Data indsamles i enorme antal dagligt, og håndtering af big data er det vigtigste anvendelsestilfælde for Elasticsearch-motoren. Dataene gemmes i analysedatabasen i realtid, og brugeren har lov til at udtrække data for at finde nyttig viden fra dem ved hjælp af forespørgsler. Brugeren kan anvende forespørgsler for at finde data fra flere indekser og vise dem i en enkelt bøtte fra relationsdatabasen.
Denne vejledning vil forklare Elasticsearch-aggregationerne med eksempler, der bruger forskellige aggregeringer.
Hvad er Elasticsearch Aggregation?
I Elasticsearch er aggregering processen med at kombinere eller gruppere felterne for at udtrække information fra relationsdatabasen. Aggregeringen i Elasticsearch kan betragtes som GRUPPE EFTER KLAUSUL eller SAMLET() funktion i SQL-sproget.
Hvordan bruger man Elasticsearch Aggregation?
For at bruge aggregeringen i Elasticsearch skal brugeren have en grundlæggende forståelse af deres database. Lad os undersøge syntaksen og dens praktiske implementering:
Syntaks
For at finde data fra databasen, syntaksen for aggregeringen i Elasticsearch-maskinen som nedenfor:
'aggs' : {'navn_på_aggregation' : {
'type_of_aggregation' : {
'Mark' : 'dokument_feltnavn'
}
Ovenstående uddrag:
-
- Den bruger ' aggs ” nøgleord, der forklarer brugen af aggregering i forespørgslen.
- Det navn_på_sammenlægning indstilles af brugeren i henhold til de nødvendige oplysninger.
- Herefter er type_of_aggregation bruges til at få data.
- Den sidste linje bruger Mark nøgleord som efterfølges af navnet på attributten fra dokumentet.
Eksempel 1: Aggregation i Kibana-prøvedata
Dette afsnit forklarer aggregeringen ved hjælp af et eksempel ved hjælp af eksempeldata fra Kibana ved først at oprette forbindelse til dem. Derefter skal du blot gå ind i ' Udviklerværktøjer ” ved at søge på det fra søgefeltet og klikke på det:
Hent data fra eksempeldata
Du skal blot bruge følgende kommando til at hente dataene fra ' kibana_sample_data_logs ” indeks på Dev Tools-konsollen:
FÅ / kibana_sample_data_logs / _Søg
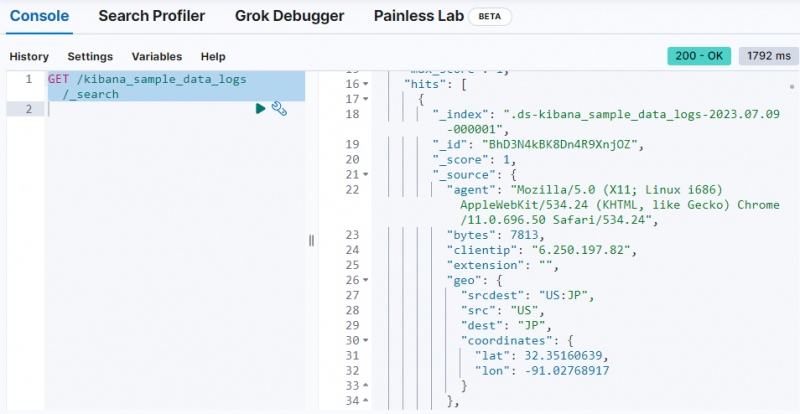
Outputtet viser, at data er blevet hentet fra ' kibana_sample_data_logs ” indeks.
Følgende kode bruger en FÅ anmodning på ' kibana_sample_data_log ' for at søge fra den ved hjælp af værdi_antal-sammenlægningen på ' klientip ' Mark:
FÅ / kibana_sample_data_logs / _Søg{ 'størrelse' : 0 ,
'aggs' : {
'ip_count' : {
'værdi_antal' : {
'Mark' : 'kundetip'
}
}
}
}
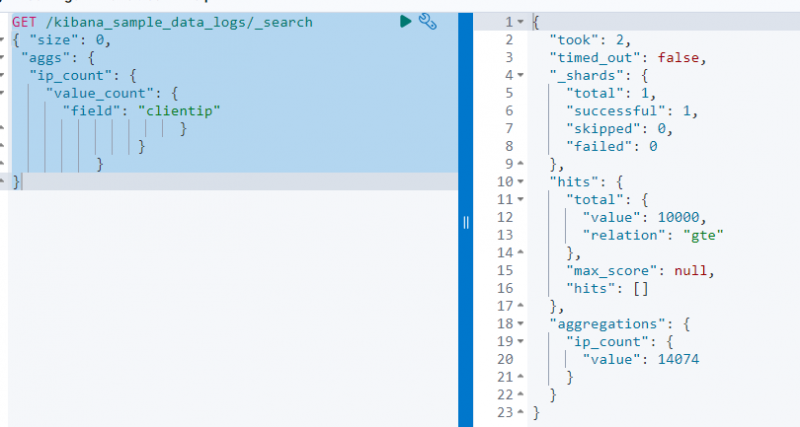
Ovenstående skærmbillede viser aggregeringen på klientip felt med værdien 14074 .
