Denne vejledning vil forklare, hvordan man opretter crawlere til at hente data fra S3-bøtten.
Hvordan oprettes crawler for at hente data fra S3 Bucket?
For at oprette en webcrawler i AWS, besøg ' AWS lim ” tjeneste fra Amazon dashboard:
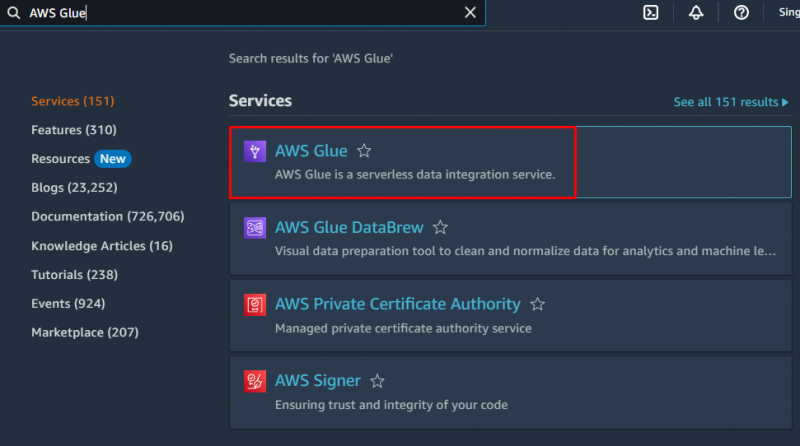
Klik på ' Databaser ”-knap fra afsnittet Datakatalog for at oprette en database:
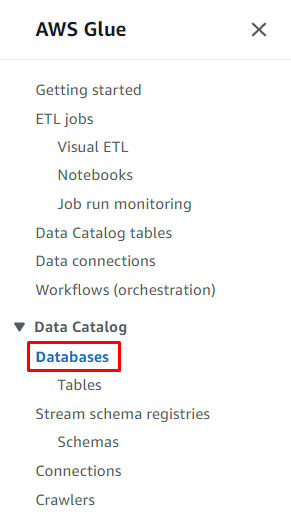
Klik på ' Tilføj database knappen for at starte konfigurationen:
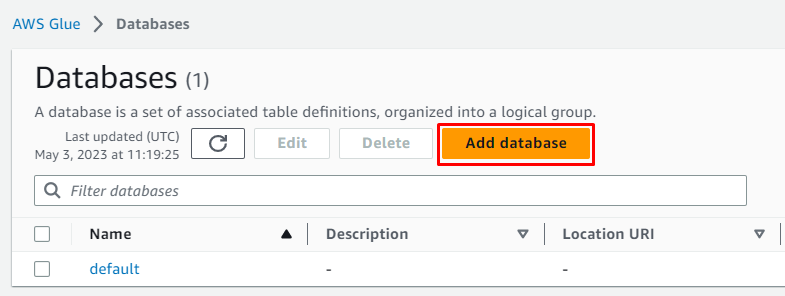
Indtast navnet på databasen og lad alt være som det er valgfrit, før du klikker på ' Opret database ” knap:
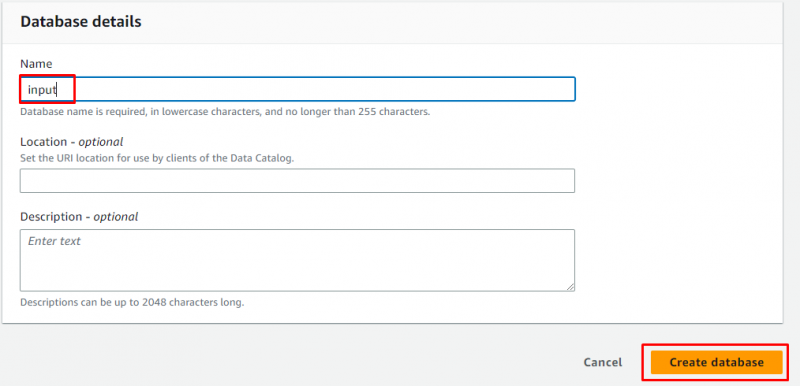
Databasen er blevet oprettet med succes:
Derefter skal du blot gå til ' Crawlere ” side ved at klikke på den fra venstre panel:
Klik på ' Opret crawler ” knap:

Indtast navnet på webcrawleren og klik på ' Næste ” knap:

Klik på ' Tilføj en datakilde knappen for at vælge datakilden:
Besøg S3-tjenesten for at kontrollere stien, hvor dataene er gemt:
Gå ind i S3-bøtten, hvor dataene uploades. Brugeren kan skab en spand og upload data på det fra AWS S3 dashboard:

Klik på ' Gennemse S3 knappen for at vælge stien til dataene:
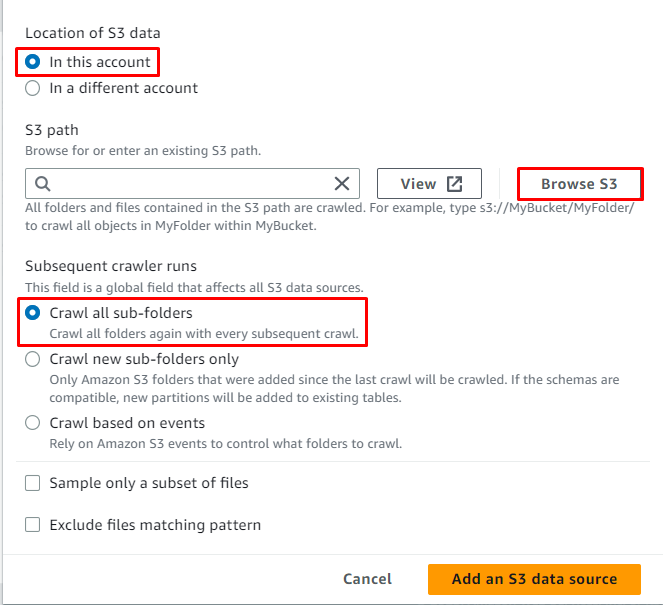
Vælg mappen, der indeholder dataene, og klik derefter på ' Vælge ” knap:

S3-stien er valgt, klik nu på ' Tilføj en S3-datakilde ” knap:

Når datakilden er tilføjet, skal du blot klikke på ' Næste ” knap:
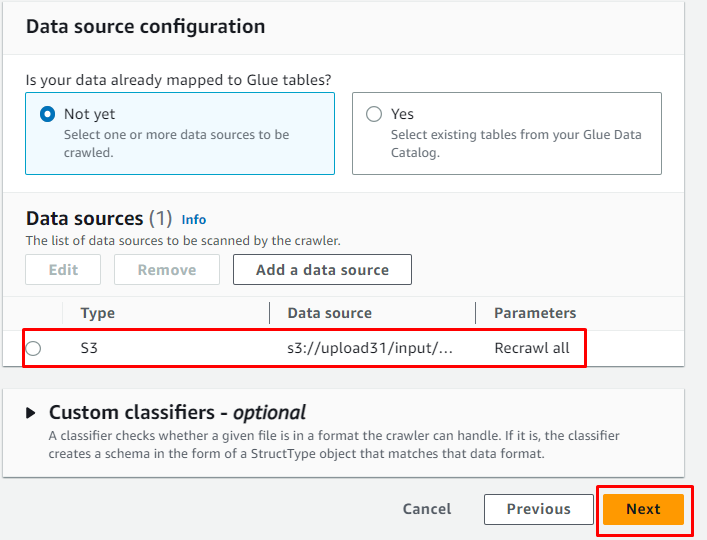
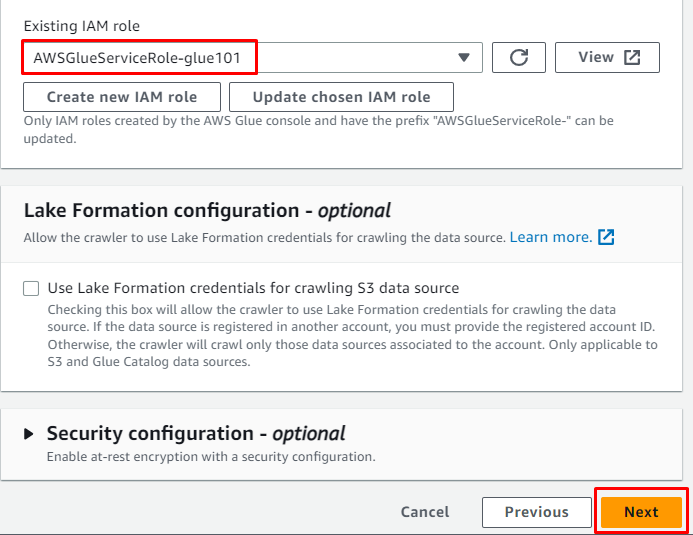
Tilføj IAM-rollen, og klik derefter på ' Næste ” knap:
Indtast den tidligere oprettede måldatabase, og skriv derefter navnet på tabellen:
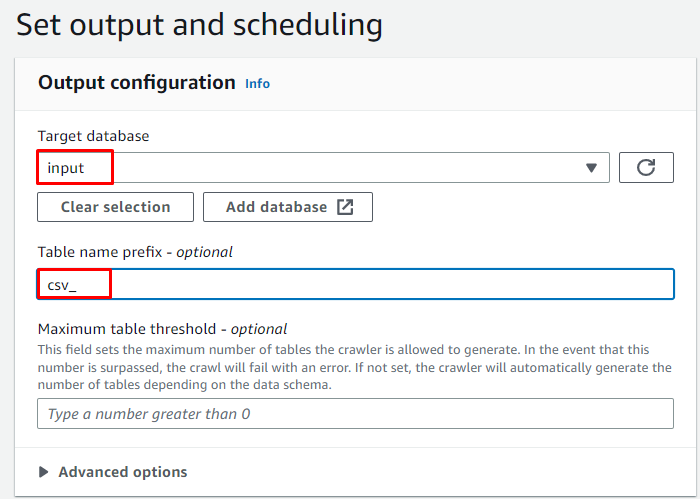
Vælg On demand-planen for webcrawleren, og klik på ' Næste ” knap:
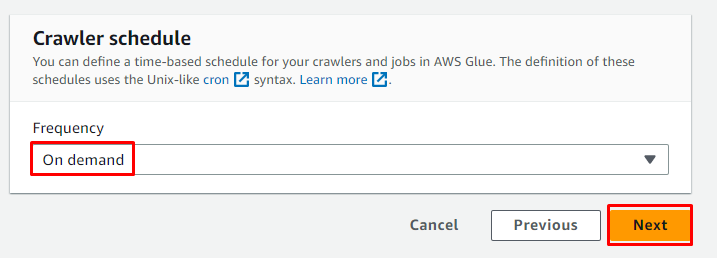
Gennemgå webcrawleren og klik på ' Opret crawler ” knap:
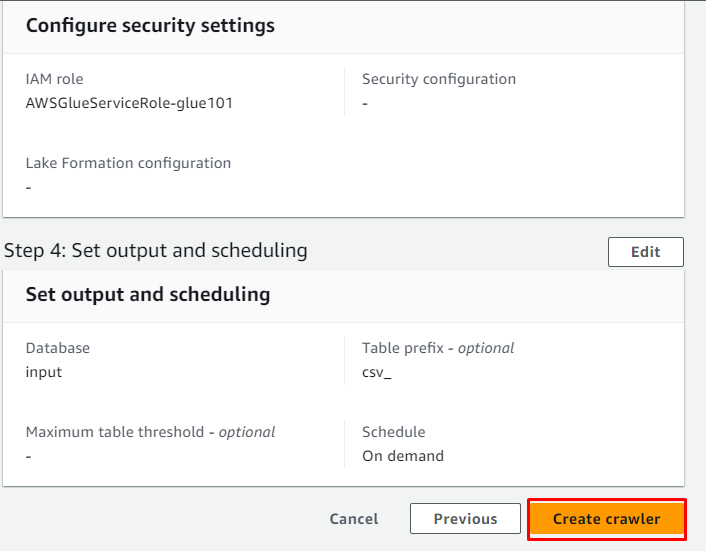
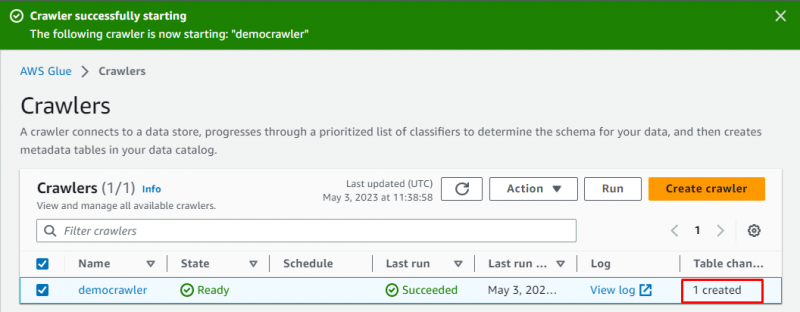
Webcrawleren er blevet oprettet, klik på ' Løb knappen efter at have valgt den:

Det vil tage et par øjeblikke at køre crawleren, og det vil hente data og oprette en tabel til at gemme dataene:
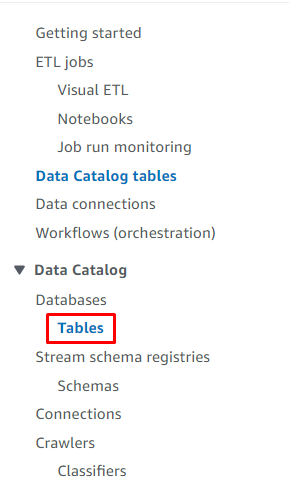
