Metoden 'Series.to_csv()' i Pandas udsender det angivne serieobjekt i en kommasepareret værdi (csv) notation. Denne funktion tager simpelthen værdierne fra en serie og ændrer deres format ved at tilføje kommaer til adskillelse af indeks- og kolonneværdier.
For at bruge denne funktion skal vi bruge følgende syntaks:

Denne artikel vil give dig to forskellige teknikker til at lære måder at anvende denne metode i et python-program.
Eksempel # 1: Brug af Series.to_csv()-metoden til at konvertere en serie med DatetimeIndex til kommaseparerede værdier
For at ændre en serie til et CSV-format, bruger vi funktionen 'Series.to_csv()'. Denne illustration vil generere en serie med et DatetimeIndex og derefter konvertere det til et kommasepareret værdiformat.
For at sætte denne metode i drift skal vi have et værktøj, der understøtter python-programmering. 'Spyder'-værktøjet er valgt til at kompilere koderne. For at skrive scriptet på det lancerede vi først det installerede værktøj i vores system. Python-programmet har brug for et bibliotek til at udøve sine metoder til at opnå det ønskede resultat. Biblioteket, vi har indlæst her, er 'Pandas'. I den samme kodelinje er dette biblioteks alias identificeret som 'pd'. Så uanset hvor i programmet, skal vi skrive 'pandaer' for at få adgang til en funktion. Vi ville i stedet skrive 'pd'.
Det første trin for at starte med koden er at generere en Pandas-serie. Vi skal skrive 'pd' for at bruge serieoprettelsesmetoden fra pandaer. Funktionen 'pd.Series()' kaldes for at konstruere en serie med de angivne værdier. De værdier, vi har givet for serien, er 'Istanbul', 'Izmir', 'Ankara', 'Ankara', 'Antalya', 'Konya' og 'Bursa'. Hvis du vil give et navn til denne række af værdier, kan du gøre det ved at bruge parameteren 'navn'. Her har vi navngivet denne række af værdier 'Byer', da den har navnene på 6 byer. For at gemme denne serie er der oprettet et serieobjekt 'Tyrkiet'.
For at oprette et DatetimeIndex har vi påberåbt 'pd.date_range()' metoden. Mellem parenteserne af denne funktion har vi sendt 4 argumenter, som er: 'start', 'freq', 'perioder' og 'tz'.
'Start'-argumentet bruger en dato og et klokkeslæt for at begynde at generere et datointerval ud fra det. Her har vi angivet startdato og -tidspunkt som '2022-03-02 02:30'. Parameteren 'freq' klassificerer frekvensen for datointervallet. Så vi forsynede den med værdien 'D'. Nu vil det oprette et datointerval på daglig frekvens. Argumentet 'periode' er sat til '6', hvilket betyder, at det vil generere et datointerval i 6 dage. Den sidste parameter er 'tz', som angiver tidszonen for det angivne område. Vi har specificeret tidszonen for 'Asien/Istanbul'.
For at gemme dette datointerval har vi oprettet en variabel 'Datetime'. For at indstille DatetimeIndex har vi brugt egenskaben 'Series.index'. Navnet på serien 'Turkey' er forsynet med egenskaben '.index' og tildelt den det dato- og tidsinterval, der er gemt i 'Datetime'-variablen. Således vil 'indeks'-egenskaben tage værdierne fra 'Datetime'-variablen og gøre dem til indekslisten for 'Turkey'-serien. Til sidst, for at se output-serien, har vi brugt 'print()'-metoden og givet 'Turkey'-serien som input til den for at vise dens indhold.
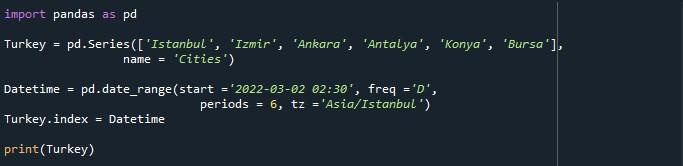
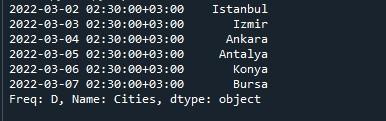
Vi trykkede bare på 'Kør fil' for at udføre scriptet. Som følge heraf kan vi se en serie med DatetimeIndex, der starter fra '2022-03-02 02:30:00+03:00' og slutter ved '2022-03-07 02:30:00+03:00', hvilket skaber en periode på 6 dage. Under serien er 'Freq :D', navnet på arraylisten 'Cities' og dtype 'objekt' også nævnt.
Nu vil vi lære at konvertere denne serie, som vi lige har set i snapshotet ovenfor, til et CSV-format. For at ændre serien til kommaseparerede værdier har vi en metode leveret af pandas-modulet, som er 'Series.to_csv()'. Denne metode tager værdierne fra den angivne serie og tilføjer kommaer mellem kolonnens værdier.
Funktionen 'Series.to_csv()' kaldes. Navnet på den serie, som vi ønsker at konvertere, er nævnt med metoden som 'Turkey.to_csv()'. For at bevare de kommaseparerede værdier har vi oprettet en variabel 'Comma_Separated' og derefter sat dens indhold på outputvinduet ved at aktivere funktionen 'print()'.