Vigtige sammenlægninger
Nogle af de vigtige sammenlægninger, der bliver brugt til at finde data effektivt fra databasen, er nævnt nedenfor:
De følgende eksempler forklarer de ovennævnte sammenlægninger ved hjælp af FÅ anmodning fra ' kibana_sample_data_ecommerce ' indeks:
Kardinalitet Aggregation
Følgende kode bruger ' kardinalitet ' sammenlægning på ' sku ” felt fra e-handelsdataene. Kørsel af denne kode får du enkeltværdiaggregering for at få de unikke SKU'er fra Elasticsearch-databasen:
FÅ / kibana_sample_data_ecommerce / _Søg{
'størrelse' : 0 ,
'aggs' : {
'unique_skus' : {
'kardinalitet' : {
'Mark' : 'sku'
}
}
}
}
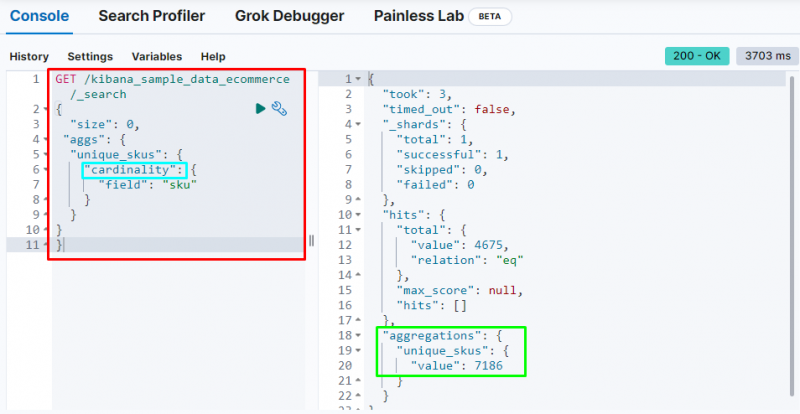
Den viser kardinalitet aggregering at finde 7186 værdier fra indekset.
Statistik Aggregation
En anden vigtig sammenlægning er ' statistik ' aggregering, som bruges til at få ' tælle ', ' min ', ' max ', ' gns ', og ' sum ' statistik fra ' total_mængde ' Mark:
FÅ / kibana_sample_data_ecommerce / _Søg{
'størrelse' : 0 ,
'aggs' : {
'mængde_statistik' : {
'statistik' : {
'Mark' : 'total_quantity'
}
}
}
}
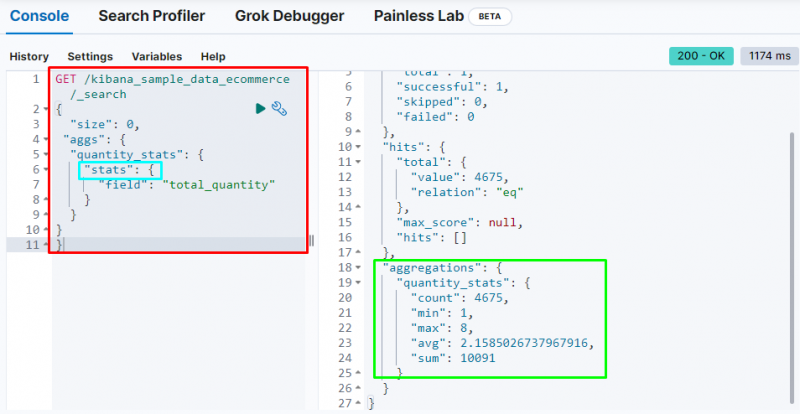
Ovenstående skærmbillede viser statistikken i outputtet fra ' total_mængde ' Mark.
