Pandas Set_Option Method
I dag vil vi se på, hvordan du bruger 'pd.set_option()'-funktionen til at vise alle kolonnerne i Pandas Dataframe, når du præsenterer det i dit Spyder-værktøj. For at bruge 'pd.set_option()', følger vi den givne syntaks:

Lad os begynde at lære konceptet ved hjælp af den praktiske implementering af Python-programmet.
Eksempel: Brug af Pandas Set_Option-metode til at vise alle kolonnerne
Denne demonstration er en guide til at vise alle kolonnerne i en DataFrame ved at bruge Pandas 'set_option()'. Vi vil tydeliggøre detaljerne for hvert trin for implementeringen af denne Python-metode.
Det første krav til den praktiske implementering af Python-scriptet er at finde ud af det bedste værktøj, hvor du udfører dit program. Værktøjet, som vi brugte til vores illustration, er 'Spyder'-værktøjet. Vi lancerede værktøjet og begyndte at arbejde på Python-scriptet.
Begyndende med koden skal vi i første omgang importere de forudsætningsbiblioteker, som vi har brug for i dette program. Det første bibliotek, som vi indlæste i vores Python-fil, er Pandas-biblioteket, da de funktioner, vi bruger her, leveres af Pandas. Vi kaldte dette bibliotek som 'pd'. Det andet bibliotek, vi indlæste, er NumPy-biblioteket. NumPy (Numerical Python) er en numerisk computerpakke udviklet over Python-programmering. Import NumPy-sektionen i koden instruerer Python til at integrere NumPy-modulet i din nuværende Python-fil. 'som np'-delen af scriptet instruerer derefter Python om at tildele NumPy 'np'-forkortelsen. Det giver dig mulighed for at bruge NumPy-metoderne ved at indtaste 'np.function_name' i stedet for NumPy.
Nu begynder vi med hovedkoden. Det vigtigste og grundlæggende behov for vores program er Pandas DataFrame. Så vi viser alle de kolonner, den indeholder. Nu er det helt op til dig, om du vil oprette en DataFrame med specificerede værdier, eller om du skal importere en CSV-fil. Det, vi valgte til denne instans, var at skabe en DataFrame med NaN-værdier. Vi påberåbte 'pd.DataFrame()'-metoden for at konstruere en DataFrame. Her har vi angivet to parametre - 'indeks' og 'kolonner'. Argumentet 'indeks' refererer til rækkerne, hvilket betyder, at vi indstiller rækkerne for DataFrame.
Vi tildelte 'index'-parameteren og NumPy-funktionen 'np.arange() med et værdiantal på '6'. Det genererer seks rækker til DataFrame. Den udfylder alle indgange med NaN-værdier, da vi ikke har givet den nogen værdi. Argumentet 'kolonner', som navnet angiver, bruges til at indstille kolonnerne for DataFrame. Den er også tildelt 'np.arange()'-funktionen med '25' værdiantal for kolonnerne. Således konstruerer den 25 kolonner til DataFrame.
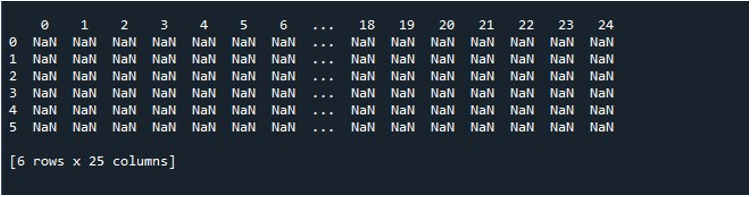
Når vi kalder 'pd.DataFrame()'-funktionen, har vi derfor en DataFrame med 25 kolonner og 6 rækker fyldt med nulværdier. For behovet for at bevare denne DataFrame er vi forpligtet til at bygge et DataFrame-objekt, der gemmer dets indhold. Derfor oprettede vi et DataFrame-objekt 'tilfældigt' og tildelte det det resultat, som vi får fra metoden 'pd.DataFrame()'. Nu vil du helt sikkert se DataFrame blive genereret. Python giver os en metode til at se outputtet på skærmen, som er 'print()'-funktionen. Vi påberåbte denne metode ved at sende DataFrame-objektet 'tilfældigt' som dets parameter.
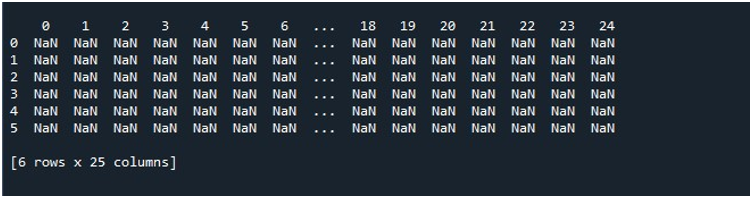
Når vi udfører dette kodestykke, får vi vores DataFrame med NaN-værdier vist på terminalen. Her kan vi konstatere, at nogle af de første kolonner og kun nogle få fra slutningen er synlige. Alle de mellemliggende kolonner er afkortet. Som standard skjuler det nogle af rækkerne og kolonnerne for at undgå at skabe en frustration for brugeren ved at vise enorme datasæt.
Du kan endda kontrollere antallet af samlede kolonner i en DataFrame ved at bruge 'len()'-funktionen i Pandas. Skriv 'len()'-funktionen på konsollen på dit 'Spyder'-værktøj. Skriv DataFrames navn mellem dens parentes med egenskaben '.columns'. Det returnerer os den samlede længde af kolonner i din DataFrame.

