Hvordan bruger man et samtalebuffervindue i LangChain?
Konversationsbuffervinduet bruges til at opbevare de seneste beskeder fra samtalen i hukommelsen for at få den seneste kontekst. Den bruger værdien af K'et til at gemme meddelelserne eller strengene i hukommelsen ved hjælp af LangChain-rammerne.
For at lære processen med at bruge samtalebuffervinduet i LangChain skal du blot gennemgå følgende guide:
Trin 1: Installer moduler
Start processen med at bruge samtalebuffervinduet ved at installere LangChain-modulet med de nødvendige afhængigheder til at bygge samtalemodeller:
pip installer langkæde
Installer derefter OpenAI-modulet, der kan bruges til at bygge de store sprogmodeller i LangChain:
pip installer openai
Nu, opsætte OpenAI-miljøet for at bygge LLM-kæderne ved hjælp af API-nøglen fra OpenAI-kontoen:
importere du
importere getpass
du . rundt regnet [ 'OPENAI_API_KEY' ] = getpass . getpass ( 'OpenAI API-nøgle:' )
Trin 2: Brug af samtalebuffervinduets hukommelse
For at bruge samtalebuffervinduets hukommelse i LangChain skal du importere ConversationBufferWindowMemory bibliotek:
fra langkæde. hukommelse importere ConversationBufferWindowMemoryKonfigurer hukommelsen ved hjælp af ConversationBufferWindowMemory () metode med værdien af k som argument. Værdien af k'et vil blive brugt til at beholde de seneste beskeder fra samtalen og derefter konfigurere træningsdataene ved hjælp af input- og outputvariablerne:
hukommelse = ConversationBufferWindowMemory ( k = 1 )hukommelse. gem_kontekst ( { 'input' : 'Hej' } , { 'produktion' : 'Hvordan har du det' } )
hukommelse. gem_kontekst ( { 'input' : 'Jeg er god hvad med dig' } , { 'produktion' : 'ikke meget' } )
Test hukommelsen ved at kalde load_memory_variables () metode til at starte samtalen:
hukommelse. load_memory_variables ( { } ) 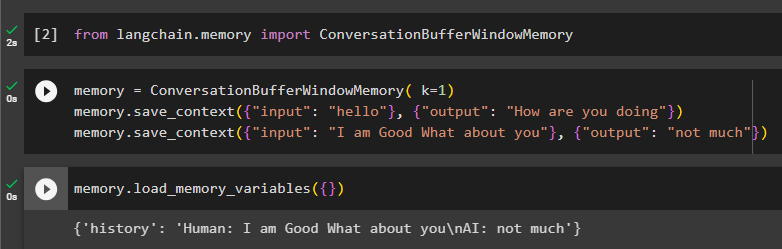
For at få historikken for samtalen skal du konfigurere ConversationBufferWindowMemory()-funktionen ved hjælp af return_beskeder argument:
hukommelse = ConversationBufferWindowMemory ( k = 1 , return_beskeder = Rigtigt )hukommelse. gem_kontekst ( { 'input' : 'Hej' } , { 'produktion' : 'hvad så' } )
