en del af hele hukommelsespladsen. I dette tilfælde, når dataene sendes til en bestemt adresseplacering, går de til en port og ikke til en hukommelsesbank. Porte kan have et separat I/O-adresserum. I sidstnævnte tilfælde har alle hukommelsesbankerne deres adresser fra nul. Der er et separat adresseområde fra 0000H til FFFF16. Disse bruges af portene i chipsættet. Bundkortet er programmeret for ikke at forveksle mellem memory-mapped I/O og separat I/O-adresserum.
Hukommelseskortlagt I/O
Med dette betragtes portene som hukommelsesplaceringer, og de normale opkoder, der skal bruges mellem hukommelsen og µP, bruges til dataoverførsel mellem µP og porte. Så for at flytte en byte fra en port på adressen F000H til µP-registret RAX:EAX:AX:AL, skal du gøre følgende:
MOV AL, [F000H]
En streng kan flyttes fra hukommelsen til en port og omvendt. Eksempel:
MOVS [F000H], [C000H]; kilden er C000H, og destinationen er port ved F000H.
Separat I/O-adresserum
Hermed skal de specielle instruktioner for input og output bruges.
Overførsel af enkelte genstande
Processorregisteret for overførslen er RAX. Faktisk er det RAX:EAX for dobbeltord, RAX:EAX:AX for ord og RAX:EAX:AX:AL for byte. Så for at overføre en byte fra en port ved FFF0h til RAX:EAX:AX:AL skal du skrive følgende:
I AL, [FFF0H]
For omvendt overførsel skal du skrive følgende:
UD [FFF0H], AL
Så for enkelte varer er instruktionerne IN og OUT. Portadressen kan også angives i RDX:EDX:DX registeret.
Overførsel af strenge
En streng kan overføres fra hukommelsen til en chipsetport og omvendt. For at overføre en streng fra en port på adressen FFF0H til hukommelsen skal du begynde ved C100H, skrive:
INS [ESI], [DX]
som har samme effekt som:
INS [EDI], [DX]
Programmeringsenheden skal indsætte to-byte-portadressen på FFF0H i RDX:EDX:Dx-registret og bør indsætte to-byte-adressen på C100H i RSI:ESI- eller RDI:EDI-registret. For den omvendte overførsel skal du gøre følgende:
INS [DX], [ESI]
som har samme effekt som:
INS [DX], [EDI]
6.37 Stakken i x64
Ligesom 6502-processoren har x64-processoren også en stak i RAM. Stakken til x64 kan være 2 16 = 65.536 bytes lang, eller den kan være 2 32 = 4.294.967.296 bytes lang. Det vokser også nedad. Når indholdet af et register skubbes ind på stakken, reduceres tallet i RSP stak-markøren med 8. Husk at en hukommelsesadresse for x64'eren er 64 bit bred. Værdien i stak-markøren i µP peger på den næste placering i stakken i RAM. Når indholdet af et register (eller en værdi i en operand) poppes fra stakken ind i et register, øges tallet i RSP stak-markøren med 8. Operativsystemet bestemmer stakkens størrelse, og hvor den starter i RAM og vokser nedad. Husk, at en stak er en Last-In-First-Out (LIFO) struktur, som vokser nedad og krymper opad i dette tilfælde.
Gør følgende for at skubbe indholdet af µP RBX-registret til stakken:
PUSH RBX
Gør følgende for at få den sidste post i stakken tilbage til RBX:
POP RBX
6.38 Procedure i x64
Underrutinen i x64 kaldes 'procedure'. Stakken bruges her mere, end den bruges til 6502 µP. Syntaksen for en x64-procedure er:
proc_name:
procedure organ
…
ret
Inden du fortsætter, skal du bemærke, at opkoderne og etiketterne for en x64-underrutine (instruktioner i assemblersprog generelt) ikke skiller mellem store og små bogstaver. Det er proc_name er det samme som PROC_NAME. Ligesom 6502, starter navnet på procedurenavnet (label) i begyndelsen af en ny linje i teksteditoren for assemblersproget. Dette efterfølges af et kolon og ikke af mellemrum og opkode som med 6502. Subrutinelegemet følger og slutter med RET og ikke RTS som med 6502 µP. Ligesom med 6502 begynder hver instruktion i kroppen, inklusive RET, ikke i begyndelsen af sin linje. Bemærk, at en etiket her kan være mere end 8 tegn lang. For at kalde denne procedure, ovenfra eller under den indtastede procedure, skal du gøre følgende:
RING proc_name
Med 6502 er navnet på etiketten bare type for at ringe. Men her skrives det reserverede ord 'CALL' eller 'call' efterfulgt af navnet på proceduren (underrutinen) efter et mellemrum.
Når man beskæftiger sig med procedurer, er der normalt to procedurer. Den ene procedure kalder den anden. Den procedure, der kalder (har opkaldsinstruktionen) kaldes 'opkalderen', og den procedure, der kaldes, kaldes 'kalderen'. Der er en konvention (regler) at følge.
Ringerens regler
Den, der ringer op, skal overholde følgende regler, når han kalder en subrutine:
1. Inden der kaldes op til en underrutine, skal den, der ringer, gemme indholdet af visse registre, der er udpeget som opkalds-gemt i stakken. De opkalds-gemte registre er R10, R11 og eventuelle registre, som parametrene er sat ind i (RDI, RSI, RDX, RCX, R8, R9). Hvis indholdet af disse registre skal bevares på tværs af subrutineopkaldet, skal du skubbe dem på stakken i stedet for at gemme dem i RAM. Disse skal gøres, fordi registrene skal bruges af den opkaldte til at slette det tidligere indhold.
2. Hvis proceduren er at tilføje to tal for eksempel, er de to tal de parametre, der skal sendes til stakken. For at overføre parametrene til subrutinen skal du sætte seks af dem op i følgende registre i rækkefølge: RDI, RSI, RDX, RCX, R8, R9. Hvis der er mere end seks parametre til subrutinen, skal du skubbe resten ind på stakken i omvendt rækkefølge (dvs. sidste parameter først). Da stakken vokser ned, bliver den første af de ekstra parametre (egentlig den syvende parameter) gemt på den laveste adresse (denne inversion af parametre blev historisk brugt til at tillade funktionerne (subrutinerne) at blive sendt med et variabelt antal parametre).
3. Brug opkaldsinstruktionen for at kalde subrutinen (proceduren). Denne instruktion placerer returadressen oven på parametrene på stakken (laveste position) og grenene til subrutinekoden.
4. Efter at subrutinen vender tilbage (dvs. umiddelbart efter opkaldsinstruktionen), skal den, der ringer, fjerne eventuelle yderligere parametre (ud over de seks, der er gemt i registre) fra stakken. Dette gendanner stakken til dens tilstand, før opkaldet blev udført.
5. Den, der ringer, kan forvente at finde returværdien (adressen) for subrutinen i RAX-registret.
6. Den, der ringer, gendanner indholdet af de opkalds-gemte registre (R10, R11 og enhver i parameter-passer-registrene) ved at poppe dem ud af stakken. Den, der ringer, kan antage, at ingen andre registre blev ændret af subrutinen.
På grund af den måde, som kaldekonventionen er struktureret på, er det typisk sådan, at nogle (eller de fleste) af disse trin ikke vil foretage nogen ændringer i stakken. For eksempel, hvis der er seks eller færre parametre, skubbes intet ind på stakken i det trin. På samme måde holder programmører (og kompilatorer) typisk de resultater, som de holder af, ude af de opkalds-gemte registre i trin 1 og 6 for at forhindre overskydende push og pop.
Der er to andre måder at overføre parametrene til en subrutine på, men de vil ikke blive behandlet i dette online karrierekursus. En af dem bruger selve stakken i stedet for de generelle registre.
Callees regler
Definitionen af den kaldede subrutine skal overholde følgende regler:
1. Tildel de lokale variabler (variabler, der er udviklet inden for proceduren) ved hjælp af registrene eller ved at lave plads på stakken. Husk, at stakken vokser nedad. Så for at få plads på toppen af stakken, skal stakmarkøren formindskes. Mængden, hvormed stakmarkøren dekrementeres, afhænger af det nødvendige antal lokale variabler. For eksempel, hvis en lokal float og en lokal long (12 bytes i alt) er påkrævet, skal stakmarkøren dekrementeres med 12 for at give plads til disse lokale variable. I et sprog på højt niveau som C betyder det at deklarere variablerne uden at tildele (initialisere) værdierne.
2. Dernæst skal værdierne af eventuelle registre, der er de udpegede opkalds-gemte (generelle formål, ikke gemt af den, der ringer), som bruges af funktionen, gemmes. For at gemme registrene skal du skubbe dem på stakken. De callee-gemte registre er RBX, RBP og R12 til R15 (RSP er også bevaret af opkaldskonventionen, men behøver ikke at blive skubbet på stakken under dette trin).
