Denne vejledning vil forklare listecrawlere i AWS.
Hvad er liste-crawlere i AWS?
En Crawler er en komponent i AWS-limen, som bruges til at gennemsøge dataplaceringen og udlede denne information tilbage til kataloget. De oplysninger, som en crawler indsamler, kan være datatyper af data, skemastruktur, eller med andre ord, den indsamler metadata. Crawler kan også bruges sammen med datakataloget, som bruges, når data flyttes ind i Glue-økosystemet, mens der bruges ETL-job osv.
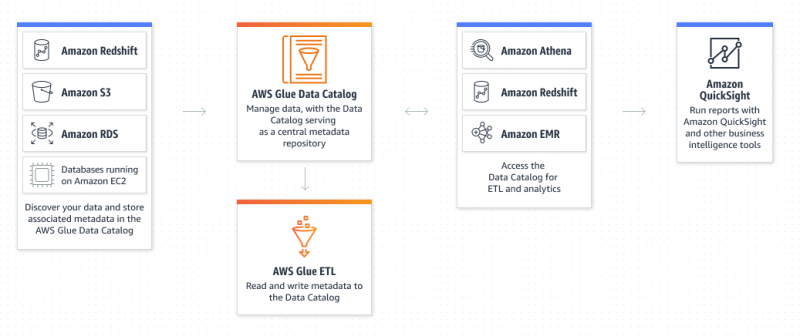
Hvad er Amazon Glue Service?
AWS Glue er en Amazon Extract Transform and Load-tjeneste, som giver brugeren mulighed for at organisere, lokalisere, flytte og transformere alle data. AWS Glue er serverløs, da brugeren ikke behøver at klargøre og konfigurere serverne eller administrere livscyklusser. Datakatalog og crawlere er komponenterne i AWS Glue, der fungerer som det vedvarende metadatalager:

Hvordan opretter man en crawler på AWS?
For at oprette en crawler på AWS skal du besøge AWS Glue-tjenesten fra AWS Management Console:
Gå ind i ' Crawlere ” side ved at klikke på dens navn fra venstre panel:
Klik på ' Opret crawler ” knap:
Indtast navnet på webcrawleren og klik på ' Næste ” knap:
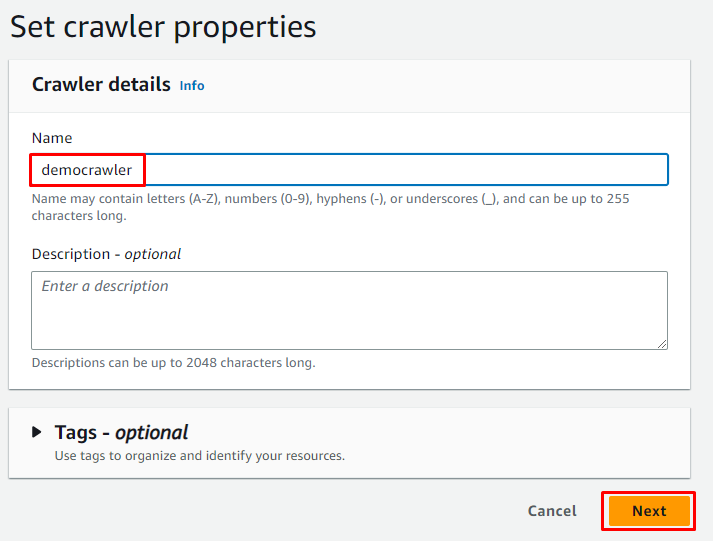
Vælg kortlægningsmuligheden for limtabeller og klik på ' Tilføj en kilde knappen for at hente data fra:

Vælg S3-tjenesten og klik på ' Gennemse S3 knappen for at få kildens placering:

Du skal blot vælge mappen S3 og klikke på ' Vælge ” knap:

Når placeringen er tilføjet til kilden, skal du blot klikke på ' Tilføj en S3-datakilde ” knap:
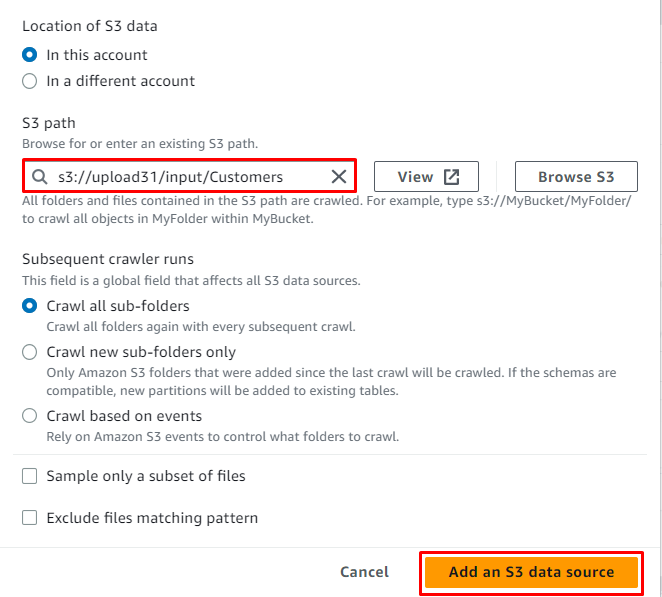
Klik på ' Næste ” knap:

Klik på ' Opret ny IAM-rolle '-knappen fra ' Konfigurer sikkerhedsindstillinger ” afsnit:
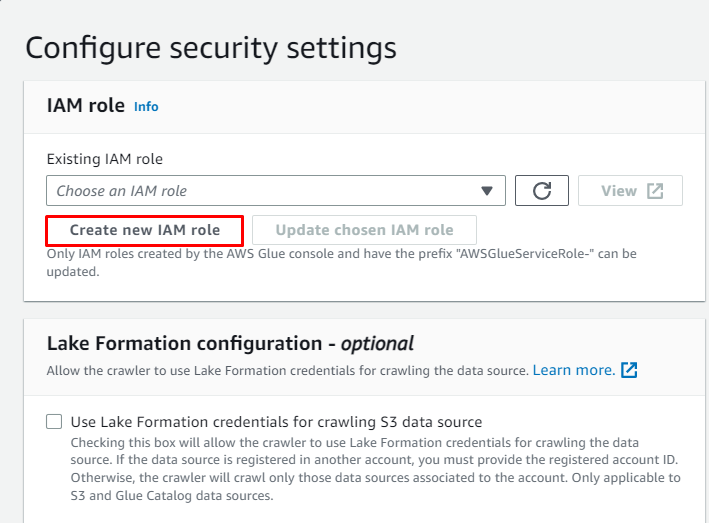
Indtast rollens navn og klik på ' skab ” knap:
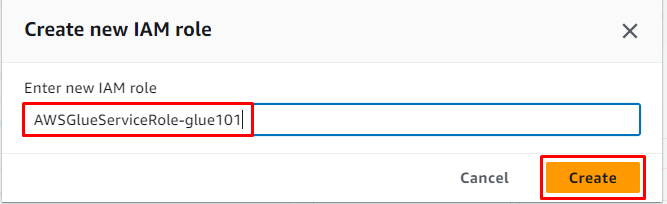
Derefter skal du blot klikke på ' Næste ” knap:

Vælg måldatabasen og skriv det navn, der skal bruges til tabellen:
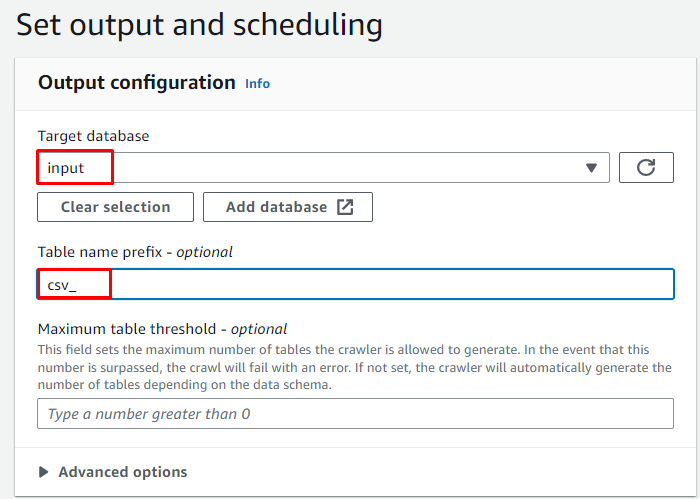
Planlæg webcrawleren til ' På efterspørgsel ' og klik på ' Næste ” knap:
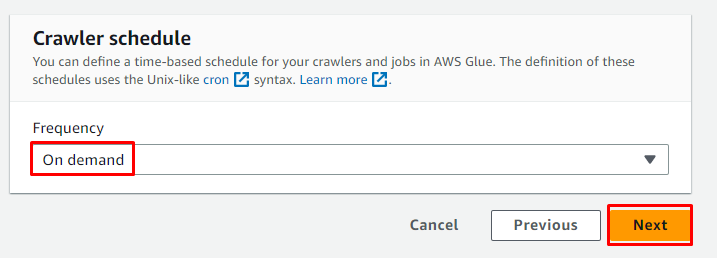
Gennemgå konfigurationen og klik på ' Opret crawler ” knap:
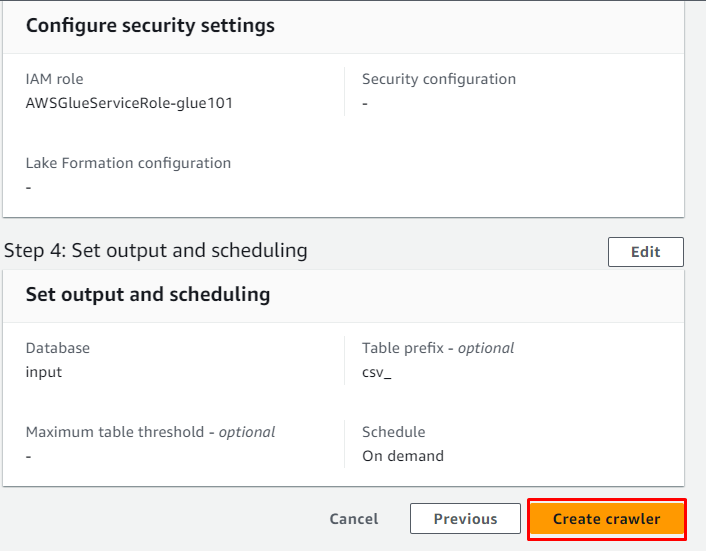
Webcrawleren er blevet oprettet, og den kan bruges til at hente data fra kilden ved at klikke på ' Løb ” knap:

Det handler om listecrawlerne i AWS.
Konklusion
ListCrawler er komponenten i AWS Glue-tjenesten, som kan bruges til at crawle information fra kilder og vende tilbage til kataloget. Datakataloger og crawlere kan bruges til at indsamle data for at få information om de data, som er kendt som metadata. Brugeren kan også oprette en crawler fra AWS Glue for at hente data fra S3-tjenesten eller andre kilder og placere oprettelsestabeller i databasen. Denne guide har forklaret ListCrawlerne i AWS, og hvordan man opretter dem.