Eksempel 1: Hent positionen af mønsteret fra strengen ved hjælp af Grep()-funktionen i R
For at udtrække positionen af det specificerede mønster fra strengen, anvendes grep()-funktionen af R.
grep('i+', c('fix', 'split', 'corn n', 'paint'), perl=TRUE, value=FALSE)Her bruger vi grep()-funktionen, hvor '+i'-mønsteret er angivet som et argument, der skal matches inden for vektoren af strenge. Vi indstiller tegnvektorerne, som indeholder fire strenge. Derefter indstiller vi 'perl'-argumentet med TRUE-værdien, som angiver, at R bruger et perl-kompatibelt regulært udtryksbibliotek, og 'value'-parameteren er angivet med 'FALSE'-værdien, som bruges til at hente elementernes indeks. i vektoren, der matcher mønsteret.
'+i'-mønsterpositionen fra hver streng af vektortegn vises i følgende output:

Eksempel 2: Match mønsteret ved hjælp af funktionen Gregexpr() i R
Dernæst henter vi indekspositionen sammen med længden af den bestemte streng i R ved hjælp af gregexpr()-funktionen.
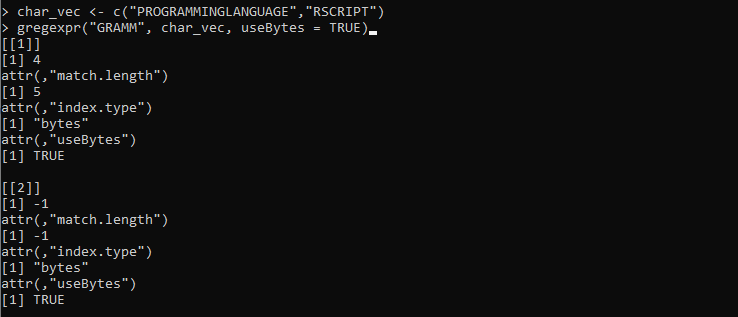
char_vec <- c('PROGRAMMINGLANGUAGE','RSCRIPT')
gregexpr('GRAMM', char_vec, useBytes = TRUE)
Her indstiller vi variablen 'char_vect', hvor strengene er forsynet med forskellige tegn. Derefter definerer vi gregexpr()-funktionen, som tager 'GRAMM'-strengmønsteret til at blive matchet med de strenge, der er gemt i 'char_vec'. Derefter indstiller vi useBytes-parameteren med 'TRUE'-værdien. Denne parameter angiver, at matchningen skal opnås byte-for-byte i stedet for tegn-for-tegn.
Følgende output, der hentes fra funktionen gregexpr() repræsenterer indekserne og længden af begge vektorstrenge:
Eksempel 3: Tæl det samlede antal tegn i streng ved hjælp af funktionen Nchar() i R
nchar()-metoden, som vi implementerer i det følgende, giver os også mulighed for at bestemme, hvor mange tegn der er i strengen:
Res <- nchar('Tæl hvert tegn')print(res)
Her kalder vi nchar()-metoden, som er sat i 'Res'-variablen. Metoden nchar() er forsynet med den lange streng af tegn, som tælles af metoden nchar() og giver antallet af tællertegn i den angivne streng. Derefter sender vi 'Res'-variablen til print()-metoden for at se resultaterne af nchar()-metoden.
Resultatet modtages i følgende output, som viser, at den angivne streng indeholder 20 tegn:

Eksempel 4: Udtræk delstrengen fra strengen ved hjælp af funktionen Substring() i R
Vi bruger substring() metoden med 'start' og 'stop' argumenterne for at udtrække den specifikke understreng fra strengen.
str <- substring('MORNING', 2, 4)print(str)
Her har vi en 'str'-variabel, hvor substring()-metoden kaldes ud. Substring()-metoden tager 'MORNING'-strengen som det første argument og værdien af '2' som det andet argument, der angiver, at det andet tegn fra strengen skal udtrækkes, og værdien af '4'-argumentet indikerer, at det fjerde tegn skal udtrækkes. Substring()-metoden udtrækker tegnene fra strengen mellem den angivne position.
Følgende output viser den udtrukne understreng, som ligger mellem den anden og den fjerde position i strengen:

Eksempel 5: Sammenkæd strengen ved hjælp af funktionen Paste() i R
Paste()-funktionen i R bruges også til strengmanipulation, som sammenkæder de specificerede strenge ved at adskille skilletegnene.
msg1 <- 'Indhold'msg2 <- 'Skriver'
indsæt(msg1, msg2)
Her specificerer vi strengene til henholdsvis 'msg1' og 'msg2' variablerne. Derefter bruger vi paste()-metoden til R til at sammenkæde den angivne streng til en enkelt streng. Paste()-metoden tager strings-variablen som et argument og returnerer den enkelte streng med standardmellemrummet mellem strengene.
Ved udførelse af metoden paste() repræsenterer outputtet den enkelte streng med mellemrummet i den.