Efter at disse tre handlinger er udført, kan den faktiske drift af subrutinen fortsætte. Når subrutinen er klar til at vende tilbage, fortsætter opkaldskonventionsreglerne.
3. Når subrutinen er færdig, skal returværdien for subrutinen placeres i RAX, hvis den ikke allerede er der.
4. Underrutinen skal gendanne de gamle værdier af alle opkalds-gemte registre (RBX, RBP og R12 til R15), som blev ændret. Registerindholdet gendannes ved at poppe dem fra stakken. Bemærk, at registrene skal poppes i den omvendte rækkefølge, som de blev skubbet.
5. Dernæst deallokerer vi de lokale variable. Den nemmeste måde at gøre dette på er at tilføje til RSP det samme beløb, som blev trukket fra det i trin 1.
6. Til sidst vender vi tilbage til den, der ringer, ved at udføre en ret-instruktion. Denne instruktion vil finde og fjerne den relevante returadresse fra stakken.
Et eksempel på kroppen af en opkaldsunderrutine til at kalde en anden underrutine, som er 'myFunc', er som følger (læs kommentarerne):
; Vil du kalde en funktion 'myFunc', der tager tre
; heltalsparameter. Første parameter er i RAX.
; Anden parameter er konstanten 456. Tredje
; parameter er i hukommelsesplacering 'variabel'
skubbe rdi ; rdi vil være en param, så gem den
; long retVal = myFunc (x, 456, z);
mov rdi , rax ; sæt første parameter i RDI
mov rsi, 456; sæt anden parameter i RSI
mov rdx , [variabel] ; sæt tredje parameter i RDX
ring til myFunc ; kalde funktionen
pop rdi ; gendan gemt RDI-værdi
; returværdien af myFunc er nu tilgængelig i RAX
Et eksempel på en callee-funktion (myFunc) er (læs kommentarerne):
myFunc:
; ∗∗∗ Standard subrutine prolog ∗∗∗
under rsp, 8; plads til en 64-bit lokal variabel (resultat) ved hjælp af 'sub' opkoden
skub rbx ; gem callee-gem registre
skub rbp ; begge vil blive brugt af myFunc
; ∗∗∗ Underrutine Krop ∗∗∗
mov rax , rdi ; parameter 1 til RAX
mov rbp, rsi; parameter 2 til RBP
mov rbx, rdx; parameter 3 til rb x
mov [rsp + 1 6], rbx; sæt rbx i lokal variabel
tilføje [rsp + 1 6], rbp; tilføje rbp til lokal variabel
mov rax, [rsp +16]; flyt indholdet af lokal variabel til RAX
; (returværdi/slutresultat)
; ∗∗∗ Standard subrutine epilog ∗∗∗
pop rbp ; gendan callee gemme registre
pop rbx ; omvendt af, når den skubbes
tilføje rsp, 8; dealloker lokale variable(r). 8 betyder 8 bytes
ret ; pop topværdi fra stakken, hop derhen
6.39 Afbrydelser og undtagelser for x64
Processoren har to mekanismer til at afbryde programkørsel, afbrydelser og undtagelser:
- En interrupt er en asynkron (kan ske når som helst) hændelse, der typisk udløses af en I/O-enhed.
- En undtagelse er en synkron hændelse (der sker, når koden udføres, forprogrammeres, baseret på en eller anden forekomst), der genereres, når processoren detekterer en eller flere foruddefinerede tilstande, mens den udfører en instruktion. Tre klasser af undtagelser er specificeret: fejl, fælder og afbrydelser.
Processoren reagerer på afbrydelser og undtagelser på stort set samme måde. Når en afbrydelse eller undtagelse signaleres, standser processoren udførelsen af det aktuelle program eller den aktuelle opgave og skifter til en behandlerprocedure, der er skrevet specifikt til at håndtere afbrydelsen eller undtagelsestilstanden. Processoren får adgang til behandlerproceduren gennem en indtastning i Interrupt Descriptor Table (IDT). Når handleren har afsluttet håndteringen af afbrydelsen eller undtagelsen, returneres programstyringen til det afbrudte program eller opgave.
Operativsystemet, executive og/eller enhedsdrivere håndterer normalt afbrydelser og undtagelser uafhængigt af applikationsprogrammer eller opgaver. Applikationsprogrammerne kan dog få adgang til de interrupt- og undtagelsesbehandlere, der er inkorporeret i et operativsystem, eller udføre det gennem assembly-sprog-kaldene.
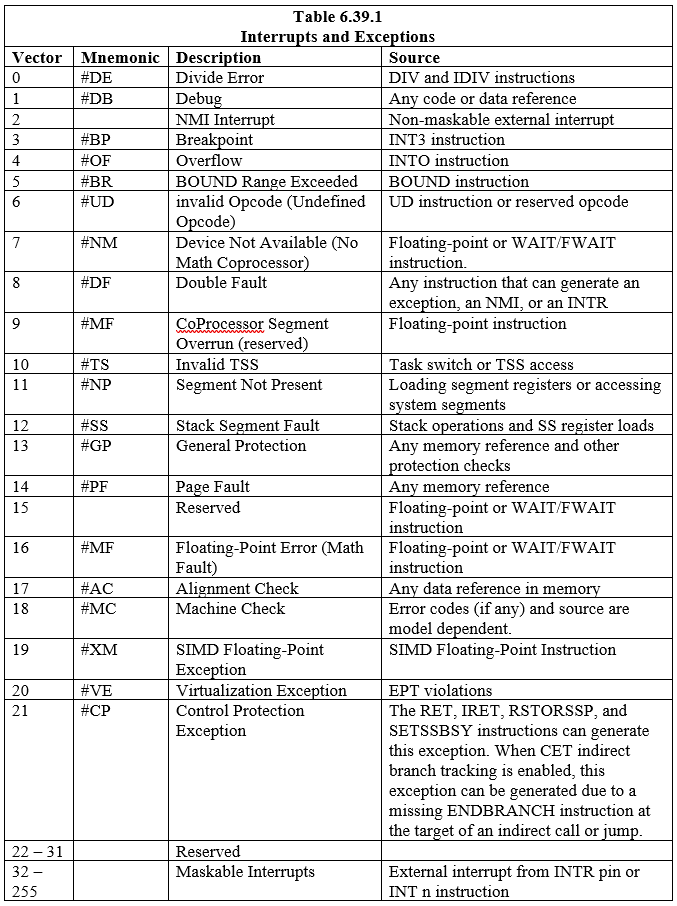
Atten (18) foruddefinerede afbrydelser og undtagelser, som er knyttet til indtastninger i IDT, er defineret. To-hundrede og fireogtyve (224) brugerdefinerede afbrydelser kan også udføres og associeres med tabellen. Hver afbrydelse og undtagelse i IDT er identificeret med et nummer, der kaldes en 'vektor'. Tabel 6.39.1 viser afbrydelser og undtagelser med indtastninger i IDT og deres respektive vektorer. Vektorerne 0 til 8, 10 til 14 og 16 til 19 er de foruddefinerede interrupts og undtagelser. Vektorerne 32 til 255 er til de softwaredefinerede interrupts (bruger), som er til enten softwareinterrupts eller maskerbare hardwareinterrupts.
Når processoren registrerer en afbrydelse eller undtagelse, gør den en af følgende ting:
- Udfør et implicit kald til en behandlerprocedure
- Udfør et implicit kald til en handleropgave
6.4 Grundlæggende om 64-bit ARM-computerarkitektur
ARM-arkitekturerne definerer en familie af RISC-processorer, der er velegnede til brug i en lang række applikationer. ARM er en load/store-arkitektur, der kræver, at data indlæses fra hukommelsen til et register, før nogen form for behandling såsom en ALU (Aritmetic Logic Unit) operation kan finde sted med den. En efterfølgende instruktion gemmer resultatet tilbage i hukommelsen. Selvom dette kan virke som et skridt tilbage fra x86- og x64-arkitekturerne, som opererer direkte på operanderne i hukommelsen i en enkelt instruktion (ved hjælp af processorregistre, selvfølgelig), tillader load/store-tilgangen i praksis adskillige sekventielle operationer skal udføres med høj hastighed på en operand, når den først er indlæst i et af de mange processorregistre. ARM-processorer har mulighed for lille endianness eller big endianness. Standard ARM 64-indstillingen er little-endian, som er den konfiguration, der almindeligvis bruges af operativsystemerne. 64-bit ARM-arkitekturen er moderne, og den er indstillet til at erstatte 32-bit ARM-arkitekturen.
Bemærk : Hver instruktion for 64-bit ARM µP er 4 byte (32 bit) lang.
