Denne artikel vil diskutere, hvordan man bruger Elasticsearch multi-get API til at hente flere JSON-dokumenter baseret på deres ID'er. Derudover giver Elasticsearch dig mulighed for at bruge en enkelt get-forespørgsel til at hente dokumenterne fra indekser ved kun at bruge dokument-id'erne.
Lad os udforske.
Anmod om syntaks
Følgende er syntaksen for Elasticsearch multi-get API:
GET /_mget
GET /
Multi-get API'et understøtter flere indekser, som giver dig mulighed for at hente dokumenterne, selvom de ikke er i samme indeks.
Anmodningen understøtter følgende stiparametre:
-
– Navnet på det indeks, hvorfra dokumenterne skal hentes som angivet af deres ID'er.
Du kan også angive de andre forespørgselsparametre som vist:
- Præference – Definerer den foretrukne node eller shard.
- Realtid – Hvis indstillet til sand, udføres handlingen i realtid.
- Opdater – Tvinger operationen til at opdatere målskårene, før de angivne dokumenter hentes.
- Routing – En værdi, der bruges til at dirigere operationerne til et bestemt shard.
- Store_felter – Henter dokumentfelterne, der er gemt i et indeks i stedet for dokumentet.
- _kilde – En boolsk værdi, der definerer, om anmodningen skal returnere feltet _source eller ej.
Forespørgslen kræver brødteksten, som indeholder følgende værdier:
- Dokumenter – Angiver de dokumenter, du ønsker at hente. Derudover understøtter dette afsnit følgende attributter:
- _id – Unikt ID for måldokumentet.
- _indeks – Indekset, der indeholder måldokumentet.
- Routing – Nøglen til dokumentets primære shard.
- _kilde – Hvis det er sandt, inkluderer det alle kildefelter; ellers udelukker det dem.
- _lagrede_felter – De lagrede_felter, som du ønsker at inkludere.
- Ids – Id'erne for de dokumenter, du ønsker at hente.
Eksempel 1: Hent flere dokumenter fra det samme indeks
Følgende eksempel viser, hvordan du bruger Elasticsearch multi-get API til at hente dokumenter med specifikke id'er fra Netflix-indekset:
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: rapportering' -H 'Content-Type: application/json' -d'{
'dokumenter': [
{
'_id': 'T3wnVoMBck2AEzXPytlJ'
},
{
'_id': 'W3wnVoMBck2AEzXPytlJ'
}
]
}'
Den givne anmodning skal hente dokumenterne med de angivne id'er fra Netflix-indekset. Det resulterende output er som vist:
{'dokumenter': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_version': 1,
'_seq_no': 0,
'_primary_term': 1,
'fundet': sandt,
'_source': {
'varighed': '90 min',
'listed_in': 'Dokumentarer',
'country': 'USA',
'date_added': '25. september 2021',
'show_id': 's1',
'director': 'Kirsten Johnson',
'release_year': 2020,
'rating': 'PG-13',
'description': 'Da hendes far nærmer sig slutningen af sit liv, iscenesætter filmskaberen Kirsten Johnson sin død på opfindsomme og komiske måder for at hjælpe dem begge med at se det uundgåelige i øjnene.'
'type': 'Film',
'title': 'Dick Johnson er død'
}
},
{
'_index': 'netflix',
'_id': 'W3wnVoMBck2AEzXPytlJ',
'_version': 1,
'_seq_no': 12,
'_primary_term': 1,
'fundet': sandt,
'_source': {
'country': 'Tyskland, Tjekkiet',
'show_id': 's13',
'director': 'Christian Schwochow',
'release_year': 2021,
'rating': 'TV-MA',
'description': 'Efter at det meste af hendes familie er blevet myrdet i en terrorbombning, bliver en ung kvinde ubevidst lokket til at slutte sig til netop den gruppe, der dræbte dem.'
'type': 'Film',
'title': 'Jeg er Karl',
'varighed': '127 min',
'listed_in': 'Dramaer, internationale film',
'cast': 'Luna Wedler, Jannis Niewöhner, Milan Peschel, Edin Hasanović, Anna Fialová, Marlon Boess, Victor Boccard, Fleur Geffrier, Aziz Dyab, Mélanie Fouché, Elizaveta Maximová',
'date_added': '23. september 2021'
}
}
]
}
Vi kan også forenkle anmodningen ved at placere dokument-id'erne i et simpelt array som vist i følgende:
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: rapportering' -H 'Content-Type: application/json' -d'{
'ids': ['T3wnVoMBck2AEzXPytlJ', 'W3wnVoMBck2AEzXPytlJ']
}'
Den tidligere anmodning bør udføre en lignende handling.
Eksempel 2: Hent dokumenterne fra flere indekser
I det følgende eksempel henter anmodningen flere dokumenter fra forskellige indekser som vist:
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: rapportering' -H 'Content-Type: application/json' -d'{
'dokumenter': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ'
},
{
'_index': 'disney',
'_id': '8j4wWoMB1yF5VqfaKCE4'
}
]
}'
Det resulterende output er som vist:

Eksempel 3: Ekskluder specifikke felter
Vi kan ekskludere specifikke felter fra en given anmodning ved at bruge parametrene source_include og source_exclude.
Et eksempel er som vist:
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: rapportering' -H 'Content-Type: application/json' -d'{
'dokumenter': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_source': falsk
},
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_source': {
'include': [ 'listed_in', 'release_year', 'title' ],
'exclude': [ 'beskrivelse', 'type', 'date_added' ]
}
}
]
}'
Den givne anmodning bruger kildeinkludering og ekskludering til at angive, hvilke felter du ønsker at hente i et givet dokument.
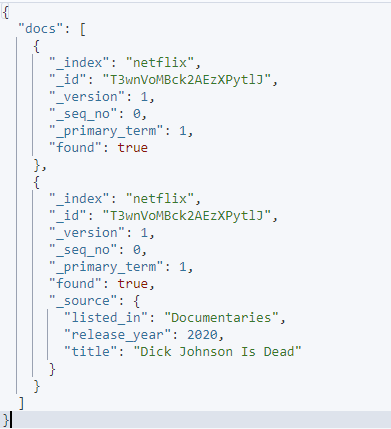
Det resulterende output er som vist:
Konklusion
I dette indlæg diskuterede vi det grundlæggende ved at arbejde med Elasticsearch multi-get API, som giver dig mulighed for at hente flere dokumenter fra forskellige kilder baseret på deres ID'er. Du er velkommen til at udforske de andre dokumenter for mere information.
God kodning!