Nogle gange er det givne datasæt ikke i en enkelt CSV-fil. De er alle på forskellige Excel-ark. Du ved allerede, at det er at foretrække at udføre alle beregnings- eller forbehandlingsaktiviteter på et enkelt datasæt i stedet for flere datasæt. Det skærer ned eller sparer den tid, vi skal bruge på forbehandlingsopgaver. Som dataanalytiker eller dataforsker kan du også ofte opleve, at du bliver overbelastet af adskillige CSV-filer, der skal flettes, før du overhovedet starter din analyse eller undersøgelse af de tilgængelige data. På den anden side er det ikke altid muligt, at alle filerne er hentet fra den enkelte eller samme datakilde og har samme kolonne-/variablenavne og datastruktur. Dette indlæg vil lære dig at kombinere to eller flere CSV-filer med en lignende eller anden kolonnestruktur.
Hvorfor kombinere CSV-filer?
Et datasæt kan være en samling eller gruppe af værdier eller tal relateret til et specifikt emne. For eksempel er hver elevs testresultater i en bestemt klasse et eksempel på et datasæt. På grund af størrelsen af store datasæt gemmes de ofte i separate CSV-filer for forskellige kategorier. For eksempel, hvis vi er forpligtet til at undersøge en patient for en specifik sygdom, skal vi overveje hver komponent, herunder deres køn, journal, alder, sværhedsgrad af sygdommen osv. Derfor er det nødvendigt at kombinere CSV-data for at undersøge forskellige prædiktor-påvirkende faktorer. aspekter. Det er også bedre at arbejde og administrere et enkelt datasæt i stedet for flere datasæt, mens du udfører beregnings- eller forbehandlingsopgaverne. Det sparer hukommelse og andre beregningsressourcer
Sådan kombineres CSV-filer i Python?
Der er flere måder og metoder til at kombinere to eller flere CSV-filer i Python. I afsnittet nedenfor vil vi bruge funktionerne append(), concat() og merge() osv., til at kombinere CSV-filer til pandas-dataramme, hvorefter dataframes konverteres til en enkelt CSV-fil. Vi vil lære, hvordan man kombinerer flere CSV-filer med en lignende eller variabel kolonnestruktur.
Metode #1: Kombination af CSV'er med lignende strukturer eller kolonner
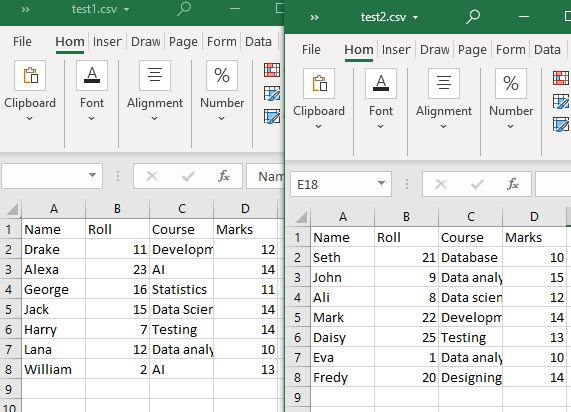
Vores nuværende arbejdsmappe har to CSV-filer, 'test1' og 'test2'.
Eksempel # 1: Brug af append() funktion
Begge CSV-filer har samme struktur. Glob()-funktionen vil blive brugt i denne metode til kun at vise CSV-filerne i arbejdsmappen. Så vil vi bruge 'pandas.DataFrame.append()' til at læse vores CSV-filer (med en fælles tabelstruktur).

Produktion:
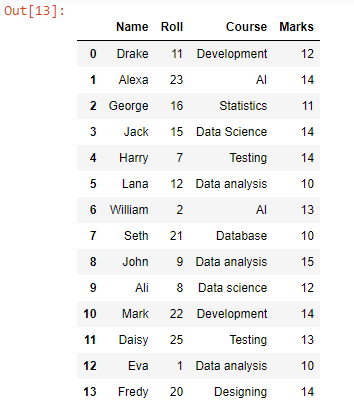
Ved hjælp af append-funktionen har vi tilføjet eller tilføjet hver datarække fra test2.csv under datarækkerne i test1.csv, da det kan ses, at alle filens datarækker er blevet kombineret. For at konvertere denne dataramme til CSV kan vi bruge to_csv()-funktionen.