6.41 64-bit ARM-registersæt
Der er 31 generelle formål med 64-bit registre til 64-bit ARM µP. Følgende diagram viser de generelle registre og nogle vigtige registre:
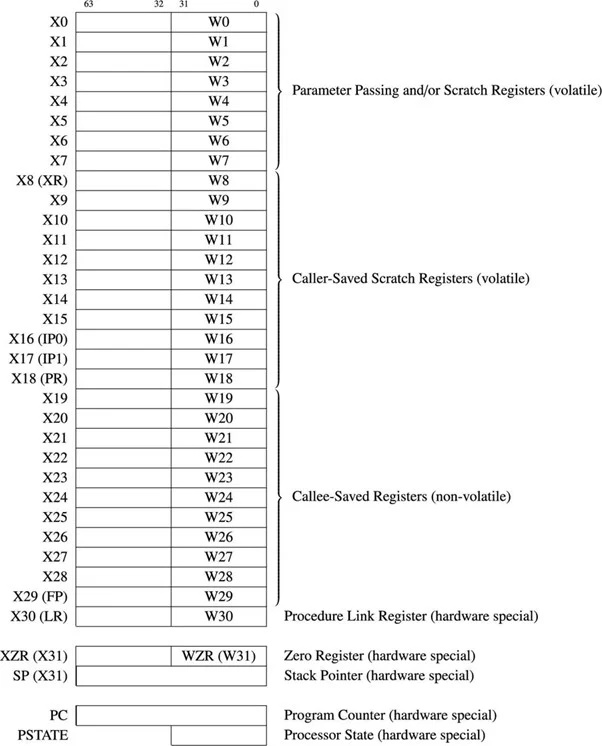
Fig.4.11.1 64-bit generelle formål og nogle vigtige registre
De generelle registre omtales som X0 til X30. Den første 32-bit del for hvert register omtales som W0 til W30. Når forskellen mellem 32 bit og 64 bit ikke fremhæves, bruges 'R'-præfikset. For eksempel refererer R14 til W14 eller X14.
6502 µP har en 16-bit programtæller og kan adressere 2 16 hukommelsesbyte-placeringer. 64-bit ARM µP har en 64-bit programtæller og kan adressere op til 2 64 = 1,844674407 x 1019 (faktisk 18.446.744.073.709.551.616) hukommelsesbyteplaceringer. Programtælleren holder adressen på den næste instruktion, der skal udføres. Længden af instruktionen for ARM64 eller AArch64 er typisk fire bytes. Processoren inkrementerer automatisk dette register med fire efter hver instruktion er hentet fra hukommelsen.
Stack Pointer-registret eller SP er ikke blandt de 31 generelle registre. Stakmarkøren for enhver arkitektur peger på den sidste stakindgang i hukommelsen. For ARM-64 vokser stakken nedad.
6502 µP har et 8-bit processorstatusregister. Det tilsvarende i ARM64 kaldes PSTATE-registret. Dette register gemmer de flag, der bruges til resultaterne af operationer og til at styre processoren (µP). Den er 32-bit bred. Følgende tabel giver navne, indeks og betydninger for de almindeligt anvendte bits i PSTATE-registret:
| Tabel 6.41.1 Mest brugte PSTATE-flag (bits) |
||
|---|---|---|
| Symbol | Bit | Formål |
| M | 0-3 | Tilstand: Det aktuelle udførelsesprivilegieniveau (USR, SVC og så videre). |
| T | 4 | Tommelfinger: Det indstilles, hvis T32 (Thumb) instruktionssættet er aktivt. Hvis det er klart, er ARM-instruktionssættet aktivt. Brugerkoden kan indstille og slette denne bit. |
| OG | 9 | Endianness: Indstilling af denne bit aktiverer big-endian-tilstanden. Hvis den er klar, er den lille endian-tilstand aktiv. Standard er den lille endian-tilstand. |
| Q | 27 | Kumulativt mætningsflag: Det indstilles, hvis der på et tidspunkt i en række operationer opstår et overløb eller en mætning |
| I | 28 | Overløbsflag: Det indstilles, hvis operationen resulterede i et underskrevet overløb. |
| C | 29 | Bæreflag: Det angiver, om additionen gav en carry eller subtraktionen gav et lån. |
| MED | 30 | Nulflag: Det indstilles, hvis resultatet af en operation er nul. |
| N | 31 | Negativt flag: Det indstilles, hvis resultatet af en operation er negativt. |
ARM-64 µP har mange andre registre.
SIMD
SIMD står for Single Instruction, Multiple Data. Dette betyder, at én assemblersprogsinstruktion kan virke på flere data på samme tid i én mikroprocessor. Der er 32 128 bit brede registre til brug med SIMD og flydende kommaoperationer.
6.42 Hukommelseskortlægning
RAM og DRAM er begge Random Access Memories. DRAM er langsommere i drift end RAM. DRAM er billigere end RAM. Hvis der er mere end 32 gigabyte (GB) fortsat DRAM i hukommelsen, vil der være flere problemer med hukommelsesstyring: 32 GB = 32 x 1024 x 1024 x 1024 bytes. For en hel hukommelsesplads, der er langt større end 32 GB, bør DRAM over 32 GB blandes med RAM'er for bedre hukommelsesstyring. For at forstå ARM-64-hukommelseskortet, bør du først forstå 4GB-hukommelseskortet til 32-bit ARM Central Processing Unit (CPU). CPU betyder µP. For en 32-bit computer er den maksimale hukommelsesadresserbare plads 2 32 = 4 x 2 10 x 2 10 x 2 10 = 4 x 1024 x 1024 x 1024 = 4.294.967.296 = 4 GB.
32-bit ARM-hukommelseskort
Hukommelseskortet for en 32-bit ARM er:

For en 32-bit computer er den maksimale størrelse af hele hukommelsen 4 GB. Fra 0GB-adressen til 1GB-adressen er ROM-operativsystemet, RAM- og I/O-placeringerne. Hele ideen med ROM OS, RAM og I/O-adresser ligner situationen for Commodore-64 med en mulig 6502 CPU. OS ROM'en til Commodore-64 er i den øverste ende af hukommelsespladsen. ROM OS her er meget større end Commodore-64, og det er i begyndelsen af hele hukommelsesadresserummet. Sammenlignet med andre moderne computere er ROM OS her komplet, i den forstand at det kan sammenlignes med mængden af OS på deres harddiske. Der er to hovedårsager til at have OS i de integrerede ROM-kredsløb: 1) ARM CPU'er bruges mest i små enheder som smartphones. Mange harddiske er større end smartphones og andre små enheder, 2) for sikkerheden. Når operativsystemet er i skrivebeskyttet hukommelse, kan det ikke beskadiges (dele overskrives) af hackere. RAM-sektionerne og input/output-sektionerne er også meget store sammenlignet med Commodore-64.
Når strømmen er tændt med 32-bit ROM OS, skal operativsystemet starte ved (boot fra) 0x00000000-adressen eller 0xFFFF0000-adressen, hvis HiVECs er aktiveret. Så når strømmen tændes efter nulstillingsfasen, indlæser CPU-hardwaren 0x00000000 eller 0xFFFF0000 til programtælleren. Præfikset '0x' betyder hexadecimal. Bootadressen på ARMv8 64bit CPU'er er en defineret implementering. Forfatteren råder dog computeringeniøren til at starte ved 0x00000000 eller 0xFFFF0000 af hensyn til bagudkompatibilitet.
Fra 1 GB til 2 GB er den tilknyttede input/output. Der er en forskel mellem den tilknyttede I/O og kun I/O, der findes mellem 0GB og 1GB. Med I/O er adressen for hver port fast som med Commodore-64. Med kortlagt I/O er adressen for hver port ikke nødvendigvis den samme for hver operation af computeren (dynamisk).
Fra 2GB til 4GB er DRAM. Dette er den forventede (eller sædvanlige) RAM. DRAM står for Dynamic RAM, ikke er betydningen af en skiftende adresse under computerdrift, men i den forstand, at værdien af hver celle i den fysiske RAM skal opdateres ved hver clock-impuls.
Bemærk :
- Fra 0x0000.0000 til 0x0000 er FFFF OS ROM'en.
- Fra 0x0001,0000 til 0x3FFF,FFFF kan der være mere ROM, så RAM og så noget I/O.
- Fra 0x4000.0000 til 0x7FFF,FFFF er en ekstra I/O og/eller kortlagt I/O tilladt.
- Fra 0x8000.0000 til 0xFFFF er FFFF den forventede DRAM.
Disse betyder, at den forventede DRAM ikke behøver at starte ved 2GB hukommelsesgrænsen, i praksis. Hvorfor skal programmøren respektere de ideelle grænser, når der ikke er nok fysiske RAM-banker, der er placeret på bundkortet? Dette skyldes, at kunden ikke har penge nok til alle RAM-bankerne.