Eksempel 6: Rediger strengen ved hjælp af funktionen Substring() i R
Desuden kan vi også opdatere strengen ved at tilføje understrengen eller et hvilket som helst tegn i strengen ved hjælp af substring()-funktionen ved hjælp af følgende script:
str1 <- 'Helte'substring(str1, 5, 6) <- 'ic'
cat(' Modified String:', str1)
Vi indstiller 'Heroes'-strengen inden for 'str1'-variablen. Derefter implementerer vi substring() metoden, hvor 'str1' er specificeret sammen med understrengens 'start' og 'stop' indeksværdier. Substring()-metoden er tildelt 'iz'-understrengen, som er placeret på den position, der er angivet i funktionen for den givne streng. Derefter bruger vi cat()-funktionen af R, som repræsenterer den opdaterede strengværdi.
Outputtet, der viser strengen, opdateres med den nye ved hjælp af substring ()-metoden:

Eksempel 7: Formater strengen ved hjælp af Format()-funktionen i R
Imidlertid inkluderer strengmanipulationsoperationen i R også at formatere strengen i overensstemmelse hermed. Til dette bruger vi format()-funktionen, hvor strengen kan justeres og indstille bredden af den specifikke streng.
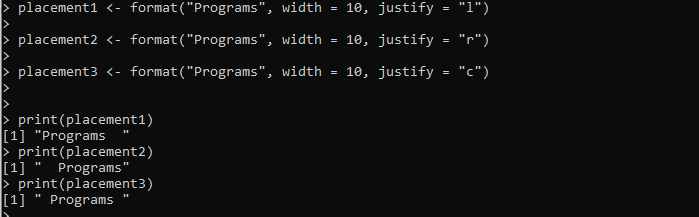
placering1 <- format('Programmer', bredde = 10, juster = 'l')placering2 <- format('Programmer', width = 10, justify = 'r')
placering3 <- format('Programmer', width = 10, justify = 'c')
print (placering1)
print (placering2)
print (placering3)
Her indstiller vi 'placement1'-variablen, som leveres med format()-metoden. Vi sender 'programmer'-strengen, der skal formateres, til format()-metoden. Bredden indstilles, og justeringen af strengen indstilles til venstre ved hjælp af 'justify'-argumentet. På samme måde opretter vi yderligere to variable, 'placement2' og 'placement2', og anvender format()-metoden for at formatere den angivne streng i overensstemmelse hermed.
Outputtet viser tre formateringsstile for den samme streng i det følgende billede, inklusive venstre-, højre- og centerjusteringer:
Eksempel 8: Transform strengen til små og store bogstaver i R
Derudover kan vi også transformere strengen med små bogstaver og store bogstaver ved at bruge funktionerne tolower() og toupper() som følger:
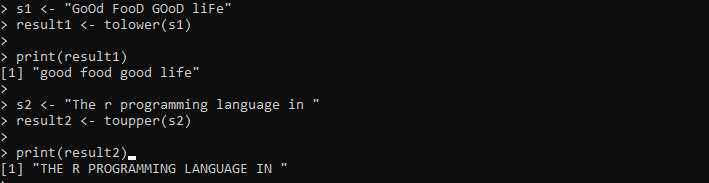
s1 <- 'GOD MAD GODT LIV'resultat1 <- lavere(s1)
print (resultat1)
s2 <- 'Programmeringssproget r i'
resultat2 <- øverste(r2)
print (resultat2)
Her giver vi den streng, der indeholder store og små bogstaver. Derefter holdes strengen i 's1'-variablen. Derefter kalder vi tolower()-metoden og sender 's1'-strengen inde i den for at transformere alle tegnene inde i strengen med små bogstaver. Derefter udskriver vi resultaterne af tolower()-metoden, som er gemt i 'result1'-variablen. Dernæst sætter vi en anden streng i 's2'-variablen, som indeholder alle tegnene med små bogstaver. Vi anvender toupper()-metoden på denne 's2'-streng for at transformere den eksisterende streng til store bogstaver.
Outputtet viser begge strenge i det angivne tilfælde i følgende billede:
Konklusion
Vi lærte de forskellige måder at styre og analysere strengene på, hvilket omtales som strengmanipulation. Vi udtrak karakterens position fra strengen, sammenkædede de forskellige strenge og transformerede strengen til det specificerede tilfælde. Vi formaterede strengen, modificerede strengen, og forskellige andre operationer udføres her for at manipulere strengen.