Gå ind i ' Tabeller ”-side fra Glue-dashboardet:
Vælg tabellen ved at klikke på dens navn:
Fortællingsdetaljerne er blevet vist indeholdende metadataene for de hentede data:
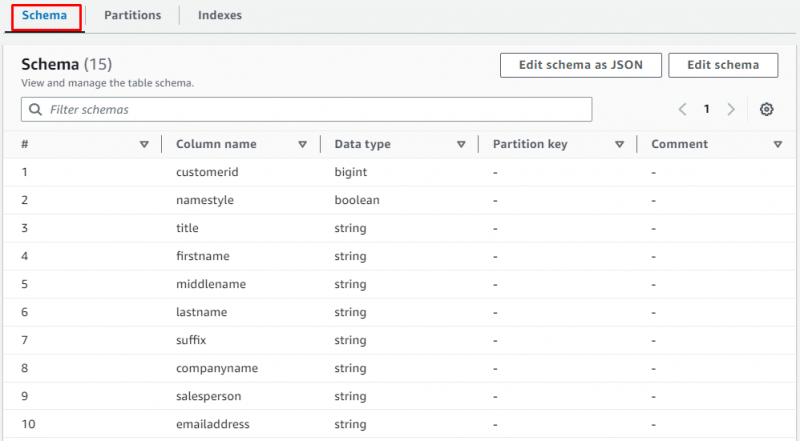
Rul ned på siden og vælg sektionen for at se tabellen med dataene:
Det handler om at oprette en crawler til at hente data fra S3-bøtten.
Konklusion
For at oprette en crawler til at hente data fra S3-bøtten skal du oprette en database på AWS Glue, hvori de crawlede data vil blive gemt. Konfigurer crawleren fra Glue-dashboardet ved at angive datakilden (S3-bøtte) og måldatabasen. Kør crawleren og hent dataene fra S3-bøtten til databasetabellen, som denne vejledning har forklaret grundigt.