36-bit ARM-hukommelseskort
For en 64-bit ARM-computer bruges alle de 32 bit til at adressere hele hukommelsen. For en 64-bit ARM-computer kan de første 36 bit bruges til at adressere hele hukommelsen, som i dette tilfælde er 2 36 = 68.719.476.736 = 64 GB. Dette er allerede meget hukommelse. De almindelige computere i dag har ikke brug for denne mængde hukommelse. Dette er endnu ikke op til det maksimale hukommelsesområde, der kan tilgås med 64 bit. Hukommelseskortet for 36-bit til ARM CPU er:
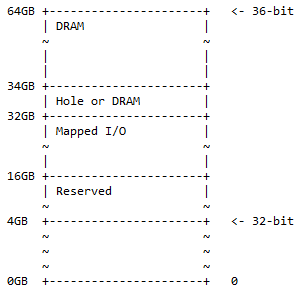
Fra 0GB-adressen til 4GB-adressen er 32-bit hukommelseskort. 'Reserveret' betyder ikke brugt og opbevares til fremtidig brug. Det behøver ikke at være fysiske hukommelsesbanker, der er indsat på bundkortet for den plads. Her har DRAM og mappet I/O samme betydning som for 32-bit hukommelseskort.
Følgende situation kan forekomme i praksis:
- 0x1 0000 0000 – 0x3 FFFF FFFF; reserveret. 12 GB adresseplads er reserveret til fremtidig brug.
- 0x4 0000 0000 – 0x7 FFFF FFFF; kortlagt I/O. 16 GB adresseplads er tilgængelig for dynamisk kortlagt I/O.
- 0x8 0000 0000 – 0x8 7FFF FFFF FFFF; Hul eller DRAM. 2 GB adresseplads kan indeholde en af følgende:
- Hul for at aktivere DRAM-enhedspartitionering (som beskrevet i den følgende diskussion).
- DRAM.
- 0x8 8000 0000 – 0xF FFFF FFFF; DRAM. 30 GB adresseplads til DRAM.
Dette hukommelseskort er et supersæt af 32-bit adressekortet, hvor den ekstra plads opdeles som 50 % DRAM (1/2) med et valgfrit hul i og 25 % kortlagt I/O-plads og reserveret plads (1/4) ). De resterende 25 % (1/4) er for 32-bit hukommelseskort ½ + ¼ + ¼ = 1.
Bemærk : Fra 32 bit til 360 bit er en tilføjelse af 4 bit til den mest signifikante side af 36 bit.
40-bit hukommelseskort
40-bit adressekortet er et supersæt af 36-bit adressekortet og følger det samme mønster med 50 % DRAM af et valgfrit hul i det, 25 % kortlagt I/O-rum og reserveret plads, og resten af de 25 % plads til det forrige hukommelseskort (36-bit). Diagrammet for hukommelseskortet er:
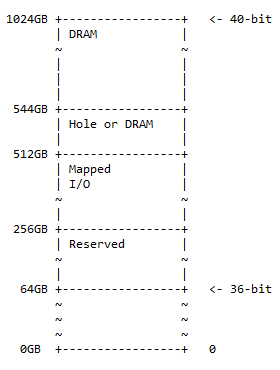
Størrelsen på hullet er 544 – 512 = 32GB. Følgende situation kan forekomme i praksis:
- 0x10 0000 0000 – 0x3F FFFF FFFF; reserveret. 192 GB adresseplads er reserveret til fremtidig brug.
- 0x40 0000 0000 – 0x7F FFFF FFFF; kortlagt. I/O 256 GB adresseplads er tilgængelig for dynamisk kortlagt I/O.
- 0x80 0000 0000 – 0x87 FFFF FFFF; hul eller DRAM. 32 GB adresseplads kan indeholde en af følgende:
- Hul for at aktivere DRAM-enhedspartitionering (som beskrevet i den følgende diskussion)
- DRAM
- 0x88 0000 0000 – 0xFF FFFF FFFF; DRAM. 480 GB adresseplads til DRAM.
Bemærk : Fra 36 bit til 40 bit er en tilføjelse af 4 bit til den mest signifikante side af 36 bit.
DRAM hul
I hukommelseskortet ud over 32-bit er det enten et DRAM-hul eller en fortsættelse af DRAM fra toppen. Når det er et hul, skal det forstås som følger: DRAM-hul giver en måde at opdele en stor DRAM-enhed i flere adresseområder. Det valgfri DRAM-hul foreslås ved starten af den højere DRAM-adressegrænse. Dette muliggør et forenklet afkodningsskema, når en DRAM-enhed med stor kapacitet opdeles på tværs af det lavere fysisk adresserede område.
For eksempel er en 64 GB DRAM-del opdelt i tre områder med adresseforskydningerne udført ved en simpel subtraktion i de høje ordens adressebit som følger:
| Tabel 6.42.1 Eksempel på 64GB DRAM-partitionering med huller |
|||
|---|---|---|---|
| Fysiske adresser i SoC | Offset | Intern DRAM-adresse | |
| 2 GBytes (32-bit kort) | 0x00 8000 0000 – 0x00 FFFF FFFF | -0x00 8000 0000 | 0x00 0000 0000 – 0x00 7FFF FFFF |
| 30 GBytes (36-bit kort) | 0x08 8000 0000 – 0x0F FFFF FFFF | -0x08 0000 0000 | 0x00 8000 0000 – 0x07 FFFF FFFF |
| 32 GBytes (40-bit kort) | 0x88 0000 0000 – 0x8F FFFF FFFF | -0x80 0000 0000 | 0x08 0000 0000 – 0x0F FFFF FFFF |
Foreslåede 44-bit og 48-bit adresserede hukommelseskort til ARM CPU'er
Antag, at en personlig computer har 1024 GB (= 1 TB) hukommelse; det er for meget hukommelse. Og så er de 44-bit og 48-bit adresserede hukommelseskort til ARM CPU'er til henholdsvis 16 TB og 256 TB blot forslag til fremtidige computerbehov. Faktisk følger disse forslag til ARM CPU'er den samme opdeling af hukommelse efter forhold som de tidligere hukommelseskort. Det vil sige: 50 % DRAM med et valgfrit hul i, 25 % kortlagt I/O-plads og reserveret plads, og resten af de 25 % plads til det forrige hukommelseskort.
De 52-bit, 56-bit, 60-bit og 64-bit adresserede hukommelseskort skal stadig foreslås for ARM 64 bits i den fjerne fremtid. Hvis forskerne på det tidspunkt stadig finder 50 : 25 : 25-opdelingen af hele hukommelsespladsen nyttig, vil de bevare forholdet.
Bemærk : SoC står for System-on-Chip, som henviser til kredsløb i µP-chippen, som ellers ikke ville have været der.
SRAM eller Static Random Access Memory er hurtigere end den mere traditionelle DRAM, men kræver mere siliciumareal. SRAM kræver ikke opfriskning. Læseren kan forestille sig RAM som SRAM.
6.43 Assembly Language Addressing Modes for ARM 64
ARM er en load/store-arkitektur, som kræver, at dataene indlæses fra hukommelsen til et processorregister, før nogen behandling, såsom en aritmetisk logisk operation, kan finde sted med den. En efterfølgende instruktion gemmer resultatet tilbage i hukommelsen. Selvom dette kan virke som et skridt tilbage fra x86 og dens efterfølgende x64-arkitekturer, som opererer direkte på operanderne i hukommelsen i en enkelt instruktion, tillader load/store-tilgangen i praksis at udføre flere sekventielle operationer med høj hastighed på en operand, når den først er indlæst i et af de mange processorregistre.
Formatet på ARM-assemblysproget har ligheder og forskelle med x64 (x86)-serien.
- Offset : En fortegnskonstant kan tilføjes til basisregistret. Forskydningen indtastes som en del af instruktionen. For eksempel: ldr x0, [rx, #10] indlæser r0 med ordet på r1+10-adressen.
- Tilmeld : En usigneret stigning, der er gemt i et register, kan lægges til eller trækkes fra værdien i et basisregister. For eksempel: ldr r0, [x1, x2] indlæser r0 med ordet på x1+x2-adressen. Begge registre kan opfattes som basisregistret.
- Skaleret register : En stigning i et register forskydes til venstre eller højre med et specificeret antal bitpositioner, før det tilføjes til eller trækkes fra basisregisterværdien. For eksempel: ldr x0, [x1, x2, lsl #3] indlæser r0 med ordet på r1+(r2×8)-adressen. Skiftet kan være et logisk venstre- eller højreskift (lsl eller lsr), som indsætter nul bit i de frigivne bitpositioner eller et aritmetisk højreskift (asr), der replikerer fortegnsbitten i de ledige positioner.
