“Comma-Separated Values (CSV) er et af de mest alsidige og brugervenlige dataformater. Det er et let dataformat, der giver udviklere og applikationer mulighed for at overføre og parse data fra en kilde til en anden.
CSV-data gemmer data i et tabelformat, hvor hver kolonne er adskilt af et komma, og en ny post tildeles en ny linje. Dette gør det til et meget godt valg til eksport af databaser såsom SQL-databaser, Cassandra-data og mere.
Det er derfor ingen overraskelse, at du vil støde på et scenarie, hvor du skal importere en CSV-fil til din database.
Målet med denne tutorial er at vise dig en hurtig og enkel metode til at importere en CSV-fil til din Elasticsearch-klynge ved hjælp af Kibana-dashboardet.'
Lad os springe ind.
Krav
Før du dykker ind, skal du sikre dig, at du har følgende krav:
- En Elasticsearch-klynge med grøn sundhedsstatus.
- Kibana-server tilsluttet din Elasticsearch-klynge.
- Tilstrækkelige tilladelser til at administrere indekser på din klynge.
Eksempel på CSV-fil
Som sædvanlig er det første krav din kilde-CSV-fil. Det er godt at sikre, at dataene i din CSV-fil er velformateret, og at den ikke indeholder fejl.
Til illustrationsformål vil vi bruge et gratis datasæt, der indeholder film og tv-shows fra Amazon Prime.
Åbn din browser og naviger til ressourcen nedenfor:
https://www.kaggle.com/datasets/shivamb/amazon-prime-movies-and-tv-shows
Følg proceduren for at downloade datasættet til din lokale maskine. Du kan udpakke det downloadede arkiv med kommandoen:
$ unzip a~ / Downloads / archive.zip
Importer CSV-fil
Når du har din kildefil klar, kan vi fortsætte og diskutere, hvordan du importerer den.
Start med at gå over til dit Kibana-hjem-dashboard og vælge muligheden 'upload en fil'.
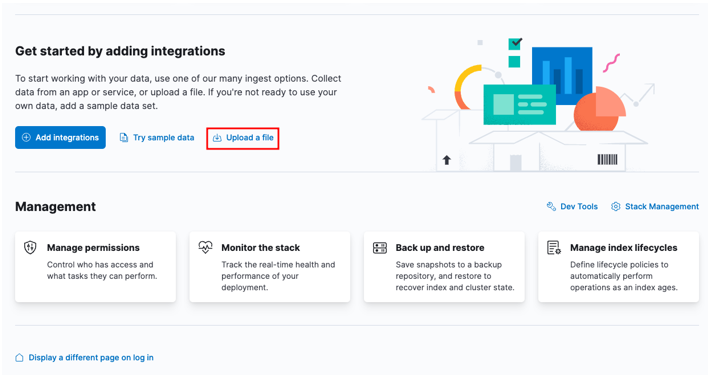
Find den CSV-målfil, du ønsker at importere, i startvinduet.
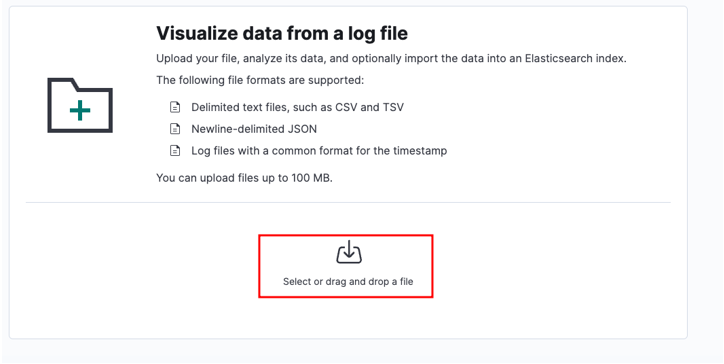
Vælg din kildefil, og klik på upload.
