Lad os se på iconv-værktøjet til Linux i dens terminalkonsol nu. Så vi har udført instruktionen 'iconv' med '-l' flaget for at vise alle de kendte og mest brugte kodede tegnsæt på vores terminalskærm. Det vil vise de kodede tegnsæt sammen med deres aliaser. Du kan se en lang liste over kodede tegnsæt efter at have scrollet lidt ned.
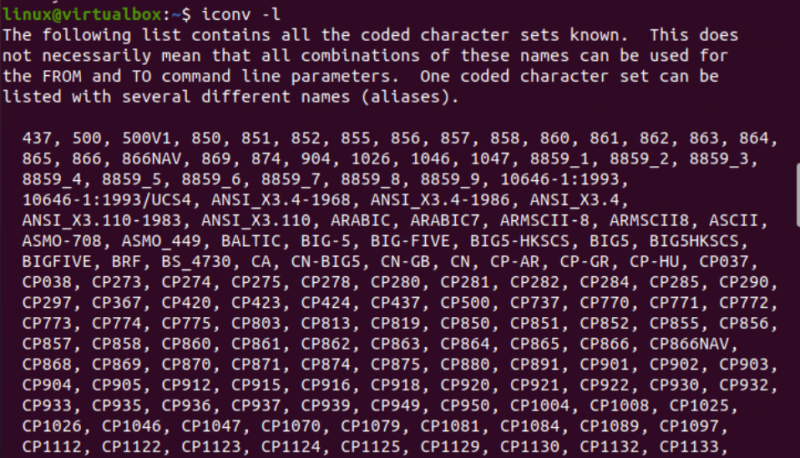
Nu er det tid til at komme i gang med implementeringen af iconv-kommandoen i Linux. For det første har vi brug for forskellige typer filer i vores system for at konvertere en type fil til en anden type. Således bruger vi 'touch'-forespørgslen på konsolterminalen til at oprette tre forskellige filer, dvs. Java-type, C-type og teksttype. Med en liste over det aktuelle biblioteksindhold vil du finde de nyligt genererede filer i den.
Efter dette vil vi se på typen af hver fil separat ved hjælp af 'fil'-forespørgslen sammen med navnet på hver fil. Denne forespørgsel kræver '-I'-indstillingen for at vise typen af kodningstegnsæt for hver fil separat. Hvis du har glemt at bruge '-I'-indstillingen, skal du bruge '—mime'-flaget i stedet. Både '-I' og '—mime' flag fungerer på samme måde.
Nu, efter at have udført 'fil'-instruktionen for 'txt'-filen, fik vi 'US-ASCII'-tegntypekodningen. Mens du bruger den samme instruktion til Java- og C-filerne, viser den, at begge filer indeholder 'BINÆR' tegntypekodning. Sammen med det viser denne instruktion, at alle disse tre filer er tomme.
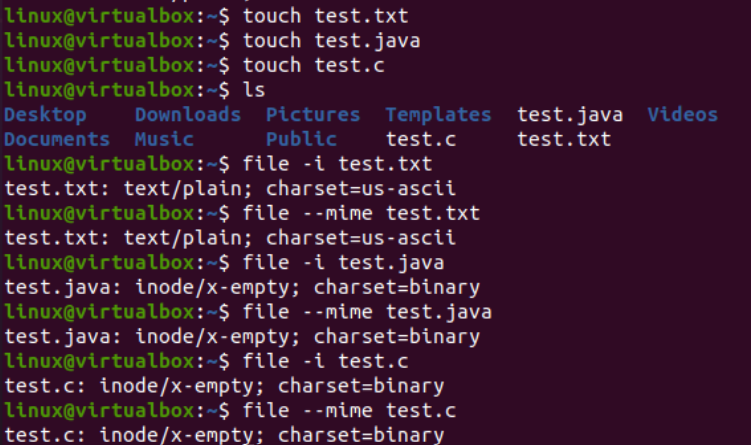
Nu vil vi illustrere brugen af iconv-instruktion på konsollen til at konvertere en specifik tegnsætkodningsfil til en anden tegnsætkodning. Før det skal vi tilføje noget kode eller data til vores filer. Derfor har vi tilføjet Java-koden i 'text.java'-filen, C-koden i 'text.c'-filen og tilføjet tekstdata i 'test.txt'-filen. Katteforespørgslen blev brugt her til at vise indholdet af alle tre filer, som præsenteret nedenfor:
Nu hvor vi har tilføjet dataene med succes, vil vi se tegnsættets kodning af disse filer igen. Så vi har prøvet den samme filinstruktion i skallen med '-I' flaget og filnavnene, dvs. test.txt, test.java og test.c. Kørsel af disse tre instruktioner separat for alle tre filer viser, at tegnsætkodningen er blevet opdateret for Java- og C-filerne, mens den forbliver den samme for tekstfilen, dvs. US-ASCII. Kodningen af Java- og C-filer var tidligere 'binær'; nu er det 'US-ASCII'. Det viser også, at tekstfilen indeholder almindelig tekstdata, mens de to andre kodefiler indeholder scripts som indhold.