Når to operander er involveret, kommer destinationen før (til venstre) kilden (der er nogle undtagelser fra dette). Opkoderne for ARM-assemblysproget er ufølsomme for store og små bogstaver.
Øjeblikkelig ARM64-adresseringstilstand
Eksempel:
mov r0, #0xFF000000 ; Indlæs 32-bit værdien FF000000h i r0
En decimalværdi er uden 0x, men er stadig foranstillet af #.
Tilmeld dig direkte
Eksempel:
mov x0, x1; Kopier x1 til x0
Registrer indirekte
Eksempel:
str x0, [x3]; Gem x0 til adressen i x3
Registrer Indirekte med Offset
Eksempler:
ldr x0, [x1, #32] ; Indlæs r0 med værdien på adressen [r1+32]; r1 er basisregisteret
str x0, [x1, #4] ; Gem r0 til adressen [r1+4]; r1 er basisregisteret; tallene er basis 10
Registrer indirekte med offset (forhøjet)
Eksempler:
ldr x0, [x1, #32]! ; Indlæs r0 med [r1+32] og opdater r1 til (r1+32)
str x0, [x1, #4]! ; Gem r0 til [r1+4] og opdater r1 til (r1+4)
Bemærk brugen af '!' symbol.
Registrer indirekte med offset (efter-inkrementeret)
Eksempler:
ldr x0, [x1], #32 ; Indlæs [x1] til x0, og opdater derefter x1 til (x1+32)
str x0, [x1], #4 ; Gem x0 til [x1], og opdater derefter x1 til (x1+4)
Dobbelt Register Indirekte
Adressen på operanden er summen af et basisregister og et inkrementregister. Registernavnene er omgivet af firkantede parenteser.
Eksempler:
ldr x0, [x1, x2]; Indlæs x0 med [x1+x2]
str x0, [rx, x2]; Gem x0 til [x1+x2]
Relativ adresseringstilstand
I relativ adresseringstilstand er den effektive instruktion den næste instruktion i programtælleren plus et indeks. Indekset kan være positivt eller negativt.
Eksempel:
ldr x0, [pc, #24]
Det betyder belastningsregisteret X0 med det ord, der peges på af pc-indholdet plus 24.
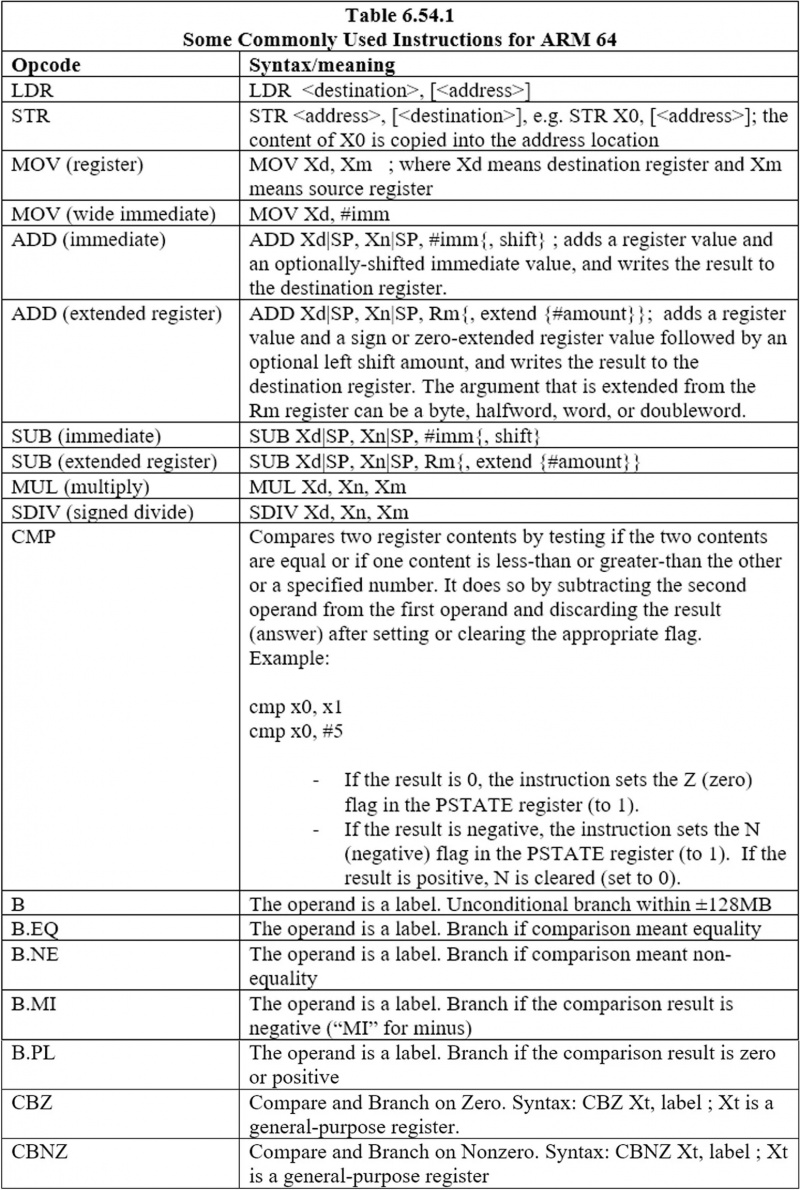
6.44 Nogle almindeligt anvendte instruktioner til ARM 64
Her er de almindeligt anvendte instruktioner:
6.45 Looping
Illustration
Følgende kode bliver ved med at tilføje værdien i X10-registret til værdien i X9, indtil værdien i X8 er nul. Antag, at alle værdierne er heltal. Værdien i X8 trækkes fra med 1 i hver iteration:
sløjfe:
CBZ X8, spring over
TILFØJ X9, X9, X10; første X9 er destination og anden X9 er kilde
SUB X8, X8, #1 ; første X8 er destination og anden X8 er kilde
B sløjfe
springe:
Ligesom med 6502 µP og X64 µP begynder mærket i ARM 64 µP i begyndelsen af linjen. Resten af instruktionerne starter ved nogle mellemrum efter begyndelsen af linjen. Med x64 og ARM 64 efterfølges etiketten af et kolon og en ny linje. Mens med 6502, efterfølges etiketten af en instruktion efter et mellemrum. I den foregående kode betyder den første instruktion, som er 'CBZ X8, spring over', at hvis værdien i X8 er nul, fortsæt ved 'spring:'-etiketten, spring instruktionerne over imellem og fortsæt med resten af instruktionerne nedenfor 'springe:'. 'B loop' er et ubetinget spring til 'loop'-etiketten. Ethvert andet etiketnavn kan bruges i stedet for 'loop'.
Så, ligesom med 6502 µP, skal du bruge greninstruktionerne til at have en sløjfe med ARM 64.
6.46 ARM 64 Input/Output
Alle ARM-ydre enheder (interne porte) er hukommelseskortlagt. Dette betyder, at programmeringsgrænsefladen er et sæt hukommelsesadresserede registre (interne porte). Adressen på et sådant register er en offset fra en specifik hukommelsesbasisadresse. Dette svarer til, hvordan 6502 udfører input/output. ARM har ikke mulighed for separat I/O-adresserum.
6.47 Stak af ARM 64
ARM 64 har en stak i hukommelsen (RAM) på samme måde, som 6502 og x64 har. Men med ARM64 er der ingen push- eller pop-opkode. Stakken i ARM 64 vokser også nedad. Adressen i stak-markøren peger lige efter den sidste byte af den sidste værdi, der er placeret i stakken.
Grunden til, at der ikke er nogen generisk pop- eller push-op-kode til ARM64, er, at ARM 64 administrerer sin stak i grupper af på hinanden følgende 16 bytes. Værdierne findes dog i bytegrupper på én byte, to bytes, fire bytes og 8 bytes. Så én værdi kan placeres i stakken, og resten af stederne (byteplaceringer) for at kompensere for 16 bytes er polstret med dummy-bytes. Dette har den ulempe, at det spilder hukommelse. En bedre løsning er at fylde 16-byte placeringen med mindre værdier og have en eller anden programmør skrevet kode, der sporer, hvor værdierne i 16-byte placeringen kommer fra (registre). Denne ekstra kode er også nødvendig for at trække værdierne tilbage. Et alternativ til dette er at fylde to 8-byte generelle registre med de forskellige værdier og derefter sende indholdet af de to 8-byte registre til en stak. En ekstra kode er stadig nødvendig her for at spore de specifikke små værdier, der går ind i stakken og forlader stakken.
Følgende kode gemmer fire 4-byte data i stakken:
str w0, [sp, #-4]!
str w1, [sp, #-8]!
str w2, [sp, #-12]!
str w3, [sp, #-16]!