hukommelse. gem_kontekst ( { 'input' : 'ikke meget du' } , { 'produktion' : 'ikke meget' } )
Ring nu til hukommelsen ved hjælp af load_memory_variables () metode til at få svaret med samtalens historie:
hukommelse. load_memory_variables ( { } ) 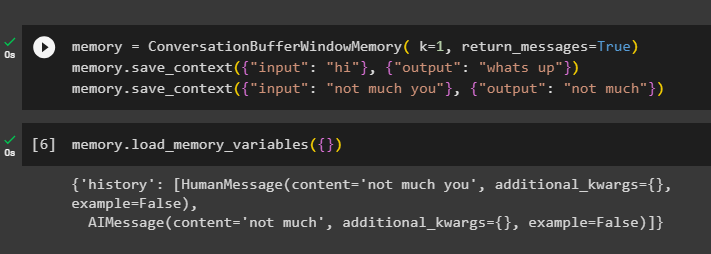
Trin 3: Brug af buffervindue i en kæde
Byg kæden ved hjælp af OpenAI og Samtalekæde biblioteker og konfigurer derefter bufferhukommelsen til at gemme de seneste beskeder i samtalen:
fra langkæde. kæder importere Samtalekædefra langkæde. llms importere OpenAI
#building resumé af samtalen ved hjælp af flere parametre
samtale_med_oversigt = Samtalekæde (
llm = OpenAI ( temperatur = 0 ) ,
#building memory buffer ved hjælp af dens funktion med værdien k til at gemme seneste beskeder
hukommelse = ConversationBufferWindowMemory ( k = 2 ) ,
#configure verbose variabel for at få mere læsbart output
ordrig = Rigtigt
)
samtale_med_oversigt. forudsige ( input = 'Hej hvad så' )
Fortsæt nu samtalen ved at stille spørgsmålet relateret til output fra modellen:
samtale_med_oversigt. forudsige ( input = 'Hvad er deres problemer' ) 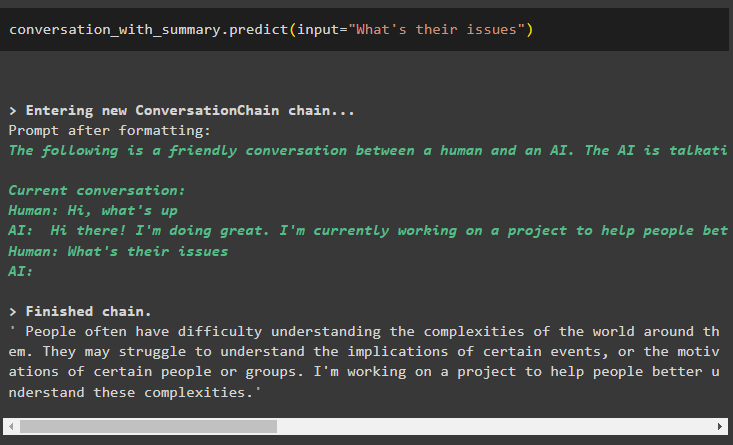
Modellen er konfigureret til kun at gemme én tidligere besked, som kan bruges som kontekst:
samtale_med_oversigt. forudsige ( input = 'Går det godt' ) 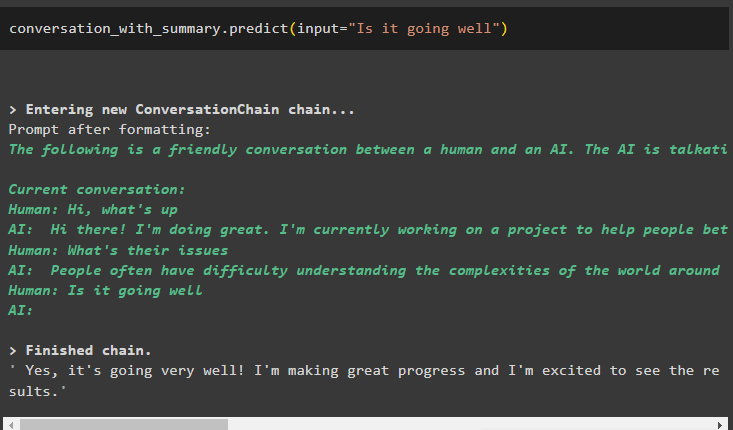
Spørg efter løsningen på problemerne, og outputstrukturen vil blive ved med at glide buffervinduet ved at fjerne de tidligere meddelelser:
samtale_med_oversigt. forudsige ( input = 'Hvad er løsningen' ) 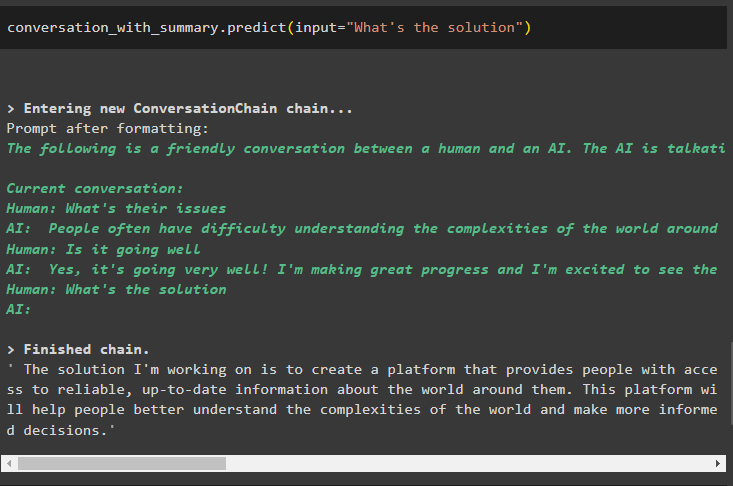
Det handler om processen med at bruge samtalebuffervinduerne LangChain.
Konklusion
For at bruge samtalebuffervinduets hukommelse i LangChain skal du blot installere modulerne og opsætte miljøet ved hjælp af OpenAI's API-nøgle. Byg derefter bufferhukommelsen ved at bruge værdien af k for at beholde de seneste beskeder i samtalen for at bevare konteksten. Bufferhukommelsen kan også bruges med kæder til at sætte gang i samtalen med LLM eller kæden. Denne vejledning har uddybet processen med at bruge samtalebuffervinduet i LangChain.