Denne artikel fokuserer på filterudtryk. Derfor vil vi definere filterudtrykkene, forklare hvorfor og hvornår de er anvendelige og give en trin-for-trin guide til, hvordan du bruger dem gennem relevante eksempler.
Hvad er filterudtryk?
Filterudtryk er en populær teknik til at filtrere dataene i DynamoDB under forespørgsel og scanning. I DynamoDB er korrekt datamodellering og organisation afhængig af filtrering. Mens de fleste applikationer altid har tonsvis af gemte data, kan du hurtigt få brug for en genstand fra det store rod.
Din evne til at hente de korrekte data, når du har brug for det, afhænger af din databases filtreringsmuligheder, og det er her, filterudtrykkene hjælper. De angiver resultaterne i forespørgselselementet, som du ønsker skal returneres til dig, da de kasserer resten af elementerne.
Du kan anvende filterudtrykkene på filtrene på serversiden på elementattributter, efter at en forespørgselshandling er afsluttet, men før serveren bringer resultaterne af dit forespørgselskald tilbage. Dette indebærer, at din forespørgsel stadig bruger den samme mængde læsekapacitet, uanset om du bruger et filterudtryk.
Desuden, ligesom almindelige forespørgselsoperationer, sker din 1 MB datagrænse for forespørgselsoperationer før evalueringen af din filterudtryksoperation. Du kan bruge denne handling til at reducere nyttelasten, søge efter specifikke elementer og forbedre enkelheden og læsbarheden under applikationsudvikling.
Filterudtrykssyntaks og eksempler
Navnlig bruger både filterudtryk og nøgleudtryk den samme syntaks. Desuden kan filterudtryk og betingelsesudtryk også bruge de samme funktioner, komparatorer og logiske operatorer.
De andre operatorer, der filtrerer udtrykkene kan bruge, inkluderer også CONTAINS operatoren, OR operatoren, not-equals () operatoren, IN operatoren, BETWEEN operatoren, BEGINS_WITH operatoren, SIZE operatoren og EXISTS operatoren.
Eksempel 1: Forespørgsel ved hjælp af AWS CLI og DynamoDB Primære nøgler
Dette eksempel forespørger i musiktabellen for en bestemt genre (partitionsnøgle) og en specifik kunstner (sorteringsnøgle). Værktøjet bringer kun et resultat tilbage for de elementer, der matcher den bestemte partitionsnøgle og sorteringsnøgle for sangene med flest visninger.
Du kan angive antallet af visninger (#v) i kommandoen. For eksempel mærker vi vores minimumsgrænse til 1.000 visninger for at antyde, at kun resultaterne for sange med over 1.000 visninger kommer tilbage.
$ aws dynamodb forespørgsel \--tabelnavn Musik \
--nøgle-betingelse-udtryk 'Genre = :fn og kunstner = :sub' \
--filter-udtryk '#v >= :tal(1000)' \
--udtryk-attribut-navne '{'#v': 'Visninger'}' \
--udtryk-attribut-værdier fil: // værdier.json
Eksempel 2: Brug af AWS CLI med betingelsesudtryk
Vi kan omstrukturere den samme forespørgsel som i det foregående eksempel, men nu med betingelsesnøgler ved siden af vores filtre. Den inkluderer ikke sorteringsnøglen. I stedet henter den alle rekorderne for den angivne kunstner med mere end 1.000 visninger. Det kan også rekonstrueres til at give ordrer over et givet nummer for et bestemt brugernavn (customer_id).
