Køl (Knowledge Extraction based on Evolutionary Learning) er et Java-baseret softwareværktøj, der er specialiseret i implementering af evolutionære algoritmer. Da det er en open source, giver det en bred vifte af videnopdagelsesalgoritmer, der kan bruges i eksperimenter, der driver data mining- og analysefællesskabet. Det giver en enkel og brugervenlig grafisk brugergrænseflade, der væsentligt reducerer den samlede kompleksitet af dette værktøj. De fleste lignende værktøjer på markedet kræver, at brugerne interagerer med dem ved at skrive koden, mens Keel fjerner dette krav ved at levere en intuitiv GUI, der kan bruges af både begyndere og eksperter.
Keel leverer en bred vifte af forskellige beregningsmæssige intelligens-baserede algoritmer, herunder klassificering, regression, feature-ekstraktion, mønsteranalyse, clustering og mere. Med mainstream-modeller bagt lige ind i selve applikationen er Keel et meget nyttigt værktøj, når det kommer til at udføre undersøgende dataanalyser på rådatasæt. Dens enkle træk-og-slip-grænseflade parret med den lette funktionalitetsudnyttelse giver mulighed for hurtig og effektiv datamining-eksperimentering til både uddannelses- og forskningsformål. Værktøjer som Keel er stigende i popularitet på grund af deres forenklede tilgang til ellers komplekse algoritmiske praksisser.
Installation
Der er to hovedmåder, hvorpå vi kan installere Køl på enhver Linux-maskine. Den første involverer at gå til Køl hjemmeside og downloade softwaren derfra. Den anden, som vi vil følge i denne installationsvejledning, kræver, at vi downloader Keel ved hjælp af wget downloadværktøj tilgængeligt for Linux-brugere.
1. Vi starter med at få wget på vores Linux-maskine.
Kør følgende kommando for at downloade wget ved hjælp af passende pakke manager:
$ sudo apt-get install wget
Du vil se en lignende terminaludgang:
2. Nu hvor vi har wget værktøj installeret på vores Linux-maskine, bruger vi det til at downloade Køl værktøj.
Dette er link at vi går over til wget.
Kør følgende kommando i din terminal:
$ wget http: // sci2s.ugr.es / køl / software / prototyper / åben version / Software- 2018 -04-09.zip
Du bør se et lignende output på din terminal:
Når Keel er færdig med at downloade, kan vi fortsætte med resten af installationen.
3. Vi udpakker nu den komprimerede fil, som vi downloadede i det forrige trin ved hjælp af Linux Unzip-værktøjet.
Kør følgende kommando:
$ unzip Software- 2018 -04-09.zip
Du bør se et lignende output i terminalen:
4. Naviger ind i Keel-mappen ved at køre følgende kommando:
$ cd Software- 2018 -04-09 / Dokumenter / eksperimenter / KØL / dist /
5. Kør følgende kommando for at starte med installationen:
$ java -krukke . / GraphInterKeel.jar
Med dette skulle Keel være tilgængelig for dig at bruge på din Linux-maskine.
Brugervejledning
Interagere med Køl applikationen er virkelig nem og enkel. Lad os starte med at importere Iris datasæt ind i vores arbejdsplads.
Når vi importerer dataene, viser værktøjet os den overordnede gruppering af datapunktet i datasættet. Det viser os også de forskellige klasser, der er til stede i datasættet, sammen med de grundlæggende oplysninger, såsom de numeriske områder, som disse datapunkter spænder over, og den overordnede varians og middelværdier, de præsenterer. Denne information giver brugerne mulighed for bedre at forstå, hvordan man går videre med dataforberedelsen til enhver form for dataanalyseopgave.
