Optimering af Python-koden med profileringsværktøjer
Ved at konfigurere Google Colab til at arbejde for at optimere Python-koden med profileringsværktøjer begynder vi med at konfigurere et Google Colab-miljø. Hvis vi er nye til Colab, er det en vigtig, kraftfuld cloud-baseret platform, der giver adgang til Jupyter-notebooks og en række Python-biblioteker. Vi får adgang til Colab ved at besøge (https://colab.research.google.com/) og oprette en ny Python-notesbog.
Importer profilbibliotekerne
Vores optimering er afhængig af den dygtige brug af profileringsbiblioteker. To vigtige biblioteker i denne sammenhæng er cProfile og line_profiler.
importere cProfil
importere line_profiler
'cProfile'-biblioteket er et indbygget Python-værktøj til profilering af kode, mens 'line_profiler' er en ekstern pakke, der giver os mulighed for at gå endnu dybere, og analysere koden linje for linje.
I dette trin opretter vi et eksempel på et Python-script til at beregne Fibonacci-sekvensen ved hjælp af en rekursiv funktion. Lad os analysere denne proces i større dybde. Fibonacci-sekvensen er et sæt tal, hvor hvert efterfølgende tal er summen af de to før det. Det starter normalt med 0 og 1, så rækkefølgen ser ud som 0, 1, 1, 2, 3, 5, 8, 13, 21 og så videre. Det er en matematisk sekvens, der almindeligvis bruges som eksempel i programmering på grund af dens rekursive natur.
Vi definerer en Python-funktion kaldet 'Fibonacci' i den rekursive Fibonacci-funktion. Denne funktion tager et 'n' heltal som sit argument, der repræsenterer positionen i Fibonacci-sekvensen, som vi ønsker at beregne. Vi ønsker at finde det femte tal i Fibonacci-sekvensen, for eksempel, hvis 'n' er lig med 5.
def fibonacci ( n ) :
Dernæst etablerer vi en base case. Et basistilfælde i rekursion er et scenarie, der afslutter opkaldene og returnerer en forudbestemt værdi. I Fibonacci-sekvensen, når 'n' er 0 eller 1, kender vi allerede resultatet. 0. og 1. Fibonacci-tal er henholdsvis 0 og 1.
hvis n <= 1 :Vend tilbage n
Denne 'hvis'-sætning bestemmer, om 'n' er mindre end eller lig med 1. Hvis den er, returnerer vi selv 'n', da der ikke er behov for yderligere rekursion.
Rekursiv beregning
Hvis 'n' overstiger 1, fortsætter vi med den rekursive beregning. I dette tilfælde skal vi finde det 'n'-te Fibonacci-tal ved at summere det '(n-1)' og '(n-2)'-te Fibonacci-tal. Det opnår vi ved at foretage to rekursive opkald i funktionen.
andet :Vend tilbage fibonacci ( n - 1 ) + fibonacci ( n - 2 )
Her beregner 'fibonacci(n - 1)' det '(n-1)'th Fibonacci-tal, og 'fibonacci(n - 2)' beregner det '(n-2)'th Fibonacci-tal. Vi tilføjer disse to værdier for at få det ønskede Fibonacci-tal ved 'n'-position.
Sammenfattende beregner denne 'fibonacci'-funktion rekursivt Fibonacci-tallene ved at opdele problemet i mindre underopgaver. Den foretager rekursive opkald, indtil den når basistilfældene (0 eller 1), og returnerer kendte værdier. For ethvert andet 'n' beregner den Fibonacci-tallet ved at summere resultaterne af to rekursive kald for '(n-1)' og '(n-2)'.
Selvom denne implementering er ligetil at beregne Fibonacci-tallene, er den ikke den mest effektive. I de senere trin vil vi bruge profileringsværktøjerne til at identificere og optimere dets ydeevnebegrænsninger for bedre eksekveringstider.