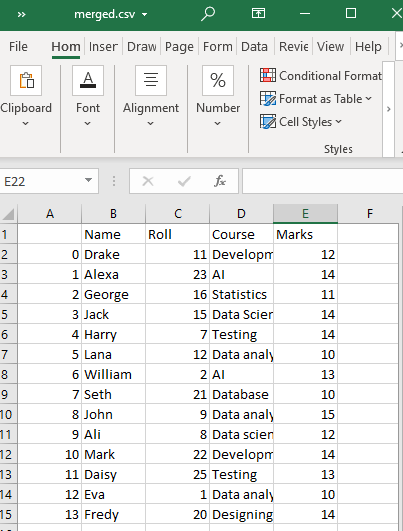
Dette vil oprette en kombineret CSV-fil af CSV-filer af 'test1' og 'test2' i vores arbejdsmappe med det angivne navn, dvs. merged.csv.
Eksempel # 2: Brug af concat() funktion
Vi importerer pandamodulet først. Kortmetoden læser hver CSV-fil, vi har sendt ved hjælp af pd.read_csv(). Disse tilknyttede filer (CSV-filer) vil derefter blive kombineret langs rækkeaksen som standard ved hjælp af funktionen pd.concat(). Hvis vi vil kombinere CSV-filer vandret, kan vi sende axis=1. Angivelse af ignoreringsindekset = True opretter også kontinuerlige indeksværdier for den kombinerede dataramme.

pd.read_csv() sendes inde i concat()-funktionen for at læse CSV-filerne ind i pandas-datarammen efter sammenkædning.
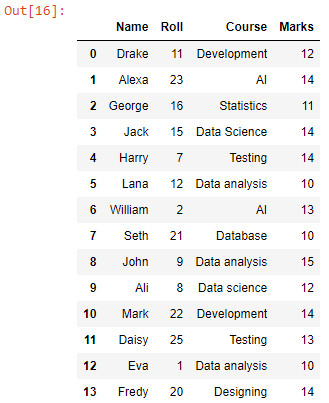
Vi har fået en dataramme med kombinerede data for alle CSV-filer i arbejdsmappen. Lad os nu konvertere den til en CSV-fil.
Vores kombinerede CSV oprettes i den aktuelle mappe.
Metode #2: Kombination af CSV'er med forskellige strukturer eller kolonner
Vi diskuterede at kombinere CSV-filer med de samme kolonner og struktur i den første metode. I denne metode vil vi kombinere CSV-filer med forskellige kolonner og strukturer.
Eksempel # 1: Brug af merge() funktion
Funktionen 'pandas.merge()' i pandas-modulet kan kombinere to CSV-filer. Sammenfletning refererer blot til at kombinere to datasæt til et enkelt datasæt baseret på delte kolonner eller attributter.
Vi kan flette datarammer på fire forskellige måder at forbinde på:
- Indre
- Ret
- Venstre
- Ydre
For at udføre disse typer fletninger bruger vi to CSV-filer.