De første fire bytes (w) af registre – x0, x1, x2 og x3 – sendes til 16 på hinanden følgende byteplaceringer i stakken. Bemærk brugen af 'str' og ikke 'push'. Bemærk udråbssymbolet i slutningen af hver instruktion. Da hukommelsesstakken vokser nedad, starter den første fire-byte værdi ved en position, som er minus-fire bytes under den forrige stak-pointerposition. Resten af de fire-byte værdier følger, går ned. Følgende kodesegment vil gøre det korrekte (og i rækkefølge) ækvivalent med at poppe de fire bytes:
ldr w3, [sp], #0
ldr w2, [sp], #4
ldr w1, [sp], #8
Bemærk brugen af ldr-opkoden i stedet for pop. Bemærk også, at udråbssymbolet ikke bruges her.
Alle bytes i X0 (8 bytes) og X1 (8 bytes) kan sendes til 16 byte-placeringen i stakken som følger:
stp x0, x1, [sp, #-16]! ; 8 + 8 = 16
I dette tilfælde er x2 (w2) og x3 (w3) registrene ikke nødvendige. Alle de ønskede bytes er i X0- og X2-registrene. Bemærk stp-opkoden til lagring af registerindholdsparrene i RAM'en. Bemærk også udråbstegn. Popækvivalenten er:
ldp x0, x1, [sp], #0
Der er intet udråbstegn for denne instruktion. Bemærk opkoden LDP i stedet for LDR for at indlæse to på hinanden følgende dataplaceringer fra hukommelsen til to µP registre. Husk også, at kopiering fra hukommelsen til et µP-register indlæses, ikke at forveksle med indlæsning af en fil fra disken til RAM, og kopiering fra et µP-register til RAM lagrer.
6.48 Underrutine
En subrutine er en kodeblok, der udfører en opgave, eventuelt baseret på nogle argumenter og eventuelt returnerer et resultat. Konventionelt bruges R0 til R3 registrene (fire registre) til at videregive argumenterne (parametrene) til en subrutine, og R0 bruges til at sende et resultat tilbage til den, der ringer. En subrutine, der har brug for mere end 4 input, bruger stakken til de ekstra input. For at kalde en underrutine skal du bruge linket eller den betingede greninstruktion. Syntaksen for linkinstruktionen er:
BL mærke
Hvor BL er opkoden, og label repræsenterer starten (adressen) af subrutinen. Denne gren er ubetinget, frem eller tilbage inden for 128 MB. Syntaksen for den betingede greninstruktion er:
B.cond label
Hvor cond er betingelsen, f.eks. eq (lig) eller ne (ikke lig). Følgende program har doadd-underrutinen, der tilføjer værdierne af to argumenter og returnerer et resultat i R0:
AREA subrout, CODE, READONLY ; Name this block of code
INDGANG ; Marker den første instruktion, der skal udføres
start MOV r0, #10 ; Set up parameters
MOV r1, #3
BL doadd ; Ring subrutine
stop MOV r0, #0x18 ; angel_SWIreason_ReportException
LDR r1, =0x20026; ADP_Stopped_ApplicationExit
SVC #0x123456 ; ARM semihosting (tidligere SWI)
doadd ADD r0, r0, r1; Subroutine code
BX lr ; Return from subroutine
;
SLUT ; Mark end of file
Tallene, der skal tilføjes, er decimal 10 og decimal 3. De første to linjer i denne kodeblok (program) vil blive forklaret senere. De næste tre linjer sender 10 til R0 register og 3 til R1 register, og kalder også doadd-underrutinen. 'Doadd' er den etiket, der indeholder adressen på begyndelsen af subrutinen.
Underrutinen består kun af to linjer. Den første linje tilføjer indholdet 3 af R til indholdet 10 af R0, hvilket tillader resultatet af 13 i R0. Den anden linje med BX-opkoden og LR-operanden vender tilbage fra subrutinen til opkaldskoden.
RET
RET-opkoden i ARM 64 omhandler stadig subrutinen, men fungerer anderledes end RTS i 6502 eller RET på x64 eller 'BX LR'-kombinationen i ARM 64. I ARM 64 er syntaksen for RET:
RET {Xn}
Denne instruktion giver programmet mulighed for at fortsætte med en subrutine, der ikke er den kaldende subrutine, eller bare fortsætte med en anden instruktion og dens følgende kodesegment. Xn er et almindeligt register, der indeholder adressen, som programmet skal fortsætte til. Denne instruktion forgrener sig ubetinget. Det er standard til indholdet af X30, hvis Xn ikke er givet.
Procedure Call Standard
Hvis programmøren ønsker, at hans kode skal interagere med en kode, der er skrevet af en anden eller med en kode, der er produceret af en compiler, skal programmøren blive enig med personen eller compiler-skribenten om reglerne for registerbrug. For ARM-arkitekturen kaldes disse regler Procedure Call Standard eller PCS. Det er aftaler mellem de to eller tre parter. PCS specificerer følgende:
- Hvilke µP registre bruges til at sende argumenterne ind i funktionen (underrutinen)
- Hvilke µP-registre bruges til at returnere resultatet til den funktion, der foretager opkaldet, som er kendt som kalderen
- Hvilken µP registrerer den funktion, der kaldes, som er kendt som callee, kan ødelægge
- Hvilke µP-registre kan den kaldende ikke korrumpere
6.49 Afbryder
Der er to typer interrupt-controller-kredsløb tilgængelige for ARM-processoren:
- Standard Interrupt Controller: Interrupt-handleren bestemmer, hvilken enhed der kræver service, ved at læse et enheds bitmapregister i interruptcontrolleren.
- Vector Interrupt Controller (VIC): Prioriterer afbrydelserne og forenkler bestemmelsen af, hvilken enhed der forårsagede afbrydelsen. Efter at have knyttet en prioritet og en behandleradresse til hver afbrydelse, påstår VIC'en kun et afbrydelsessignal til processoren, hvis prioriteten af en ny afbrydelse er højere end den aktuelt eksekverende afbrydelsesbehandler.
Bemærk : Undtagelse henviser til fejl. Detaljerne for vektorafbrydelsescontrolleren til 32-bit ARM-computeren er som følger (64 bit er ens):
| Tabel 6.49.1 ARM vektor undtagelse/afbrydelse for 32-bit computer |
|||
|---|---|---|---|
| Undtagelse/Afbrydelse | Kort hånd | Adresse | Høj adresse |
| Nulstil | NULSTIL | 0x00000000 | 0xffff0000 |
| Udefineret instruktion | UNDEF | 0x00000004 | 0xffff0004 |
| Software afbrydelse | SWI | 0x00000008 | 0xffff0008 |
| Prefetch abort | pabt | 0x0000000C | 0xffff000C |
| Abort dato | DABT | 0x00000010 | 0xffff0010 |
| Reserveret | – | 0x00000014 | 0xffff0014 |
| Afbrydelsesanmodning | IRQ | 0x00000018 | 0xffff0018 |
| Hurtig afbrydelsesanmodning | FIQ | 0x0000001C | 0xffff001C |
Dette ligner arrangementet for 6502-arkitekturen hvor NMI , BR , og IRQ kan have pointere på side nul, og de tilsvarende rutiner er højt oppe i hukommelsen (ROM OS). Korte beskrivelser af rækkerne i den foregående tabel er som følger:
NULSTIL
Dette sker, når processoren starter. Det initialiserer systemet og opsætter stakkene til forskellige processortilstande. Det er den højest prioriterede undtagelse. Ved indtræden i nulstillingsbehandleren er CPSR i SVC-tilstand, og både IRQ- og FIQ-bits er sat til 1, hvilket maskerer eventuelle afbrydelser.
DATO FOR ABORT
Den næsthøjeste prioritet. Dette sker, når vi forsøger at læse/skrive til en ugyldig adresse eller få adgang til den forkerte adgangstilladelse. Ved adgang til Data Abort Handler vil IRQ'erne blive deaktiveret (I-bit sæt 1), og FIQ vil blive aktiveret. IRQ'erne er maskerede, men FIQ'erne holdes umaskerede.
FIQ
Den højeste prioritetsafbrydelse, IRQ & FIQ'er, er deaktiveret, indtil FIQ er håndteret.
IRQ
Den høje prioritetsafbrydelse, IRQ-handleren, indtastes kun, hvis der ikke er nogen igangværende FIQ & dataafbrydelse.
Pre-fetch Afbryd
Dette ligner dataafbrydelse, men sker ved fejl ved adressehentning. Ved adgang til handleren er IRQ'er deaktiveret, men FIQ'er forbliver aktiveret og kan ske under en pre-fetch afbrydelse.
SWI
En Software Interrupt (SWI)-undtagelse opstår, når SWI-instruktionen udføres, og ingen af de andre undtagelser med højere prioritet er blevet markeret.