Her er vores serie i csv-format. Vi kan se på snapshottet, at indeks- og serieværdierne er blevet adskilt ved hjælp af kommaerne i dem.

Eksempel #2: Brug af Series.to_csv()-metoden til at konvertere en serie med NaN-værdier til kommaseparerede værdier
Den anden teknik til at udøve 'Series.to_csv()'-metoden er at anvende denne metode til at konvertere en serie, der indeholder nogle null-indgange, til et CSV-format.
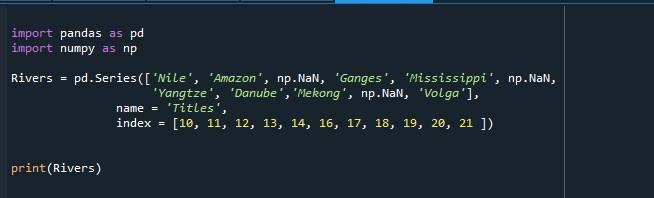
Vi har i første omgang importeret de nødvendige pakker. 'pd' er lavet til et alias for pandaer og 'np' som et alias for numpy. Numpy-værktøjssættet er indlæst her, fordi vi vil lave nogle nul-indtastninger i vores serie ved hjælp af 'np.NaN', mens vi opretter det ved hjælp af pandas 'pd.Series()'-metoden.
Funktionen 'pd.Series()' aktiveres til at bygge en pandaserie med disse værdier: 'Nile', 'Amazon', np.NaN, 'Ganges', 'Mississippi', 'np.NaN', 'Yangtze', 'Donau', 'Mekong', 'np.NaN' og 'Volga'. Der er i alt defineret 21 værdier for serien, hvoraf 3 poster indeholder 'np.NaN' værdier, hvilket betyder, at 3 værdier mangler i serien. Egenskaben 'navn' angiver navnet på denne række af værdier, som vi har givet 'Titler'. Egenskaben 'indeks' bruges til at indstille den brugerdefinerede indeksliste i stedet for at gå med standardlisten.
Her ønsker vi indekslisten med værdierne '10', '11', '12', '13', '14', '16', '17', '18', '19', '20', og 21”. Nu vil vores serie have indekslisten, der starter fra '10' i stedet for '0'. Gem nu denne serie, så vi kan bruge den senere i programmet. Vi har initialiseret et serieobjekt 'Rivers' og tildeler det outputserien, der er genereret ved at kalde 'pd.Series()'-metoden. Serien kan ses ved at vise den ved hjælp af 'print()'-funktionen med python.
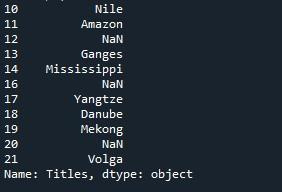
Det gengivne output på terminalen udskrev en serie, hvis indeksliste starter fra 10 og slutter ved 21, hvilket betyder, at serien har 21 værdier.
Serien vil blive transformeret til et CSV-format med 'Series.to_csv()'-metoden.
Vi har påberåbt 'Series.to_csv()'-metoden med vores serie 'Turkey'. Derfor vil denne metode tage værdierne fra 'Tyrkiet'-serien og konvertere dem til et kommasepareret værdiformat. Resultatet gemmes i variablen 'Converted_csv'. Og i sidste ende udskrives den konverterede serie ved hjælp af 'print()'-funktionen.

I snapshot af resultatet nedenfor kan du se, at værdierne i serien nu er ændret på en måde, hvor et komma bruges til at adskille dem fra indekslisten. Desuden, hvor værdierne mangler, er det kun indeksnummeret, der udskrives med komma.

Konklusion
Ændringen af en panda-serie til et CSV-format er en praktisk tilgang. Dette kan opnås ved at bruge pandas 'Series.to_csv()'-funktionen. Denne vejledning bragte i praksis to teknikker til at anvende denne metode. I den første illustration har vi påberåbt denne metode til at konvertere en serie med et DatetimeIndex til et kommasepareret værdiformat. Den 2. forekomst brugte funktionen 'Series.to_csv()' til at ændre en serie med nogle manglende poster til et CSV-format. Begge teknikker er praktisk taget implementeret ved hjælp af 'Spyder'-værktøjet på Windows-operativsystemet.