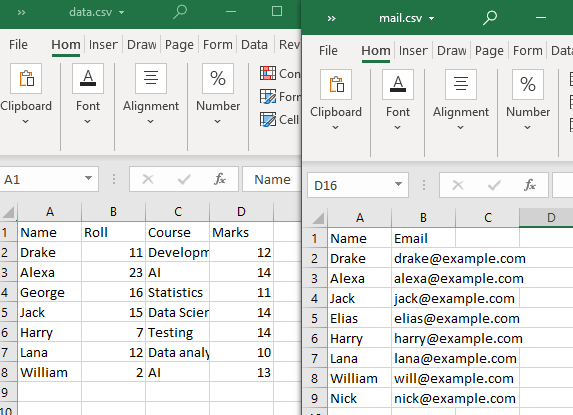
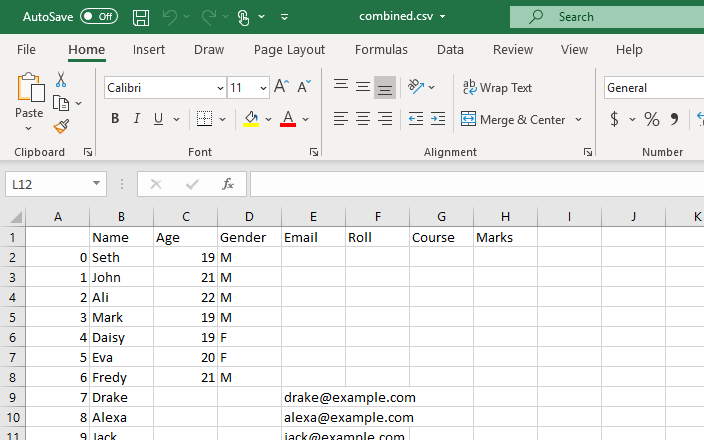
Bemærk, at mindst én attribut eller kolonne skal deles af begge CSV-filer. Som observeret er kolonnen 'Navn' og nogle af dens attributter delt af begge CSV-filer.
Flet ved hjælp af indre sammenføjning
Angivelse af parameter how=’inner’ i merge()-funktionen kombinerer de to datarammer i henhold til den angivne kolonne og giver derefter en ny dataramme, der kun indeholder rækkerne med identiske/samme værdier i begge originale dataframes.
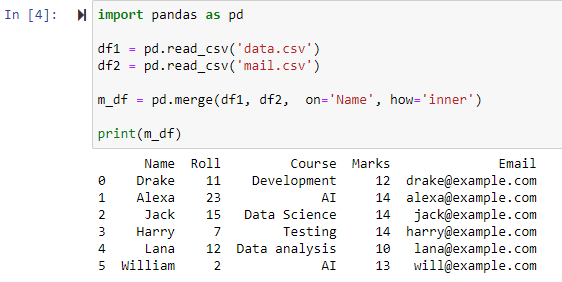
Som det kan ses, har funktionen slået begge CSV-filer sammen og returneret rækkerne baseret på fælles attributter for kolonnen 'Navn'.
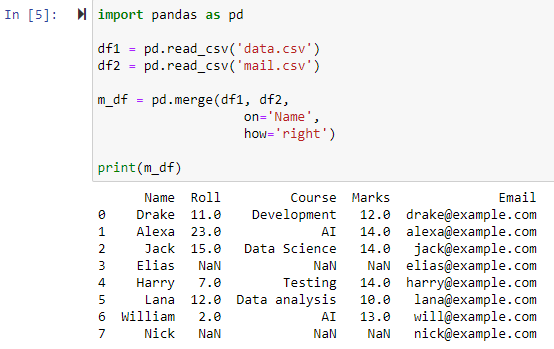
Flet ved hjælp af højre ydre sammenføjning
Når parameteren how='right' er angivet, kombineres begge datarammer baseret på den kolonne, vi har angivet for parameteren 'on'. Og en ny dataramme, der indeholder alle rækkerne fra den højre dataramme, inklusive alle rækker, for hvilke den venstre dataramme ikke indeholder værdier, vil blive returneret, med den venstre datarammes kolonneværdi sat til NAN.
Flet ved hjælp af venstre ydre sammenføjning
Når parameteren er angivet som 'venstre', kombineres de to datarammer baseret på den angivne kolonne ved hjælp af parameteren 'on', hvilket returnerer en ny dataramme, der har alle rækkerne fra den venstre dataramme såvel som alle rækker, der har NAN eller null-værdier i den højre dataramme og indstiller den højre datarammekolonneværdi til NAN.