Profilering af koden med CProfile
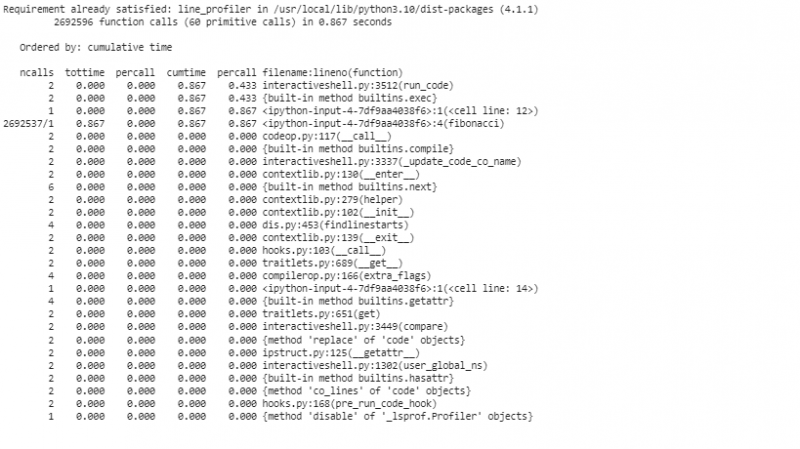
Nu profilerer vi vores 'fibonacci'-funktion ved at bruge 'cProfile'. Denne profileringsøvelse giver indsigt i den tid, der forbruges af hvert funktionskald.
cprofiler = cProfil. Profil ( )cprofiler. aktivere ( )
resultat = fibonacci ( 30 )
cprofiler. deaktivere ( )
cprofiler. print_stats ( sortere = 'akkumulerede' )
I dette segment initialiserer vi et 'cProfile'-objekt, aktiverer profileringen, anmoder om 'fibonacci'-funktionen med 'n=30', deaktiverer profileringen og viser statistikken, der er sorteret efter kumulativ tid. Denne indledende profilering giver os et overblik på højt niveau over, hvilke funktioner der bruger mest tid.
! pip installer line_profilerimportere cProfil
importere line_profiler
def fibonacci ( n ) :
hvis n <= 1 :
Vend tilbage n
andet :
Vend tilbage fibonacci ( n - 1 ) + fibonacci ( n - 2 )
cprofiler = cProfil. Profil ( )
cprofiler. aktivere ( )
resultat = fibonacci ( 30 )
cprofiler. deaktivere ( )
cprofiler. print_stats ( sortere = 'akkumulerede' )
For at profilere koden linje for linje med line_profiler for en mere detaljeret analyse, bruger vi 'line_profiler' til at segmentere vores kode linje for linje. Før vi bruger 'line_profiler', skal vi installere pakken i Colab-lageret.
! pip installer line_profilerNu hvor vi har 'line_profiler' klar, kan vi anvende den på vores 'fibonacci' funktion:
%load_ext line_profilerdef fibonacci ( n ) :
hvis n <= 1 :
Vend tilbage n
andet :
Vend tilbage fibonacci ( n - 1 ) + fibonacci ( n - 2 )
%lprun -f fibonacci fibonacci ( 30 )
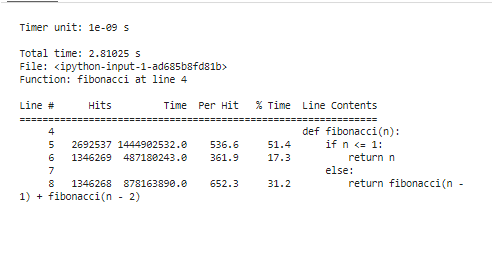
Dette uddrag begynder med at indlæse 'line_profiler'-udvidelsen, definerer vores 'fibonacci'-funktion og til sidst bruger '%lprun' til at profilere 'fibonacci'-funktionen med 'n=30'. Det tilbyder en linje-for-linje segmentering af eksekveringstider, præcist at rydde, hvor vores kode bruger sine ressourcer.
Efter at have kørt profileringsværktøjerne for at analysere resultaterne, vil det blive præsenteret med en række statistikker, der viser vores kodes præstationskarakteristika. Disse statistikker involverer den samlede tid brugt inden for hver funktion og varigheden af hver linje kode. For eksempel kan vi skelne, at Fibonacci-funktionen investerer lidt mere tid i at genberegne de identiske værdier flere gange. Dette er den redundante beregning, og det er et klart område, hvor optimering kan anvendes, enten gennem memoisering eller ved at anvende de iterative algoritmer.
Nu laver vi optimeringer, hvor vi identificerede en potentiel optimering i vores Fibonacci-funktion. Vi har bemærket, at funktionen genberegner de samme Fibonacci-tal flere gange, hvilket resulterer i unødvendig redundans og langsommere eksekveringstid.
For at optimere dette implementerer vi memoiseringen. Memoisering er en optimeringsteknik, der involverer lagring af de tidligere beregnede resultater (i dette tilfælde Fibonacci-tal) og genbrug af dem, når det er nødvendigt i stedet for at genberegne dem. Dette reducerer de redundante beregninger og forbedrer ydeevnen, især for rekursive funktioner som Fibonacci-sekvensen.
