Håndtering af omfangsrige datamængder kan være en opadgående opgave for dataadministratorer, primært hvis dine forespørgsler eller scanningsresultater løber ind på flere sider. Paginering i DynamoDB gør det muligt for databasen at håndtere de store datamængder ved at opdele resultaterne i flere håndterbare sider. Denne opskrivning forklarer DynamoDB-pagineringen og giver forskellige mulige use cases og eksempler. Det fremhæver også, hvordan pagineringen i DynamoDB adskiller sig fra pagineringen i andre databaser.
Hvad er sideinddeling i DynamoDB?
Generelt er paginering, afledt af ordet sider, en teknik, der bruges af databaser til at opdele dataposterne i flere bidder, segmenter eller sider. Og da AWS DynamoDB understøtter lagring af store mængder data, har den pålidelige pagineringsfunktioner.
DynamoDB-pagineringskomponenten sikrer, at du kun kan hente op til 1 GB data pr. scanning eller forespørgsel. Selvom det er en standardindstilling, kan du tilføje en grænseparameter i en forespørgsel for at angive en grænse. Du kan yderligere angive en grænse for antallet af poster i hver scanningsforespørgsel.
Især er der nogle få forskelle mellem paginering i DynamoDB og paginering i en typisk SQL-database. Mest åbenlyst kommer hver pagineret post, der hentes i DynamoDB, med en direkte omkostning, hvilket gør dette til en uskreven regel, når man bruger pagineringen i DynamoDB. Denne funktion gør paginering til en afgørende faktor for at begrænse både de hentede poster og direkte omkostninger.
Sådan bruger du sideinddeling i DynamoDB
1. Sideinddeling under en forespørgselsoperation
I DynamoDB returnerer en forespørgsel kun resultater på op til 1 MB. Men du kan effektivt bekræfte, om der er flere resultater, ved at granske dine resultater. Navnlig indeholder et forespørgselsoperationsresultat på lavt niveau et LastEvaluatedKey-element, som ikke er null for at angive, at der er flere elementer relateret til din forespørgsel, som du bør hente.
Et resultat uden et LastEvaluatedKey-element, som ikke er null, indebærer, at alle de elementer, der matcher forespørgslen, passer inden for grænsen på 1 MB, og der er ikke flere elementer til hentning. Du kan selvfølgelig også sætte en grænse for antallet af varer pr. resultat. Se følgende eksempelkommando:
aws dynamodb forespørgsel \
--tabelnavn MitTabelnavn \
--nøgle-betingelse-udtryk 'Partitionsnøgle = :pk \
--expression-attribute-values '{' :pk ':{' S ':' a1234b '}},
--grænse 10 \
Du kan bruge den forrige kommando til at forespørge i din tabel om elementerne med de samme nøglebetingelsesudtryksværdier. Lad os søge i vores 'Ordre'-tabel for ordre_id'er fra Darry Tech. Vi sætter også en grænse til 10 varer pr. side. En anden mulighed for parameteren –limit er at bruge parameteren –page-size til samme formål.
Paginering er en automatisk handling i AWS CLI for elementer under 1 MB data. Du kan tilføje en eksklusiv startnøgle til kommandoen, hvis du ønsker, at din forespørgsel skal starte fra en bestemt ordre.
Svaret ser således ud:
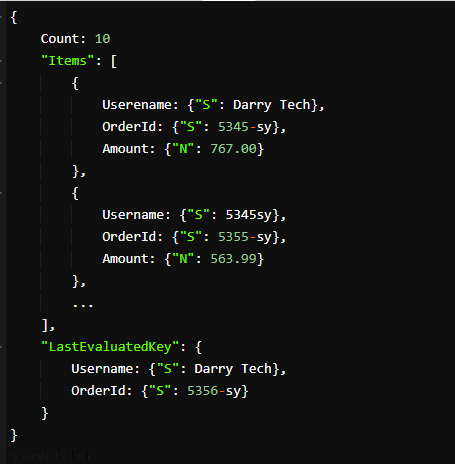
De leverede resultater viser 10 Darry Tech på den første side. Du kan bruge LastEvaluatedKey-værdierne til at få flere ordrer, der matcher udtryksnøgleværdierne for din søgning, for at konstruere en ny forespørgsel. Den nye forespørgselsanmodning indeholder LastEvaluatedKey-værdierne i ExclusiveStartKey-parameteren.
Et eksempel på syntaksen er vist i følgende:
aws dynamodb forespørgsel \--tabelnavn EksempelTabel \
--nøgle-betingelse-udtryk 'Partitionsnøgle = :pk \
--expression-attribute-values '{' :pk ':{' S ': Darry Tech' \
--grænse 10 \
--eksklusiv-start-nøgle '{' Partitionsnøgle ':{' S ': Darry Tech' }, 'Sorteringsnøgle' :{ 'S' : '5356' }} '
Den forrige kommando producerer de næste modregningsordrer på den næste side, startende med det ordre-id, der har den angivne primærnøgle, dvs. {“PartitionKey”:{“S”: Darry Tech”},”SortKey”:{“S”: ”5356-sy”}}.
2. Paginering under scanning
Det er også muligt at bruge pagineringen til scanningsoperationer. Alt fungerer på samme måde som med forespørgselskommandoerne. Du skal dog bruge attributten filter-expression. Kommandoen ser ud som, hvad vi har her:
aws dynamodb scanning \--tabelnavn MyTable \
--filter-udtryk 'Attributnavn = :værdi' \
--udtryk-attribut-værdier '{':value':{'S':'ABC123'}}' \
--begrænse tyve \
--eksklusiv-start-nøgle '{'PartitionKey':{'S':'ABC123'},'SortKey':{'S':'XYZ987'}}'
Den forrige kommando henter op til 20 elementer pr. side fra MyTable-tabellen, startende med det element, hvis primære nøgle er {“PartitionKey”: “ABC123”, “SortKey”: “XYZ987”}. Den filtrerer resultaterne til kun at inkludere de elementer, hvor attributten AttributeName har værdien 'ABC123'.
I svaret er LastEvaluatedKey feltet indeholder den primære nøgle for det sidste element i resultatsættet. Du kan bruge denne værdi som ExclusiveStartKey i en efterfølgende scanning handling for at hente den næste side med resultater.
Konklusion
Sideinddeling i DynamoDB forbedrer håndteringen af data. Det er dog vigtigt at vide, om dine systemer vil drage fordel af paginering. Det er nødvendigt at bruge paginering, hvis du har en lang liste af elementer i en applikation. Mens den medfølgende illustration fokuserer på AWS CLI-kaldet, kan du også bruge paginering med AWS SDK'er såsom Pythons Boto3 eller enhver SDK, du foretrækker.