Udefineret instruktion
Undefined Instruction-undtagelsen opstår, når en instruktion, der ikke er i ARM- eller Thumb-instruktionssættet, når udførelsesstadiet af pipelinen, og ingen af de andre undtagelser er blevet markeret. Dette er den samme prioritet som SWI, da man kan ske ad gangen. Det betyder, at den instruktion, der udføres, ikke både kan være en SWI-instruktion og en udefineret instruktion på samme tid.
ARM Undtagelseshåndtering
Følgende hændelser opstår, når der sker en undtagelse:
- Gem CPSR til SPSR for undtagelsestilstanden.
- PC er gemt i LR i undtagelsestilstanden.
- Linkregistret er sat til en bestemt adresse baseret på den aktuelle instruktion. For eksempel: for ISR, LR = sidst udførte instruktion + 8.
- Opdater CPSR om undtagelsen.
- Indstil pc'en til adressen på undtagelsesbehandleren.
6.5 Instruktioner og data
Data refererer til variabler (etiketter med deres værdier) og arrays og andre strukturer, der ligner array. Strengen er som en række tegn. En række heltal ses i et af de foregående kapitler. Instruktioner henviser til opkoder og deres operander. Et program kan skrives med opkoderne og data blandet i en fortsat sektion af hukommelsen. Den tilgang har ulemper, men anbefales ikke.
Et program skal skrives med instruktionerne først, efterfulgt af dataene (flertal af datum er data). Adskillelsen mellem instruktionerne og dataene kan kun være nogle få bytes. For et program kan både instruktionerne og dataene være i en eller to separate sektioner i hukommelsen.
6.6 Harvard-arkitekturen
En af de tidlige computere hedder Harvard Mark I (1944). En stram Harvard-arkitektur bruger ét adresserum til programinstruktioner og et andet separat adresserum til data. Det betyder, at der er to separate minder. Følgende viser arkitekturen:
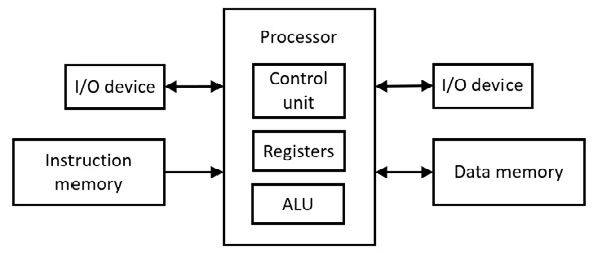
Figur 6.71 Harvard-arkitektur
Kontrolenheden udfører instruktionsafkodningen. Den aritmetiske logiske enhed (ALU) udfører de aritmetiske operationer med kombinationslogik (gates). ALU udfører også de logiske operationer (f.eks. skift).
Med 6502-mikroprocessoren går en instruktion først til mikroprocessoren (kontrolenheden), før datumet (ental for data) går til µP-registret, før de interagerer. Dette kræver mindst to clock-impulser, og det er ikke en samtidig adgang til instruktionen og datumet. På den anden side giver Harvard-arkitekturen samtidig adgang til instruktionerne og dataene, hvor både instruktion og datum indtaster µP på samme tid (opkode til kontrolenhed og datum til µP-register), hvilket sparer mindst én clock-impuls. Dette er en form for parallelisme. Denne form for parallelisme bruges i hardware-cachen i moderne bundkort (se den følgende diskussion).
6.7 Cachehukommelse
Cache-hukommelse (RAM) er et højhastighedshukommelsesområde (sammenlignet med hastigheden på hovedhukommelsen), der midlertidigt gemmer programinstruktionerne eller dataene til fremtidig brug. Cachehukommelsen fungerer hurtigere end hovedhukommelsen. Normalt hentes disse instruktioner eller dataelementer fra den seneste hovedhukommelse og vil sandsynligvis blive nødvendige igen inden længe. Det primære formål med cachehukommelsen er at øge hastigheden for gentagne gange at få adgang til de samme hovedhukommelsesplaceringer. For at være effektiv skal adgangen til de cachelagrede elementer være betydeligt hurtigere end at få adgang til den originale kilde til instruktionerne eller dataene, som omtales som Backing Store.
Når caching er i brug, begynder hvert forsøg på at få adgang til en hovedhukommelsesplacering med en søgning i cachen. Hvis den ønskede vare er til stede, henter og bruger processoren den med det samme. Dette kaldes et cache-hit. Hvis cachesøgningen mislykkes (en cache-miss), skal instruktionen eller dataelementet hentes fra backing-lageret (hovedhukommelsen). I processen med at hente det anmodede element føjes en kopi til cachen til en forventet nær fremtidig brug.
Hukommelsesstyringsenhed
Memory Management Unit (MMU) er et kredsløb, der styrer hovedhukommelsen og relaterede hukommelsesregistre på bundkortet. Tidligere var det et separat integreret kredsløb på bundkortet; men i dag er det typisk en del af mikroprocessoren. MMU'en skal også administrere cachen (kredsløbet), som også er en del af mikroprocessoren i dag. Cachekredsløbet er tidligere et separat integreret kredsløb.
Statisk RAM
Statisk RAM (SRAM) har en væsentligt hurtigere adgangstid end DRAM, omend på bekostning af væsentligt mere komplekse kredsløb. SRAM-bitcellerne optager meget mere plads på den integrerede kredsløbsmatrice end cellerne i en DRAM-enhed, der er i stand til at lagre en tilsvarende mængde data. Hovedhukommelsen (RAM) består typisk af DRAM (Dynamisk RAM).
Cachehukommelsen forbedrer computerens ydeevne, fordi mange algoritmer, der udføres af operativsystemer og applikationer, udviser referencelokaliteten. Lokaliteten refererer til genbrug af data, der er blevet tilgået for nylig. Dette kaldes Temporal Locality. På et moderne bundkort er cachehukommelsen i samme integrerede kredsløb som mikroprocessoren. Hovedhukommelsen (DRAM) er langt væk og er tilgængelig via busserne. Referencelokaliteten henviser også til rumlig lokalitet. Den rumlige lokalitet har at gøre med den højere hastighed for dataadgang på grund af fysisk nærhed.
Som regel er cache-hukommelsesområderne små (i antal byte-placeringer) i forhold til backing-lageret (hovedhukommelsen). Cachehukommelsesenhederne er designet til maksimal hastighed, hvilket generelt betyder, at de er mere komplekse og dyre per bit end den datalagringsteknologi, der bruges i backing-lageret. På grund af deres begrænsede størrelse har cachehukommelsesenhederne en tendens til at fylde hurtigt. Når en cache ikke har en tilgængelig placering til at gemme en ny post, skal en ældre post kasseres. Cache-controlleren bruger en Cache-erstatningspolitik til at vælge, hvilken cache-indgang der skal overskrives af den nye post.
Målet med mikroprocessorens cachehukommelse er at maksimere procentdelen af cachehits over tid, hvilket giver den højeste vedvarende hastighed for instruktionsudførelse. For at nå dette mål skal cachinglogikken bestemme, hvilke instruktioner og data der vil blive placeret i cachen og opbevaret til nær fremtidig brug.
En processors cachelogik har ikke sikkerhed for, at et cachelagret dataelement nogensinde vil blive brugt igen, når det først er blevet indsat i cachen.
Logikken i caching er afhængig af sandsynligheden for, at der på grund af tidsmæssig (gentagelse over tid) og rumlig (rum) lokalitet er en meget god chance for, at de cachelagrede data vil blive tilgået i den nærmeste fremtid. I praktiske implementeringer på moderne processorer forekommer cache-hits typisk på 95 til 97 procent af hukommelsesadgange. Da latensen af cachehukommelse er en lille brøkdel af latensen af DRAM, fører en høj cache-hitrate til en væsentlig forbedring af ydeevnen sammenlignet med et cache-frit design.
Noget parallelisme med cache
Som tidligere nævnt har et godt program i hukommelsen instruktionerne adskilt fra dataene. I nogle cache-systemer er der et cache-kredsløb til 'venstre' af processoren, og der er et andet cache-kredsløb til 'højre' af processoren. Den venstre cache håndterer instruktionerne for et program (eller en applikation), og den højre cache håndterer dataene fra det samme program (eller samme applikation). Dette fører til en bedre øget hastighed.
6.8 Processer og tråde
Både CISC- og RISC-computere har processer. En proces er på softwaren. Et program, der kører (udfører) er en proces. Operativsystemet kommer med sine egne programmer. Mens computeren kører, kører de programmer i operativsystemet, der sætter computeren i stand til at fungere. Disse er operativsystemprocesser. Brugeren eller programmøren kan skrive sine egne programmer. Når brugerens program kører, er det en proces. Det er ligegyldigt, om programmet er skrevet i assemblersprog eller på højt niveau som C eller C++. Alle processer (bruger eller OS) styres af en anden proces kaldet en 'planlægger'.