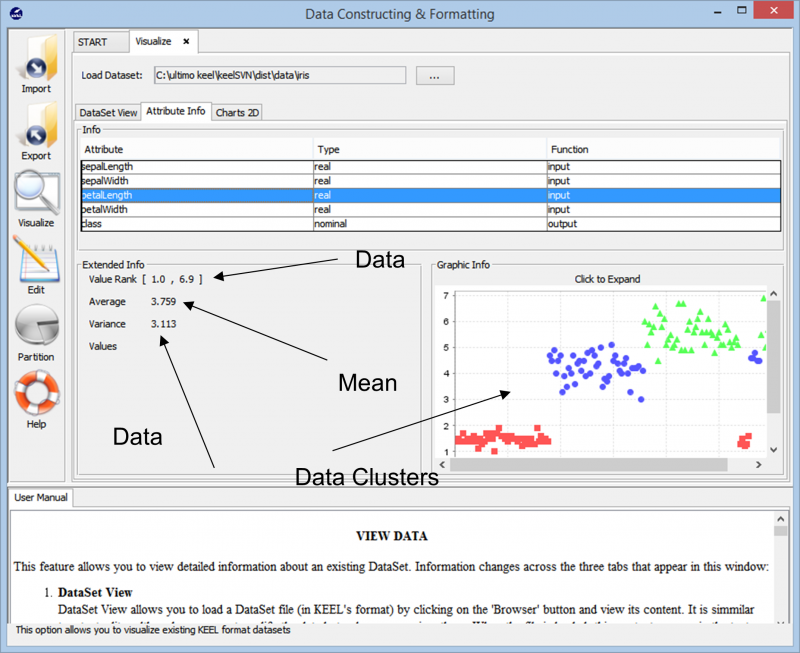
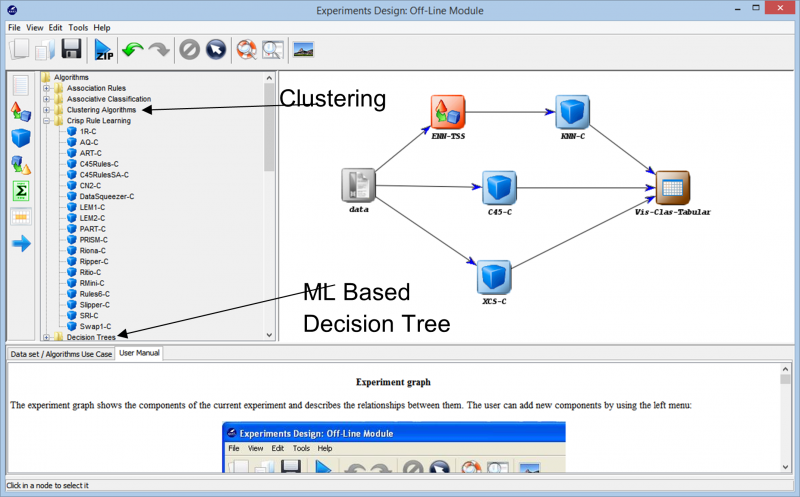
Når vi går videre i eksperimentet, støder vi på de forskellige teknikker, der kan bruges til at skabe vores eksperiment på ethvert datasæt. De forskellige læringsalgoritmer, der kan bruges på vores data, kan ses på følgende billede. Afhængigt af datasættets art og kravene til eksperimentet kan der eksperimenteres med forskellige algoritmer.
Hvis du for eksempel arbejder med umærkede data og skal finde ligheder mellem de forskellige datapunkter i dit datasæt, kan brug af en klyngealgoritme fra de forskellige tilgængelige muligheder hjælpe dig med bedre at forstå datapunkterne. Dette hjælper dig til sidst med at mærke og klassificere datapunkterne, så eksperimentet kan bygges på ved hjælp af mere omfattende overvågede læringsalgoritmer.
Konklusion
Det Køl platform for dataanalyse er en god ressource til både forsknings- og uddannelsesformål. Det er let at bruge grafisk brugergrænseflade hjælper brugerne til bedre at forstå kravene til dataene sammen med at give logiske referencer til nyttige teknikker og algoritmer, der yderligere hjælper brugerne i deres arbejdsgange. At have en bred vifte af forskellige algoritmer, der falder ind under de forskellige kategorier og algoritmiske teknikker, giver brugerne mulighed for at eksperimentere med adskillige logiske retninger og sammenligne disse resultater, så den mest optimale løsning på ethvert problem kan nås.
Keels kodefri træk og slip-tilgang til data mining hjælper selv begyndere med at arbejde ubesværet med omfattende beregningsmæssige intelligensmodeller. Dette giver indsigt i komplekse datasæt og udleder som resultat nyttige slutninger, der hjælper med at løse problemerne i den virkelige verden.