I denne artikel vil vi diskutere, hvordan man tildeler FORSKELLIGE hukommelse via ' pytorch_cuda_alloc_conf ” metode.
Hvad er metoden 'pytorch_cuda_alloc_conf' i PyTorch?
Grundlæggende er ' pytorch_cuda_alloc_conf ” er en miljøvariabel inden for PyTorch-rammen. Denne variabel muliggør en effektiv styring af de tilgængelige behandlingsressourcer, hvilket betyder, at modellerne kører og producerer resultater på mindst mulig tid. Hvis det ikke gøres korrekt, vil ' FORSKELLIGE ' beregningsplatformen vil vise ' ikke mere hukommelse ” fejl og påvirker kørselstid. Modeller, der skal trænes over store mængder data eller har store ' batchstørrelser ” kan producere runtime fejl, fordi standardindstillingerne måske ikke er nok til dem.
Det ' pytorch_cuda_alloc_conf ' variabel bruger følgende ' muligheder ” for at håndtere ressourceallokering:
- hjemmehørende : Denne mulighed bruger de allerede tilgængelige indstillinger i PyTorch til at allokere hukommelse til den igangværende model.
- max_split_size_mb : Det sikrer, at enhver kodeblok, der er større end den angivne størrelse, ikke opdeles. Dette er et stærkt værktøj til at forhindre ' fragmentering ”. Vi vil bruge denne mulighed til demonstrationen i denne artikel.
- roundup_power2_divisions : Denne mulighed runder størrelsen af tildelingen op til nærmeste ' magt 2 ” division i megabyte (MB).
- roundup_bypass_threshold_mb: Det kan runde tildelingsstørrelsen op for enhver anmodning med mere end den angivne tærskel.
- affaldsindsamlingsgrænse : Det forhindrer latens ved at bruge tilgængelig hukommelse fra GPU'en i realtid for at sikre, at genindvindings-all-protokollen ikke startes.
Hvordan tildeles hukommelse ved hjælp af metoden 'pytorch_cuda_alloc_conf'?
Enhver model med et betydeligt datasæt kræver yderligere hukommelsesallokering, der er større end den, der er angivet som standard. Den tilpassede allokering skal specificeres under hensyntagen til modelkravene og tilgængelige hardwareressourcer.
Følg nedenstående trin for at bruge ' pytorch_cuda_alloc_conf ” metode i Google Colab IDE til at allokere mere hukommelse til en kompleks maskinlæringsmodel:
Trin 1: Åbn Google Colab
Søg på Google Samarbejdende i browseren og opret en ' Ny notesbog ” for at begynde at arbejde:
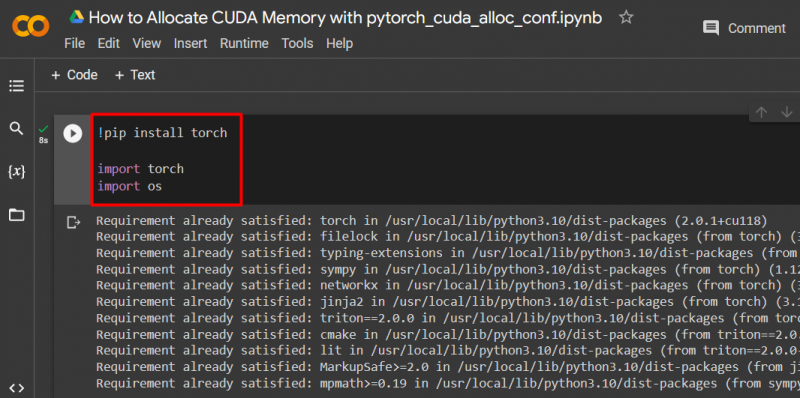
Trin 2: Konfigurer en brugerdefineret PyTorch-model
Opsæt en PyTorch-model ved at bruge ' !pip ' installationspakke for at installere ' fakkel ' biblioteket og ' importere ' kommando for at importere ' fakkel ' og ' du ” biblioteker ind i projektet:
import lommelygte
import os
Følgende biblioteker er nødvendige for dette projekt:
- Fakkel – Dette er det grundlæggende bibliotek, som PyTorch er baseret på.
- DU - Det ' operativ system ' bibliotek bruges til at håndtere opgaver relateret til miljøvariabler som ' pytorch_cuda_alloc_conf ” samt systembiblioteket og filtilladelserne:
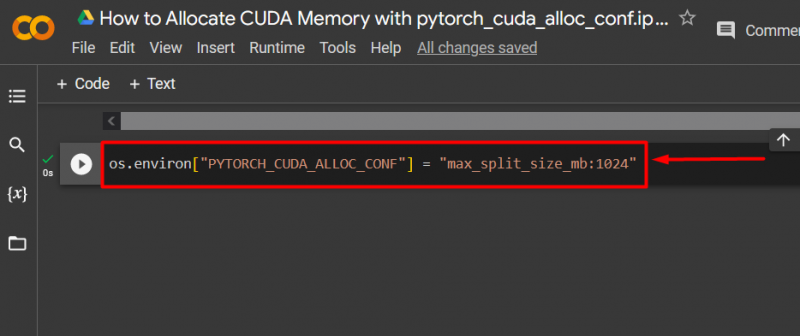
Trin 3: Tildel CUDA-hukommelse
Brug ' pytorch_cuda_alloc_conf ” metode til at angive den maksimale opdelte størrelse ved hjælp af “ max_split_size_mb ”:
Trin 4: Fortsæt med dit PyTorch-projekt
Efter at have specificeret ' FORSKELLIGE ' pladstildeling med ' max_split_size_mb ' mulighed, fortsæt med at arbejde på PyTorch-projektet som normalt uden frygt for ' ikke mere hukommelse ' fejl.
Bemærk : Du kan få adgang til vores Google Colab notesbog her link .
Pro-Tip
Som tidligere nævnt er ' pytorch_cuda_alloc_conf ”-metoden kan tage enhver af de ovenfor angivne muligheder. Brug dem i henhold til de specifikke krav til dine deep learning-projekter.
Succes! Vi har lige demonstreret, hvordan man bruger ' pytorch_cuda_alloc_conf ' metode til at angive en ' max_split_size_mb ” for et PyTorch-projekt.
Konklusion
Brug ' pytorch_cuda_alloc_conf ”-metode til at allokere CUDA-hukommelse ved at bruge en af dens tilgængelige muligheder i henhold til kravene til modellen. Disse muligheder er hver især beregnet til at afhjælpe et bestemt behandlingsproblem i PyTorch-projekter for bedre køretider og mere jævn drift. I denne artikel har vi vist syntaksen for at bruge ' max_split_size_mb ” mulighed for at definere den maksimale størrelse af opdelingen.