En tråd er som en delproces, der hører til en proces. En proces kan starte og opdeles i tråde og derefter stadig fortsætte som én proces. En proces uden tråde kan betragtes som hovedtråden. Processer og deres tråde styres af den samme planlægger. Selve planlæggeren er et program, når den er bosiddende på OS-disken. Når du kører i hukommelsen, er skemalæggeren en proces.
6.9 Multibearbejdning
Tråde styres næsten som processer. Multiprocessing betyder at køre mere end én proces på samme tid. Der er computere med kun én mikroprocessor. Der er computere med mere end én mikroprocessor. Med en enkelt mikroprocessor bruger processerne og/eller trådene den samme mikroprocessor på en interleaving- (eller tidsskærende) måde. Det betyder, at en proces bruger processoren og stopper uden at blive færdig. En anden proces eller tråd bruger processoren og stopper uden at afslutte. Derefter bruger en anden proces eller tråd mikroprocessoren og stopper uden at afslutte. Dette fortsætter, indtil alle processer og tråde, der blev sat i kø af planlæggeren, har haft en del af processoren. Dette kaldes samtidig multiprocessing.
Når der er mere end én mikroprocessor, er der en parallel multiprocessing, i modsætning til samtidighed. I dette tilfælde kører hver processor en bestemt proces eller tråd, forskellig fra hvad den anden processor kører. Alle processorerne på det samme bundkort kører deres forskellige processer og/eller forskellige tråde på samme tid i parallel multiprocessing. Processerne og trådene i parallel multiprocessing styres stadig af planlæggeren. Parallel multiprocessing er hurtigere end samtidig multiprocessing.
På dette tidspunkt kan læseren undre sig over, hvordan parallel behandling er hurtigere end samtidig behandling. Dette skyldes, at processorerne deler (skal bruge på forskellige tidspunkter) den samme hukommelse og input/output-porte. Nå, med brugen af cache er den overordnede drift af bundkortet hurtigere.
6.10 Personsøgning
Memory Management Unit (MMU) er et kredsløb, der er tæt på mikroprocessoren eller i mikroprocessorchippen. Det håndterer hukommelseskort eller personsøgning og andre hukommelsesproblemer. Hverken 6502 µP eller Commodore-64 computeren har en MMU i sig selv (selvom der stadig er en vis hukommelsesstyring i Commodore-64). Commodore-64 håndterer hukommelsen ved at bladre, hvor hver side er 256 10 bytes lang (100 16 bytes lange). Det var ikke obligatorisk for den at håndtere hukommelsen ved at søge. Det kunne stadig bare have et hukommelseskort og så programmer, der bare passer ind i deres forskellige udpegede områder. Nå, personsøgning er en måde at give en effektiv brug af hukommelsen uden at have mange hukommelsessektioner, der ikke kan have et data eller program.
x86 386 computerarkitekturen blev udgivet i 1985. Adressebussen er 32-bit bred. Altså i alt 2 32 = 4.294.967.296 adresserum er muligt. Dette adresseområde er opdelt i 1.048.576 sider = 1.024 KB sider. Med dette antal sider består én side af 4.096 bytes = 4 KB. Følgende tabel viser de fysiske adressesider for x86 32-bit arkitekturen:
| Tabel 6.10.1 Fysisk adresserbare sider til x86-arkitekturen |
||
|---|---|---|
| Base 16 adresser | sider | Base 10 adresser |
| FFFFF000 – FFFFFFFF | Side 1.048.575 | 4.294.963.200 – 4.294.967.295 |
| FFFFE000 – FFFFEFFF | Side 1.044.479 | 4.294.959.104 – 4.294.963.199 |
| FFFFD000 – FFFFDFFF | Side 1.040.383 | 4.294.955.008 – 4.294.959.103 |
| | | | |
| | | |
| | | |
| 00002000 – 00002FFF | Side 2 | 8.192 – 12.288 |
| 00001000 – 00001FFF | Side 1 | 4.096 – 8.191 |
| 00000000 – 00000FFF | Side 0 | 0 – 4.095 |
En ansøgning består i dag af mere end ét program. Et program kan tage mindre end en side (mindre end 4096), eller det kan tage to eller flere sider. Så en applikation kan tage en eller flere sider, hvor hver side er 4096 byte lang. Forskellige personer kan skrive en ansøgning, hvor hver person er tildelt en eller flere sider.
Bemærk, at side 0 er fra 00000000H til 00000FFF
side 1 er fra 00001000H til 00001FFFH, side 2 er fra 00002000 H – 00002FFF H , og så videre. For en 32-bit computer er der to 32-bit registre i processoren til fysisk sideadressering: et for basisadressen og det andet for indeksadressen. For at få adgang til byteplaceringerne på side 2, for eksempel, skal registret for basisadressen være 00002 H som er de første 20 bit (fra venstre) for side 2 startadresserne. Resten af bits i området 000 H til FFF H er i registret kaldet 'indeksregisteret'. Så alle bytes på siden kan tilgås ved blot at øge indholdet i indeksregisteret fra 000 H til FFF H . Indholdet i indeksregisteret føjes til indholdet, som ikke ændres i basisregistret for at opnå den effektive adresse. Dette indeksadresseskema gælder for de andre sider.
Det er dog ikke rigtig sådan, assemblersprogprogrammet er skrevet for hver side. For hver side skriver programmøren koden begyndende fra side 000 H til side FFF H . Da koden på forskellige sider er forbundet, bruger compileren indeksadresseringen til at forbinde alle de relaterede adresser på forskellige sider. For eksempel, hvis man antager, at side 0, side 1 og side 2 er til én applikation og hver har 555 H adresse, der er forbundet med hinanden, kompilerer compileren på en sådan måde, at når 555 H af side 0 skal tilgås, 00000 H vil være i basisregistret og 555 H vil være i indeksregistret. Når 555 H af side 1 skal tilgås, 00001 H vil være i basisregistret og 555 H vil være i indeksregistret. Når 555 H på side 2 skal tilgås, 00002 H vil være i basisregistret, og 555H vil være i indeksregistret. Dette er muligt, fordi adresserne kan identificeres ved hjælp af etiketter (variabler). De forskellige programmører skal aftale navnet på de etiketter, der skal bruges til de forskellige tilslutningsadresser.
Side virtuel hukommelse
Paging, som tidligere beskrevet, kan modificeres for at øge størrelsen af hukommelsen i en teknik, der omtales som 'Page Virtual Memory'. Hvis vi antager, at alle de fysiske hukommelsessider, som tidligere beskrevet, har noget (instruktioner og data), er ikke alle siderne aktive i øjeblikket. De sider, der ikke er aktive i øjeblikket, sendes til harddisken og erstattes af de sider fra harddisken, der skal køre. På den måde øges størrelsen af hukommelsen. Efterhånden som computeren fortsætter med at fungere, skiftes de sider, der bliver inaktive, med siderne på harddisken, som stadig kan være de sider, der blev sendt fra hukommelsen til disken. Alt dette udføres af Memory Management Unit (MMU).
6.11 Problemer
Læseren rådes til at løse alle problemerne i et kapitel, før de går videre til næste kapitel.
1) Angiv ligheder og forskelle mellem CISC og RISC computerarkitekturerne. Nævn et eksempel på hver SISC- og RISC-computer.
2) a) Hvad er følgende navne for CISC-computeren i form af bits: byte, word, doubleword, quadword og double quadword.
b) Hvad er følgende navne for RISC-computeren i form af bits: byte, halvord, ord og dobbeltord.
c) Ja eller nej. Betyder doubleword og quadword de samme ting i både CISC og RISC arkitekturer?
3 a) For x64 varierer antallet af bytes til assemblersprogsinstruktionerne fra hvad til hvad?
b) Er antallet af bytes for alle assembly-sprog-instruktioner for ARM 64 fast? Hvis ja, hvad er antallet af bytes for alle instruktioner?
4) Angiv de mest almindeligt anvendte monteringssprog instruktioner for x64 og deres betydning.
5) Angiv de mest almindeligt anvendte monteringssprog instruktioner for ARM 64 og deres betydning.
6) Tegn et mærket blokdiagram af den gamle computer Harvard Architecture. Forklar, hvordan dets instruktioner og datafunktioner bruges i cachen på moderne computere.
7) Skill mellem en proces og en tråd og giv navnet på den proces, der håndterer processerne og trådene i de fleste computersystemer.
8) Forklar kort, hvad der er multiprocessing.
9) a) Forklar personsøgning som relevant for x86 386 µP computerarkitekturen.
b) Hvordan kan denne personsøgning modificeres for at øge størrelsen af hele hukommelsen?