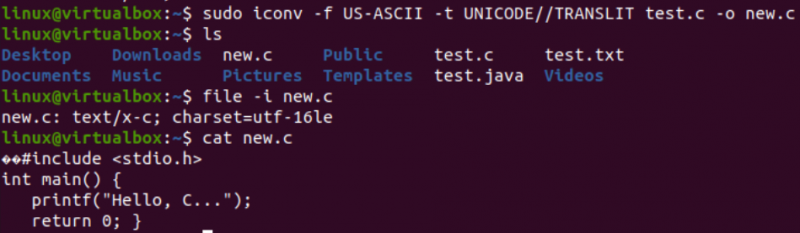
Det er tid til at udføre den egentlige opgave, der er nødvendig for denne artikel, dvs. konvertere en kodning til en anden ved hjælp af iconv-kommandoen i skallen. Vi har således brugt 'iconv'-instruktionen i shell-terminalen med 'sudo'-rettighederne. Denne kommando tager '-f'-indstillingen står for 'fra', og '-t'-indstillingen står for 'til', dvs. fra en kodning til en anden.
Efter '-f'-indstillingen skal du angive den kodning, din fil allerede har, dvs. US-ASCII. Mens du efter '-t'-indstillingen skal angive den kodning, du vil erstatte med den gamle kodning, dvs. UNICODE. Du skal angive navnet på en fil, der bruges som en kilde med -o-indstillingen for at oprette dens objektbillede. Objektbilledet ville være en anden fil, dvs. 'new.c', af samme type, men med den nye kodning og de samme data.
Efter at have udført følgende instruktion, vil du få en ny fil i samme mappe, dvs. i henhold til 'ls'-forespørgslen. Nu vil vi tjekke for tegnsættets kodning af en ny fil genereret ved hjælp af iconv-instruktionen. Vi vil igen bruge 'fil'-instruktionen med '-I'-indstillingen og det nye filnavn, dvs. new.c.
Du vil se, at tegnsættet for denne nye fil har været forskelligt fra tegnsættet i en gammel fil, dvs. UTF-16LE-tegnsættet. Dette skyldes, at vi har oversat US-ASCII-kodningen til UNICODE-kodningen ved hjælp af iconv-instruktionen til vores new.c-fil. 'cat'-forespørgslen viste den samme C-kode i filen, men startede med nogle Unicode-tegn, som allerede præsenteret.
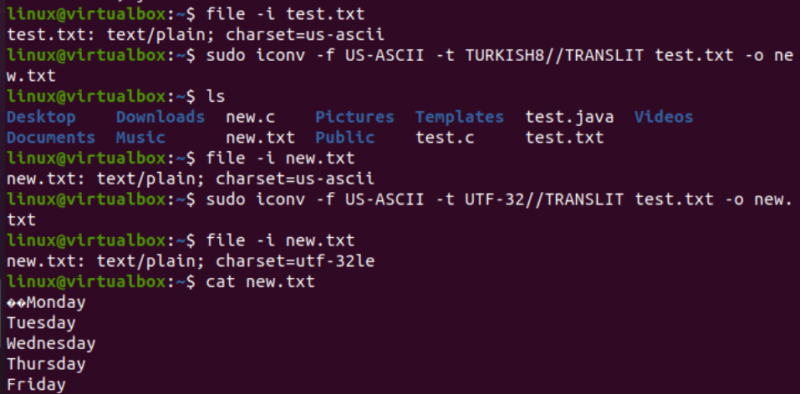
På en meget lignende måde vil vi ændre kodningen af test.txt-tekstfilen. Filinstruktionen viser, at den har en US-ASCII-tegnsætkodning. Iconv-kommandoen er blevet brugt med det samme format til at konvertere kodningen af test.txt-filen fra US-ASCII til TURKISH8. Du vil se, at det ikke ændrer US-ASCII til tyrkisk.
Efter dette brugte vi den samme kommando til at dække US-ASCII til UTF-32 tegnsætkodning for den samme fil. Denne gang virker det. Dette skyldes, at der nogle gange kan være et problem med at konvertere et kodningssæt til et andet, eller at den anden kodning muligvis ikke understøtter det.
Konklusion
Denne artikel diskuterede, hvordan man bruger iconv Linux-instruktionerne til at konvertere et kodningstegnsæt til et andet ved hjælp af deres aliaser. På denne måde var vi nødt til at oprette nogle filer af forskellige typer.