For at implementere memoiseringen i vores Fibonacci-funktion skriver vi følgende kode:
# Ordbog til at gemme beregnede Fibonacci-talfib_cache = { }
def fibonacci ( n ) :
hvis n <= 1 :
Vend tilbage n
# Tjek, om resultatet allerede er cachelagret
hvis n i fib_cache:
Vend tilbage fib_cache [ n ]
andet :
# Beregn og cache resultatet
fib_cache [ n ] = fibonacci ( n - 1 ) + fibonacci ( n - 2 )
Vend tilbage fib_cache [ n ] ,
I denne modificerede version af 'fibonacci'-funktionen introducerer vi en 'fib_cache'-ordbog til at gemme de tidligere beregnede Fibonacci-tal. Før vi beregner et Fibonacci-tal, tjekker vi, om det allerede er i cachen. Hvis det er, returnerer vi det cachelagrede resultat. I alle andre tilfælde beregner vi det, opbevarer det i cachen og returnerer det derefter.
Gentagelse af profilering og optimering
Efter implementering af optimeringen (memoisering i vores tilfælde), er det afgørende at gentage profileringsprocessen for at kende virkningen af vores ændringer og sikre, at vi forbedrede kodens ydeevne.
Profilering efter optimering
Vi kan bruge de samme profileringsværktøjer, 'cProfile' og 'line_profiler', til at profilere den optimerede Fibonacci-funktion. Ved at sammenligne de nye profileringsresultater med de tidligere, kan vi måle effektiviteten af vores optimering.
Sådan kan vi profilere den optimerede 'fibonacci'-funktion ved hjælp af 'cProfile':
cprofiler = cProfil. Profil ( )cprofiler. aktivere ( )
resultat = fibonacci ( 30 )
cprofiler. deaktivere ( )
cprofiler. print_stats ( sortere = 'akkumulerede' )
Ved at bruge 'line_profiler' profilerer vi den linje for linje:
%lprun -f fibonacci fibonacci ( 30 )Kode:
# Ordbog til at gemme beregnede Fibonacci-talfib_cache = { }
def fibonacci ( n ) :
hvis n <= 1 :
Vend tilbage n
# Tjek, om resultatet allerede er cachelagret
hvis n i fib_cache:
Vend tilbage fib_cache [ n ]
andet :
# Beregn og cache resultatet
fib_cache [ n ] = fibonacci ( n - 1 ) + fibonacci ( n - 2 )
Vend tilbage fib_cache [ n ]
cprofiler = cProfil. Profil ( )
cprofiler. aktivere ( )
resultat = fibonacci ( 30 )
cprofiler. deaktivere ( )
cprofiler. print_stats ( sortere = 'akkumulerede' )
%lprun -f fibonacci fibonacci ( 30 )
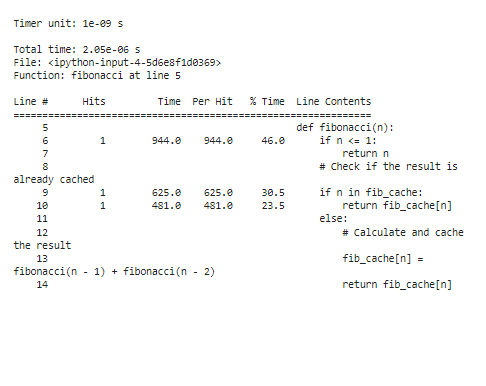
For at analysere profileringsresultaterne efter optimering vil der være væsentligt reducerede eksekveringstider, især for store 'n' værdier. På grund af memoization observerer vi, at funktionen nu bruger langt mindre tid på at genberegne Fibonacci-tallene.
Disse trin er vigtige i optimeringsprocessen. Optimering involverer at foretage informerede ændringer i vores kode baseret på de observationer, der opnås ved profilering, mens gentagen profilering sikrer, at vores optimeringer giver de forventede præstationsforbedringer. Ved iterativ profilering, optimering og validering kan vi finjustere vores Python-kode for at levere en bedre ydeevne og forbedre brugeroplevelsen af vores applikationer.
Konklusion
I denne artikel diskuterede vi eksemplet, hvor vi optimerede Python-koden ved hjælp af profileringsværktøjer i Google Colab-miljøet. Vi initialiserede eksemplet med opsætningen, importerede de væsentlige profileringsbiblioteker, skrev eksempelkoderne, profilerede det ved hjælp af både 'cProfile' og 'line_profiler', beregnede resultaterne, anvendte optimeringerne og forfinede kodens ydeevne iterativt.