$ aws dynamodb forespørgsel \--tabelnavn Musik \
--nøgle-betingelse-udtryk 'Brugernavn = :brugernavn' \
--filter-udtryk 'Beløb > :beløb' \
--udtryk-attribut-værdier '{
':brugernavn': { 'S': 'kunstner' },
':amount': { 'N': '1000' }
}' \
$LOCAL
Et eksempel på resultatet ser således ud:
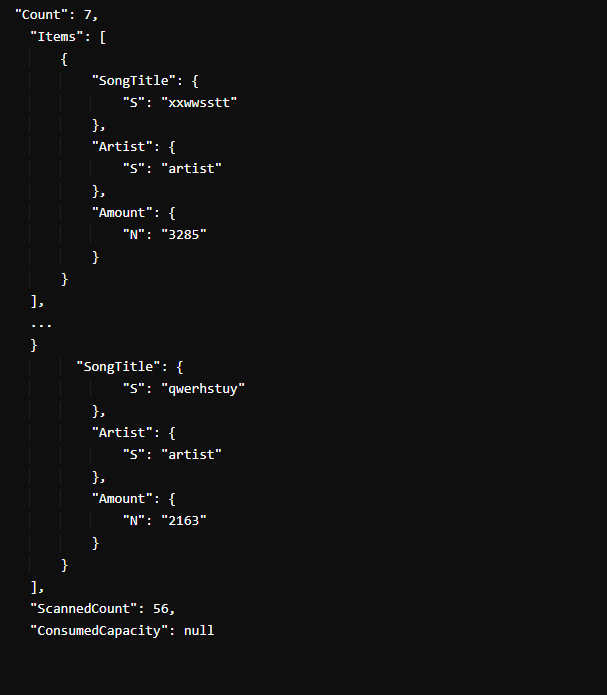
Den givne illustration viser, at ud af de 56 sangtitler for samme kunstner er det kun syv sange, der har mere end 1.000 visninger. Vi har dog for kortheds skyld afkortet tallet og inkluderet kun det første og det sidste resultat i listen.
Eksempel 3: Brug af filterudtryk med No-Equal ()-operatoren
I det følgende Java-værktøj ønsker vi at forespørge i vores tabel (Movie Collection) for alle film, der ikke svarer til 'Movie X'. Sørg for, at du bruger et filterudtryk med en attribut (#name) ved siden af en udtryksattributværdi (:name) som illustreret i følgende:
const AWS = kræve ( 'aws-sdk' ) ;AWS.config.update ( { område: 'eu-west-1' } ) ;
const dynamodb = ny AWS.DynamoDB.DocumentClient ( ) ;
var params = {
Tabelnavn: 'filmsamling' ,
KeyConditionExpression: '#PK = :PK' ,
FilterExpression: '#navn :navn' , ( filter udtryk )
ExpressionAttributeNames: { '#PK' : 'PK' , '#navn' : 'navn' } , ( betingelse udtryk )
ExpressionAttributeValues: {
':PK' : 'OgejhHrdRS453HGD4Ht44' ,
':navn' : 'Film X'
}
} ;
dynamodb.query ( parametre, fungere ( fejl, data ) {
hvis ( fejl ) console.log ( fejl ) ;
andet console.log ( data ) ;
} ) ;
Eksempel 4: Brug af filterudtryk med scanningsoperatøren
Mens den forrige kommando bruger <> til kun at hente de elementer, der ikke er lig med filmnavnet kaldet Movie X, skal du sørge for at bruge nøglebetingelsesudtrykkene her sammen med filterudtrykket. Dette skyldes, at det er umuligt at filtrere dataene i Query-operatoren uden at bruge et nøglebetingelsesudtryk.
var params = {Tabelnavn: 'filmsamling' ,
FilterExpression: 'PK = :PK og #navn :navn' ,
ExpressionAttributeNames: { '#navn' : 'navn' } ,
ExpressionAttributeValues: {
':PK' : 'OgejhHrdRS453HGD4Ht44' ,
':navn' : 'Film X'
}
} ;
dynamodb.scan ( parametre, fungere ( fejl, data ) {
hvis ( fejl ) console.log ( fejl ) ;
andet console.log ( data ) ;
} ) ;
Konklusion
Det er slutningen på vores DynamoDB-tutorial om filterudtryk. Du kan bruge filterudtrykkene til at hente et sæt foretrukne data, filtrere de hentede data efter en scanning eller forespørgsel eller returnere et sæt data til en klient. Selvom det er anvendeligt med en række værktøjer, er der tilfælde, hvor brug af filterudtrykkene ikke er levedygtige. For eksempel kan du kun bruge dem, hvis du har en ordentlig datamodel, når du bruger en primær nøgle, og når du udtrækker store dele af data.