Datasammenligning i SQL er en almindelig opgave, som enhver databaseudvikler vil støde på lejlighedsvis. Heldigvis kommer datasammenligning i en lang række formater, såsom bogstavelig sammenligning, boolsk sammenligning osv.
Et af de virkelige datasammenligningsscenarier, som du kan støde på, er dog sammenligning mellem to tabeller. Det spiller en afgørende rolle i opgaver som datavalidering, fejlidentifikation, duplikering eller sikring af dataintegritet.
I denne tutorial vil vi udforske alle de forskellige metoder og teknikker, som vi kan bruge til at sammenligne to databasetabeller i SQL.
Eksempel på dataopsætning
Før vi dykker ned i hver af metoderne, lad os opsætte en grundlæggende dataopsætning til demonstrationsformål.
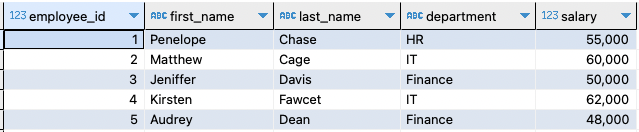
Vi har to tabeller med eksempeldata som vist i eksemplet.
Eksempeltabel 1:
Det følgende indeholder forespørgslerne til oprettelse af den første tabel og indsættelse af eksempeldata i tabellen:
CREATE TABLE sample_tb1 (
medarbejder_id INT PRIMÆR NØGLE AUTO_INCREMENT,
fornavn VARCHAR ( halvtreds ) ,
efternavn VARCHAR ( halvtreds ) ,
afdeling VARCHAR ( halvtreds ) ,
løn DECIMAL ( 10 , 2 )
) ;
INSERT INTO sample_tb1 ( fornavn, efternavn, afdeling, løn )
VÆRDIER
( 'Penelope' , 'Jage' , 'HR' , 55000,00 ) ,
( 'Matthew' , 'Bur' , 'DET' , 60000,00 ) ,
( 'Jeniffer' , 'Davis' , 'Finansiere' , 50000,00 ) ,
( 'Kirsten' , 'Fawcet' , 'DET' , 62000,00 ) ,
( 'Cameron' , 'omkostninger' , 'Finansiere' , 48000,00 ) ;
Dette skulle skabe en ny tabel kaldet 'sample_tb1' med forskellige oplysninger såsom navne, afdeling og løn.
Den resulterende tabel er som følger:

Eksempeltabel 2:
Lad os fortsætte og oprette to eksempeltabeller. Antag, at dette er en sikkerhedskopi af den første tabel. Vi kan oprette tabellen og indsætte et eksempeldata som vist i følgende:
CREATE TABLE sample_tb2 (medarbejder_id INT PRIMÆR NØGLE AUTO_INCREMENT,
fornavn VARCHAR ( halvtreds ) ,
efternavn VARCHAR ( halvtreds ) ,
afdeling VARCHAR ( halvtreds ) ,
løn DECIMAL ( 10 , 2 )
) ;
INSERT INTO sample_tb2 ( fornavn, efternavn, afdeling, løn )
VÆRDIER
( 'Penelope' , 'Jage' , 'HR' , 55000,00 ) ,
( 'Matthew' , 'Bur' , 'DET' , 60000,00 ) ,
( 'Jeniffer' , 'Davis' , 'Finansiere' , 50000,00 ) ,
( 'Kirsten' , 'Fawcet' , 'DET' , 62000,00 ) ,
( 'Audrey' , 'Dekan' , 'Finansiere' , 48000,00 ) ;
Dette skulle oprette en tabel og indsætte eksempeldataene som angivet i den forrige forespørgsel. Den resulterende tabel er som følger:
Sammenlign to tabeller med Undtagen
En af de mest almindelige måder at sammenligne to tabeller i SQL på er at bruge operatoren EXCEPT. Dette finder de rækker, der findes i den første tabel, men ikke i den anden tabel.
Vi kan bruge det til at udføre en sammenligning med eksempeltabellerne som følger:
VÆLG *FRA sample_tb1
UNDTAGEN
VÆLG *
FRA sample_tb2;
I dette eksempel returnerer operatoren EXCEPT alle distinkte rækker fra den første forespørgsel (sample_tb1), som ikke vises i den anden forespørgsel (sample_tb2).
Sammenlign to tabeller ved hjælp af Union
Den anden metode, vi kan bruge, er UNION-operatoren i forbindelse med GROUP BY-sætningen. Dette hjælper med at identificere de poster, der findes i den ene tabel, ikke i den anden, samtidig med at de duplikerede poster bevares.
Tag den forespørgsel, der er vist i følgende:
VÆLGMedarbejder-ID,
fornavn,
efternavn,
afdeling,
løn
FRA
(
VÆLG
Medarbejder-ID,
fornavn,
efternavn,
afdeling,
løn
FRA
sample_tb1
UNION ALLE
VÆLG
Medarbejder-ID,
fornavn,
efternavn,
afdeling,
løn
FRA
sample_tb2
) AS kombinerede_data
GRUPPE EFTER
Medarbejder-ID,
fornavn,
efternavn,
afdeling,
løn
AT HAVE
TÆLLE ( * ) = 1 ;
I det givne eksempel bruger vi UNION ALL-operatoren til at kombinere dataene fra begge tabeller, mens vi beholder dubletterne.
Vi bruger derefter GROUP BY-sætningen til at gruppere de kombinerede data efter alle kolonnerne. Til sidst bruger vi HAVING-klausulen til at sikre, at kun de poster med et antal på én (ingen dubletter) er valgt.
Produktion:

Denne metode er lidt mere kompleks, men den giver en meget bedre indsigt, da du får de faktiske data, der mangler fra begge tabeller.
Sammenlign to tabeller ved hjælp af INNER JOIN
Hvis du har tænkt, hvorfor så ikke bruge en INNER JOIN? Du ville være på punkt. Vi kan bruge en INNER JOIN til at sammenligne tabellerne og finde de fælles poster.
Tag for eksempel følgende forespørgsel:
VÆLGsample_tb1. *
FRA
sample_tb1
INNER JOIN sample_tb2 TIL
sample_tb1.employee_id = sample_tb2.employee_id;
I dette eksempel bruger vi en SQL INNER JOIN til at finde de poster, der findes i begge tabeller baseret på en given kolonne. Selvom dette virker, kan det nogle gange være vildledende, da du ikke er sikker på, om dataene faktisk mangler eller findes i begge tabeller eller kun i den ene.
Konklusion
I denne tutorial lærte vi om alle de metoder og teknikker, som vi kan bruge til at sammenligne to tabeller i SQL.