Det returnerer længden af vores DataFrame, som er 25.
Nu er den næste og kerneopgave at ændre standardindstillingen for at vise outputtet. Der kan være omstændigheder, hvor du ønsker at se hele DataFrame på terminalen. På grund af standardværdierne bliver mange poster afkortet, hvilket forårsager skuffelse for brugeren. Du vil her lære, hvordan du løser dette problem. Pandas giver os en 'pd.set_option()'-funktion til at ændre standardvisningsindstillingerne. Lige efter at have vist DataFrame på konsollen, påberåber vi 'pd.set_option()' metoden. Vi angiver parameteren mellem parenteserne af denne funktion, som vi skal bruge til at vise alle kolonnerne i DataFrame.
Her brugte vi 'display.max_columns' til at vise de maksimale kolonner i vores DataFrame. Vi kan også definere værdien for denne parameter, dvs. de maksimale kolonner, du ønsker at få vist. Vi på den anden side sætter 'display.max_columns' til 'None', som viser alle kolonnerne fra DataFrame med maksimal længde. Til sidst brugte vi 'print()'-funktionen til at vise den resulterende DataFrame med alle kolonnerne synlige på terminalen.
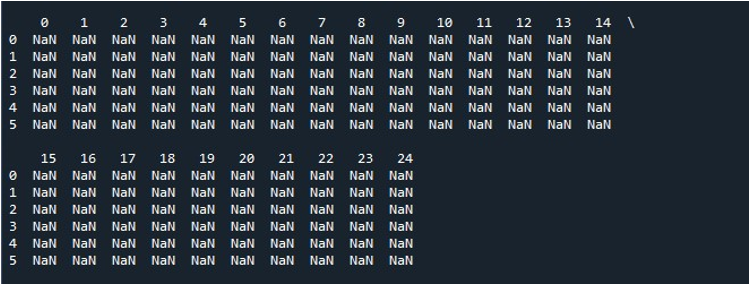
Når vi rammer 'Kør fil'-indstillingen på 'Spyder'-værktøjet, kan vi se en DataFrame, der udstilles. Denne DataFrame har seks rækker, og antallet af kolonner, den har, er 25. Der er ingen kolonner, der er afkortet, da funktionen 'pd.set_option()' med maksimal kolonnelængde er aktiveret nu.
Vi kan endda nulstille visningsindstillingen, fordi når vi har indstillet skærmlængden til maksimum, fortsætter den med at vise DataFrames med alle kolonnerne i den pågældende Python-fil. Til dette bruger vi Pandas 'pd.reset_option()'. Vi aktiverer denne funktion og angiver 'display.max_columns' som parameter for denne funktion.

Dette giver os de indledende visningsindstillinger for den medfølgende DataFrame.
Konklusion
At se det komplette output på terminalen med et enormt datasæt får os nogle gange i problemer, når værktøjets standardindstillinger står i kontrast til brugerens behov. For at løse dette tilbageslag giver Pandas os metoden 'pd.set_option()'. I denne læringsvejledning introducerede vi dig til denne metode og behovet for at anvende den. Vi demonstrerede emnet med de praktisk kompilerede og udførte Python-eksempelkoder. Vi har gengivet resultaterne af illustrationen udført på 'Spyder'. Vi forklarede, hvordan man viser alle kolonnerne i DataFrame på konsollen ved at ændre standardindstillingerne samt nulstille alle indstillinger til initial. At give en fuldt fokuseret opmærksomhed på den praktiske implementering af modulet gør det muligt for dig at bruge det, når du støder på sådanne problemer.