Tillad, at Elasticsearch og Kibana analyserer den uploadede fil. Dette vil analysere CSV-filen og bestemme dataformatet, felter, datatyper osv.
BEMÆRK: Afhængigt af din klyngekonfiguration og datastørrelsen kan denne proces tage et stykke tid. Sørg for, at masternoden reagerer for at undgå timeouts.
Når processen er afsluttet, bør du få en prøve af dit filindhold og filstatistikken som analyseret af Elastic.
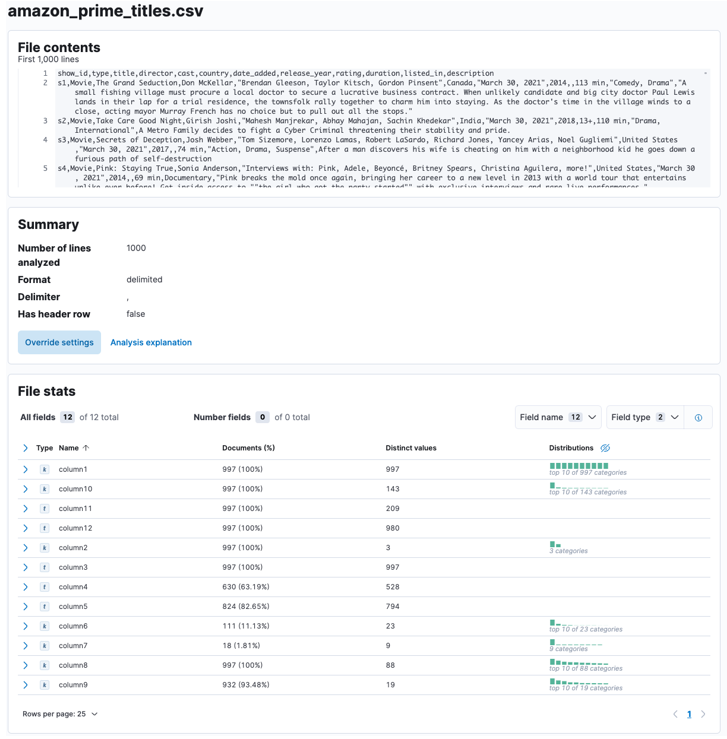
Du kan skræddersy adskillige parametre, for eksempel skilletegn, overskriftsrækker osv. For eksempel kan vi tilpasse outputtet ovenfor for at fortælle Elastic, at vores CSV-fil indeholder overskriftsfiler.
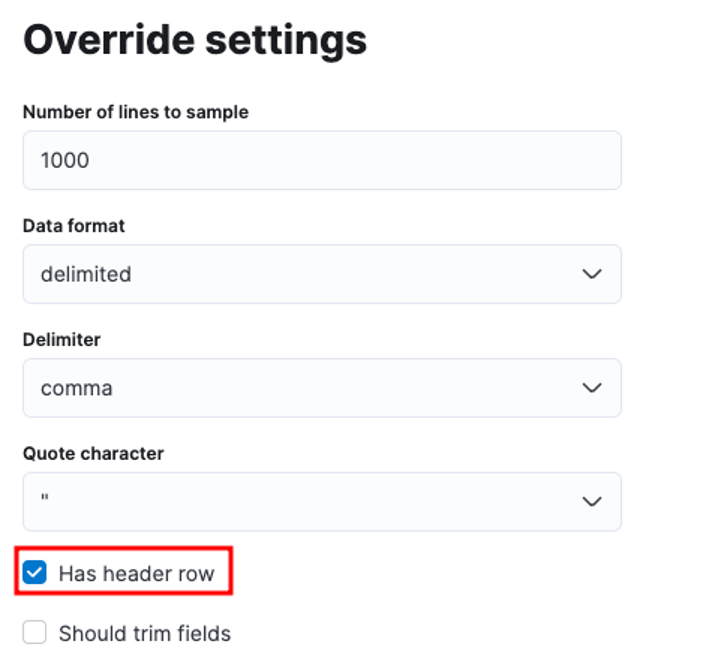
Vi kan derefter klikke på anvend og genanalysere dataene. Dette bør formatere dataene i det korrekte format, inklusive felterne.