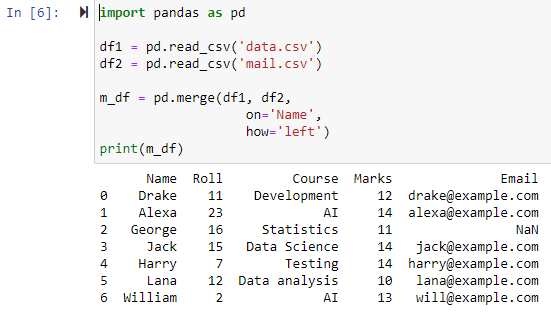
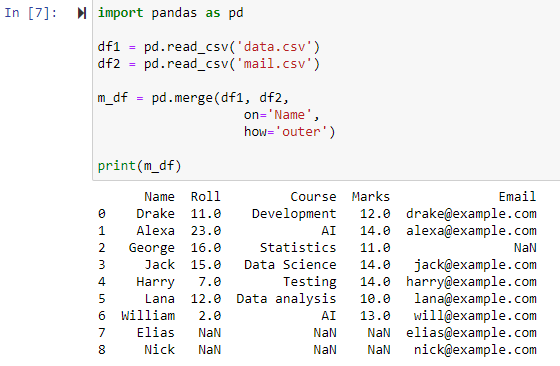
Flet ved hjælp af fuld ydre sammenføjning
Når how='ydre' er angivet, kombineres de to datarammer afhængigt af kolonnen angivet for parameteren 'on', hvilket returnerer en ny dataramme, der indeholder rækkerne fra både df1- og df2-datarammer og indstiller NAN som værdien for alle rækker for hvilke data mangler i en af datarammerne.
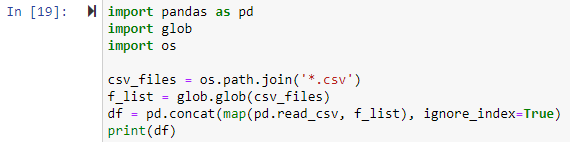
Eksempel # 2: Kombination af alle CSV-filer i arbejdsbiblioteket
I denne metode bruger vi glob-modulet til at kombinere alle .csv-filer til en pandas DataFrame. Alle biblioteker skulle importeres først. Dernæst vil vi angive en sti for hver CSV-fil, vi ønsker at kombinere. Filstien er det første argument for os.path.join()-funktionen i eksemplet nedenfor, og det andet argument er enten stikomponenterne eller .csv-filer, der skal sammenføjes. Her finder udtrykket '*.csv' og returnerer hver fil i den arbejdsmappe, der slutter med .csv-filudvidelsen. Glob.glob(files joined)-funktionen accepterer en liste over navnene på de flettede filer som input og udsender en liste over alle flettede/kombinerede filer.
Dette script returnerer en dataramme med kombinerede data for alle CSV-filerne i vores arbejdsmappe.
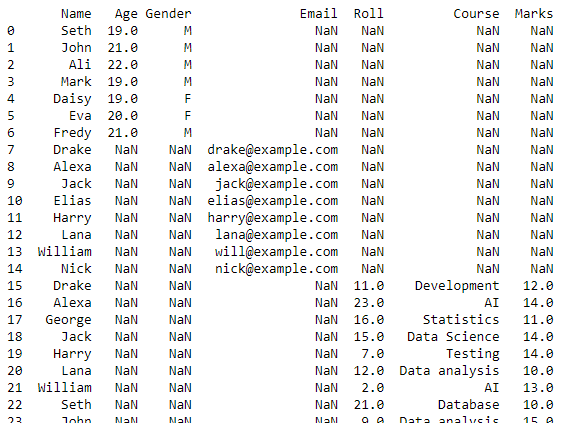
Denne dataramme vil blive transformeret til en CSV-fil, og to_csv()-funktionen vil blive brugt til denne konvertering. Denne nye CSV-fil vil være de kombinerede CSV-filer, der er oprettet fra alle de CSV-filer, der er gemt i den aktuelle arbejdsmappe.
Konklusion
I dette indlæg diskuterede vi, hvorfor vi skal kombinere CSV-filer. Vi diskuterede, hvordan to eller flere CSV-filer kan kombineres i Python. Vi opdelte denne tutorial i to sektioner. I det første afsnit forklarede vi, hvordan man bruger funktionerne append() og concat() til at kombinere CSV-filer med samme struktur eller kolonnenavne. I den anden sektion brugte vi merge()-metoden, os.path.join() og glob-metoden til at kombinere CSV-filer med forskellige kolonner og strukturer.