Skalerbarhed
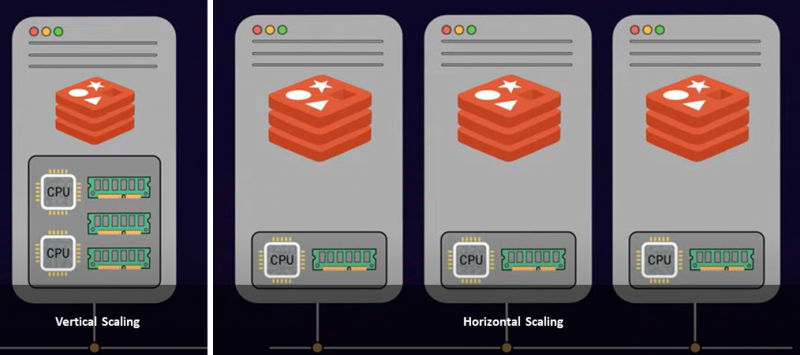
Der er to almindelige tilgange til at skalere en server: lodret skalering og horisontal skalering. Vertikal skalering eller opskalering er, hvor du tilføjer mere strøm og ressourcer til din server, såsom flere CPU'er, hukommelse og lager, hvilket er dyrt. På den anden side tilføjer horisontal skalering flere noder til din eksisterende ressourcepulje. Dette kaldes udskalering. Så baseret på dine begrænsninger og krav er det op til dig at have en enkelt større serverinstans eller implementere flere servernoder.
Antag, at du har 100 GB RAM og skal have 200 GB data. I dette tilfælde har du to valg:
- Opskaler ved at tilføje mere RAM til systemet
- Skaler ud ved at tilføje endnu en serverforekomst med 100 GB RAM
Hvis du har nået den maksimale RAM-grænse inden for din infrastruktur, så er udskalering den ideelle tilgang. Derudover vil udskalering øge databasens gennemløb med en enorm margin.
Redis Sharding
Det er en kendt sag, at Redis opererer på en enkelt tråd. Så Redis er ikke i stand til at bruge flere kerner af din servers CPU til at behandle kommandoer. Derfor giver tilføjelse af flere CPU-kerner dig ikke meget gennemløb eller ydeevne med Redis. Det er ikke tilfældet med at dele dine data mellem flere serverforekomster. Tilføjelse af flere servere og fordeling af datasættet blandt disse muliggør behandling af klientanmodninger parallelt, hvilket øger gennemløbet. Derudover kan den samlede ydeevne stige tæt på lineært.
Denne tilgang til at opdele eller distribuere data mellem flere servere med skalering i tankerne kaldes skæring . Alle de servere, der gemmer dele af data, kaldes skår .
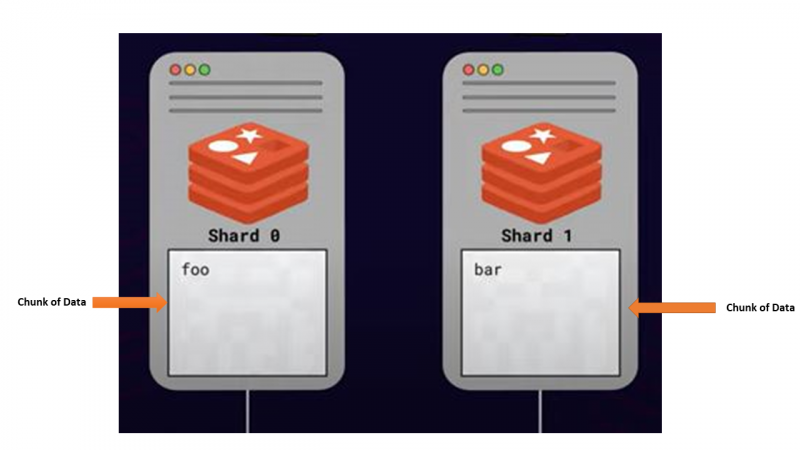
Hvordan sønderdeling udføres - Algoritmisk sønderdeling
En af de største bekymringer med sharding var, hvordan man lokaliserede en given nøgle blandt flere Redis-noder. Fordi en given nøgle kan gemmes i alle tilgængelige shards, er det ikke den bedste mulighed at forespørge alle shards for at finde en specifik nøgle. Så der burde være en måde at kortlægge hver nøgle til en specifik shard, og Redis bruger en algoritmisk sharding-strategi.
Den mest almindelige tilgang er at beregne en hashværdi ved hjælp af Redis-nøglenavnet og modulo. Derefter divideres det med de tilgængelige Redis-shards i systemet.
HASH_SLOT = CRC16(nøgle) mod 16384Det er en ganske god løsning, så længe det samlede antal skår er konstant. Hver gang du tilføjer en ny Reids-serverinstans, kan den resulterende værdi for en given nøgle ændre sig, da det samlede antal shards er steget. Det ender med at forespørge på det forkerte Redis-shard. Derfor bør du følge omdelingsprocessen ved at beregne det nye shard for hver nøgle og overføre data til den korrekte server, hvilket er besværligt og ikke en triviel opgave, hvis dit samlede shardantal stiger fra tid til anden.
Redis bruger en ny logisk enhed kaldet a hash slot for at forhindre dette problem. Flere hash-slots er tilgængelige for en given shard, og en enkelt hash-slot kan indeholde flere Redis-nøgler. Der er 16384 hash-slots i en Redis-databaseklynge, som forbliver uændret. Modulo divisionen udføres med antallet af hash slots i stedet for shard count. Det giver den korrekte position af hash-slottet for den angivne nøgle, selv når antallet af shards er steget. Det forenkler resharding-processen ved at flytte hash-slots fra et shard til det nye, der deler data på tværs af de forskellige Redis-instanser efter krav.
Fordele ved Redis Sharding
Redis sharding muliggør adskillige fordele for dit databasesystem med minimale ændringer.
Høj gennemstrømning
Da Redis er single-threaded, kan behandling af flere klientanmodninger ikke behandle parallelt ved brug af flere CPU-kerner. Så tilføjelse af nye shards eller serverforekomster garanterer, at du kan udføre Redis-operationer parallelt. Det øger operationerne per sekund i din Redis-database, hvilket til sidst giver dig høj gennemstrømning.
Høj tilgængelighed
Med sharding-tilgangen kan Redis-klyngen opsætte en master-replika-arkitektur, der sikrer høj tilgængelighed og holdbarhed.
Læs replikaer
Sharing gør det muligt for dig at beholde en nøjagtig kopi af dine data og levere læseoperationer gennem separate Redis-instanser, hvilket øger ydeevnen af din læseforespørgselsudførelse.
Bortset fra disse fordele kan sharding forårsage split-brain situationer, når du har et lige antal shards i Redis klyngen. Så det anbefales at beholde et ulige antal shards i din Redis-klynge.
Konklusion
For at opsummere opsummerer Redis sharding data mellem flere servere, hvilket muliggør skalering og høj gennemstrømning af din database. Som diskuteret bruger Redis en algoritmisk sharding-strategi til at pege klientanmodninger til det korrekte shard. Dette har nogle ulemper, når det samlede antal skår stiger. Så i stedet for det samlede antal shards, bruger Redis antallet af hash-slots til at beregne det passende shard. Med sharding introduceret giver Redis-databaser høj tilgængelighed, høj gennemstrømning og høj ydeevne.