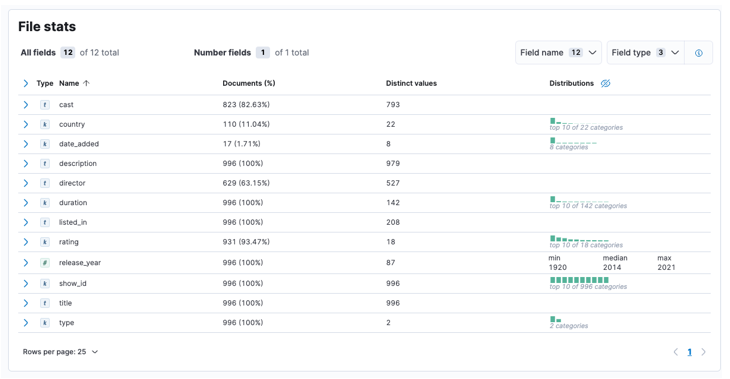
Dernæst kan vi klikke på import for at fortsætte til det importerede dashboard.
Her skal vi lave et indeks, hvori CSV-dataene gemmes. Du kan tildele et hvilket som helst understøttet navn til dit indeks.
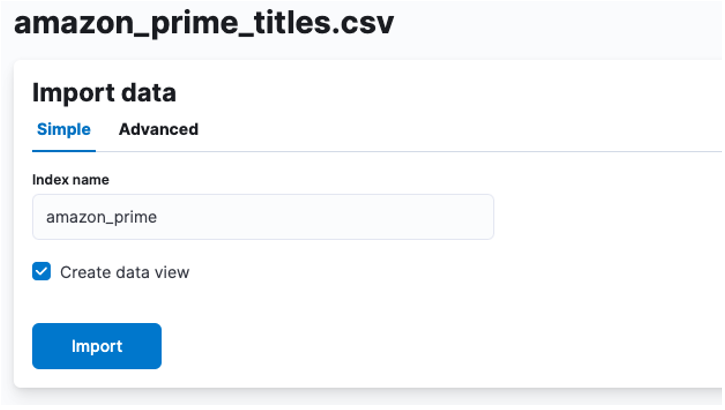
Hvis du ønsker at tilpasse dine indeksegenskaber, såsom antallet af shards, replikaer, kortlægninger osv. Vælg den avancerede mulighed og juster dine indstillinger som dit hjerte ønsker.
Til sidst skal du klikke på import og se, mens Kibana gør sin 'magi'. Når du er færdig, kan du få adgang til dit indeks enten via Elasticsearch API eller bruge Kibana-dashboardet.
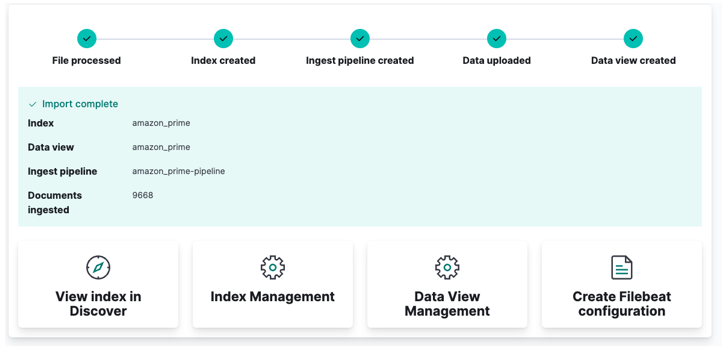
Og du er færdig!!
Konklusion
I dette indlæg dækkede vi processen med at hente og importere dit CSV-datasæt til din Elasticsearch-klynge ved hjælp af Kibana-dashboardet.
Tak fordi du læste og god kodning!!