Filtersammenlægning
Filteraggregering bruges til at bortfiltrere data baseret på et udtryk eller en sætning fra databasen, da følgende kode indeholder det:
FÅ / kibana_sample_data_ecommerce / _Søg{ 'størrelse' : 0 ,
'aggs' : {
'filter_aggregation' : {
'filter' : {
'semester' : {
'bruger' : 'eddie' } } ,
'aggs' : {
'pris_gennemsnit' : {
'gennemsnit' : {
'Mark' : 'produkter.pris' } }
} } } }
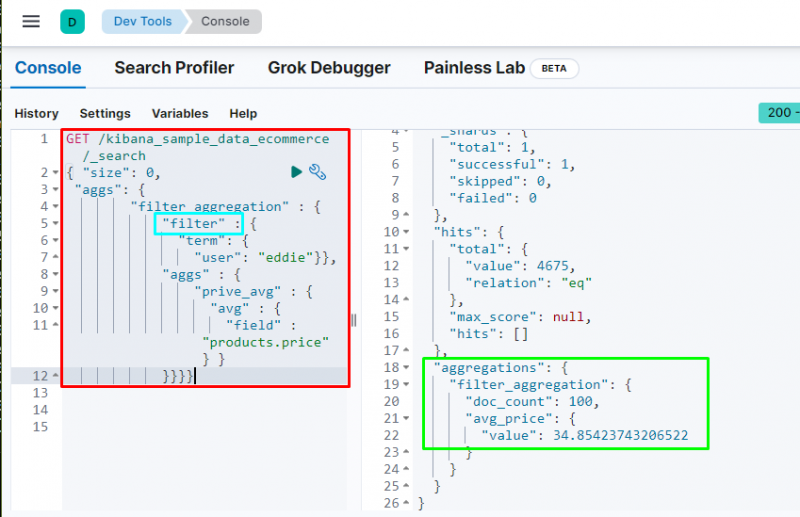
Udførelse af kode vil filtrere dataene baseret på ' eddie ” bruger og viser gennemsnitsprisen på de købte varer. Ovenstående skærmbillede viser, at bruger har fundet 100 gange fra data og værdi af gns _ pris sammenlægning.
Term Aggregation
Udtrykket aggregering opretter en bucket og gemmer data fra feltet i bucket og følgende kode bruger ' bruger ' felt for at gemme sine data i bøtten:
FÅ / kibana_sample_data_ecommerce / _Søg{
'størrelse' : 0 ,
'aggs' : {
'Term_Aggregation' : {
'betingelser' : {
'Mark' : 'bruger'
}
}
}
}
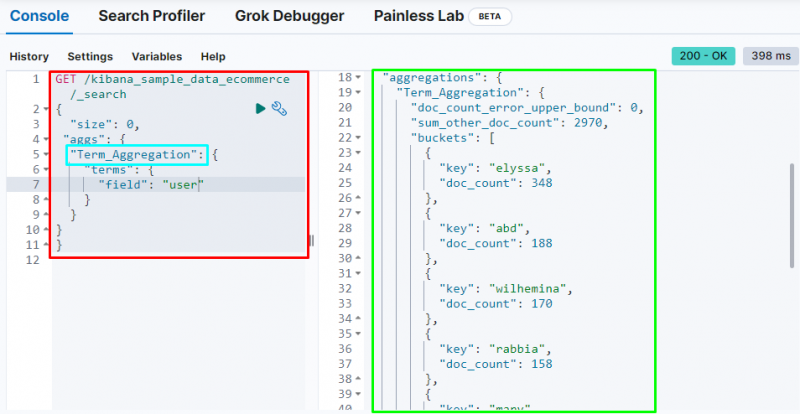
Følgende skærmbillede viser, at termen aggregering har skabt buckets for hver bruger og deres dokumentantal.
Det handler om Elasticsearch-aggregering og forskellige vigtige aggregering.
Konklusion
I Elasticsearch bruges aggregeringen til at hente data fra de aggregerede dokumenter, og disse dokumenter udtrækkes fra et specifikt felt. Der er nogle vigtige sammenlægninger, der bliver brugt til at få brugbar indsigt fra indekserne er forklaret. Denne vejledning har forklaret Elasticsearch-aggregation og demonstreret processen med at bruge Elasticsearch-aggregation.