Procedure
Denne artikel viser en praktisk demonstration af metoden til at oprette implementeringen til Kubernetes. For at arbejde med Kubernetes skal vi først sikre os, at vi har en platform, hvor vi kan køre Kubernetes. Disse platforme omfatter: Google cloud platform, Linux/Ubuntu, AWS osv. Vi kan bruge enhver af de nævnte platforme til at køre Kubernetes med succes.
Eksempel #01
Dette eksempel viser, hvordan vi kan oprette en implementering i Kubernetes. Før vi går i gang med Kubernetes-implementeringen, skal vi først oprette en klynge, da Kubernetes er en open source-platform, der bruges til at styre og orkestrere udførelsen af applikationerne af containerne på tværs af flere computerklynger. Klyngen til Kubernetes har to forskellige typer ressourcer. Hver ressource har sin funktion i klyngen, og disse er 'kontrolplanet' og 'knuderne'. Kontrolplanet i klyngen fungerer som leder for Kubernetes klyngen.
Dette koordinerer og administrerer enhver mulig aktivitet i klyngen fra planlægningen af applikationerne, vedligeholdelse eller om den ønskede tilstand af applikationen, styring af den nye opdatering og også effektiv skalering af applikationerne.
Kubernetes-klyngen har to noder i sig. Noden i klyngen kan enten være en virtuel maskine eller computeren i blank metalform (fysisk), og dens funktionalitet er at fungere, som maskinen arbejder for klyngen. Hver knude har sin kubelet, og den kommunikerer med kontrolplanet for Kubernetes-klyngen og administrerer også knudepunktet. Så, klyngens funktion, når vi implementerer en applikation på Kubernetes, fortæller vi indirekte kontrolplanet i Kubernetes-klyngen om at starte containerne. Derefter får kontrolplanet containerne til at køre på Kubernetes-klyngernes noder.
Disse noder koordinerer derefter med kontrolplanet gennem Kubernetes API, som eksponeres af kontrolpanelet. Og disse kan også bruges af slutbrugeren til interaktionen med Kubernetes-klyngen.
Vi kan implementere Kubernetes-klyngen enten på fysiske computere eller virtuelle maskiner. Til at starte med Kubernetes kan vi bruge Kubernetes implementeringsplatform 'MiniKube', som gør det muligt at arbejde med den virtuelle maskine på vores lokale systemer og er tilgængelig for ethvert operativsystem som Windows, Mac og Linux. Det giver også bootstrapping-operationer såsom start, status, sletning og stop. Lad os nu oprette denne klynge og oprette den første Kubernetes-implementering på den.
Til udrulningen vil vi bruge den Minikube, vi har forudinstalleret minikuben i systemerne. Nu, for at begynde at arbejde med det, vil vi først kontrollere, om minikuben fungerer og er korrekt installeret, og for at gøre dette i terminalvinduet skal du skrive følgende kommando som følger:
$ minikube versionResultatet af kommandoen vil være:

Nu vil vi gå videre og forsøge at starte minikuben uden kommando som
$ start minikube 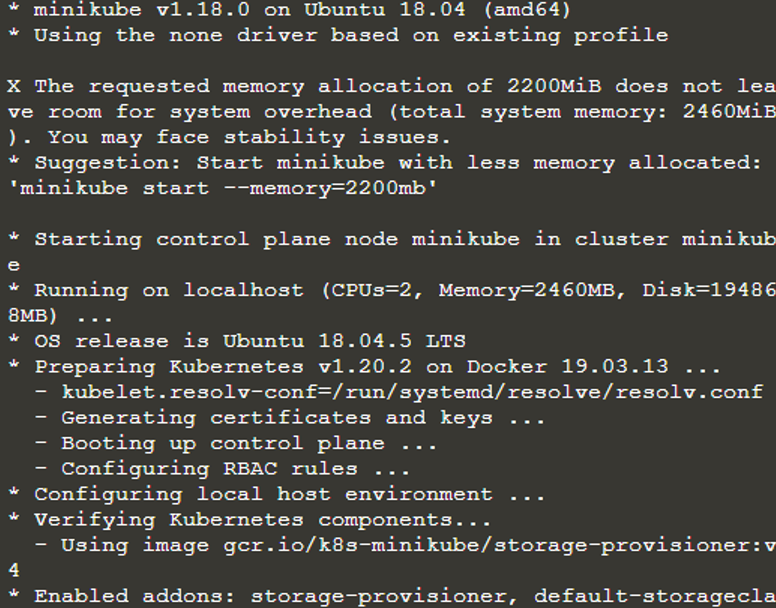
Efter ovenstående kommando har minikuben nu startet en separat virtuel maskine, og i den virtuelle maskine kører en Kubernetes-klynge nu. Så vi har en kørende Kubernetes-klynge i terminalen nu. For at lede efter eller vide om klyngeinformationen, vil vi bruge kommandogrænsefladen 'kubectl'. Til det vil vi kontrollere, om kubectl er installeret ved at skrive kommandoen 'kubectl version'.
$ kubectl version 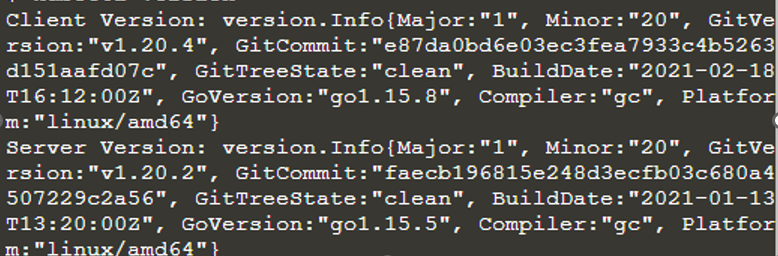
kubectl er installeret og konfigureret. Det giver også information om klienten og serveren. Nu kører vi Kubernetes-klyngen, så vi kan vide om dens detaljer ved at bruge kommandoen kubectl som 'kubectl-klynge-info'.
$ kubectl klynge-info 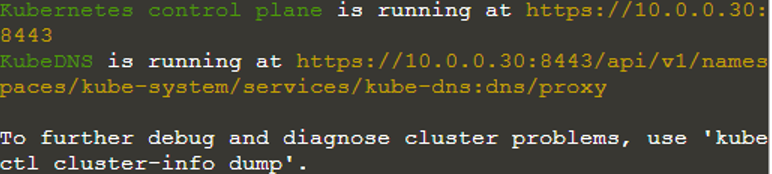
Lad os nu se efter noderne i Kubernetes-klyngen ved at bruge kommandoen 'kubectl get nodes'.
$ kubectl få noder 
Klyngen har kun én node, og dens status er klar, hvilket betyder, at denne node nu er klar til at acceptere ansøgningerne.
Vi vil nu oprette en implementering ved hjælp af kubectl-kommandolinjegrænsefladen, som omhandler Kubernetes API og interagerer med Kubernetes-klyngen. Når vi opretter en ny implementering, skal vi angive applikationens image og antallet af kopier af applikationen, og dette kan kaldes og opdateres, når vi har oprettet en implementering. For at oprette den nye implementering, der skal køre på Kubernetes, skal du bruge kommandoen 'Kubernetes create deployment'. Og til dette skal du angive navnet på implementeringen og også billedplaceringen for applikationen.

Nu har vi implementeret en ny applikation, og ovenstående kommando har ledt efter den node, som applikationen kan køre på, hvilket kun var en i dette tilfælde. Få nu listen over implementeringerne ved hjælp af kommandoen 'kubectl get deployments', og vi vil have følgende output:
$ kubectl få implementeringer 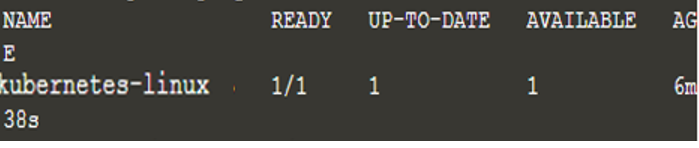
Vi vil se applikationen på proxy-værten for at udvikle en forbindelse mellem værten og Kubernetes-klyngen.
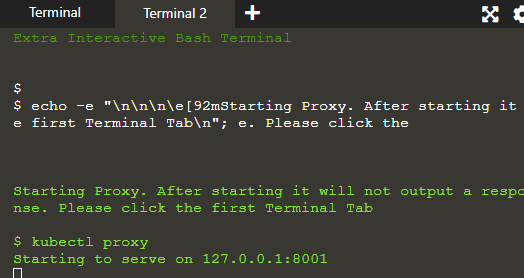
Proxyen kører i den anden terminal, hvor kommandoerne givet i terminal 1 udføres og deres resultat vises i terminal 2 på serveren: 8001.
Poden er udførelsesenheden for en Kubernetes-applikation. Så her vil vi angive pod-navnet og få adgang til det via API.

Konklusion
Denne vejledning diskuterer metoderne til at oprette implementeringen i Kubernetes. Vi har kørt implementeringen på Minikube Kubernetes-implementeringen. Vi lærte først at oprette en Kubernetes-klynge, og derefter ved at bruge denne klynge oprettede vi en implementering til at køre den specifikke applikation på Kubernetes.