Hurtig disposition
Dette indlæg vil demonstrere følgende:
- Sådan tilføjes hukommelse til OpenAI Functions Agent i LangChain
- Trin 1: Installation af Frameworks
- Trin 2: Opsætning af miljøer
- Trin 3: Import af biblioteker
- Trin 4: Opbygning af database
- Trin 5: Upload af database
- Trin 6: Konfiguration af sprogmodel
- Trin 7: Tilføjelse af hukommelse
- Trin 8: Initialisering af agenten
- Trin 9: Test af agenten
- Konklusion
Hvordan tilføjes hukommelse til OpenAI Functions Agent i LangChain?
OpenAI er en Artificial Intelligence (AI) organisation, der blev dannet i 2015 og var en non-profit organisation i begyndelsen. Microsoft har investeret en masse formuer siden 2020, da Natural Language Processing (NLP) med AI har boomet med chatbots og sprogmodeller.
Opbygning af OpenAI-agenter gør det muligt for udviklerne at få mere læsbare og direkte resultater fra internettet. Tilføjelse af hukommelse til agenterne giver dem mulighed for bedre at forstå konteksten af chatten og gemme de tidligere samtaler i deres hukommelse. For at lære processen med at tilføje hukommelse til OpenAI-funktionsagenten i LangChain skal du blot gennemgå følgende trin:
Trin 1: Installation af Frameworks
Først og fremmest skal du installere LangChain-afhængighederne fra 'langkæde-eksperimentel' ramme ved hjælp af følgende kode:
pip installer langkæde - eksperimentel
Installer 'google-søgeresultater' modul for at hente søgeresultaterne fra Google-serveren:
pip installer google - Søg - resultater 
Installer også OpenAI-modulet, der kan bruges til at bygge sprogmodellerne i LangChain:
pip installer openai 
Trin 2: Opsætning af miljøer
Når du har fået modulerne, skal du konfigurere miljøerne ved hjælp af API-nøglerne fra OpenAI og SerpAPi konti:
importere duimportere getpass
du. rundt regnet [ 'OPENAI_API_KEY' ] = getpass. getpass ( 'OpenAI API-nøgle:' )
du. rundt regnet [ 'SERPAPI_API_KEY' ] = getpass. getpass ( 'Serpapi API-nøgle:' )
Udfør ovenstående kode for at indtaste API-nøglerne for at få adgang til både miljøet, og tryk på enter for at bekræfte:
Trin 3: Import af biblioteker
Nu hvor opsætningen er færdig, skal du bruge afhængighederne installeret fra LangChain til at importere de nødvendige biblioteker til opbygning af hukommelsen og agenter:
fra langchain. kæder importere LLMMathChainfra langchain. llms importere OpenAI
#get bibliotek for at søge fra Google over internettet
fra langchain. forsyningsselskaber importere SerpAPIWrapper
fra langchain. forsyningsselskaber importere SQLDatabase
fra langchain_experimental. sql importere SQLDatabaseChain
#få bibliotek til at bygge værktøjer til initialisering af agenten
fra langchain. agenter importere AgentType , Værktøj , initialize_agent
fra langchain. chat_modeller importere ChatOpenAI
Trin 4: Opbygning af database
For at komme videre med denne vejledning skal vi bygge databasen og oprette forbindelse til agenten for at udtrække svar fra den. For at bygge databasen er det nødvendigt at downloade SQLite ved hjælp af denne guide og bekræft installationen ved hjælp af følgende kommando:
sqlite3Kørsel af ovenstående kommando i Windows Terminal viser den installerede version af SQLite (3.43.2):
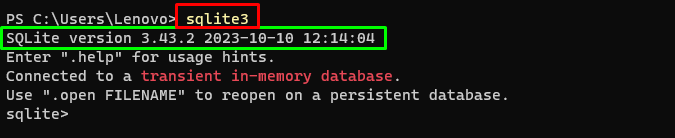
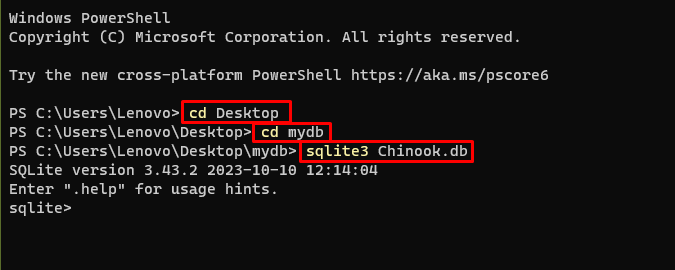
Derefter skal du blot gå til den mappe på din computer, hvor databasen vil blive bygget og gemt:
cd skrivebordcd mydb
sqlite3 Chinook. db
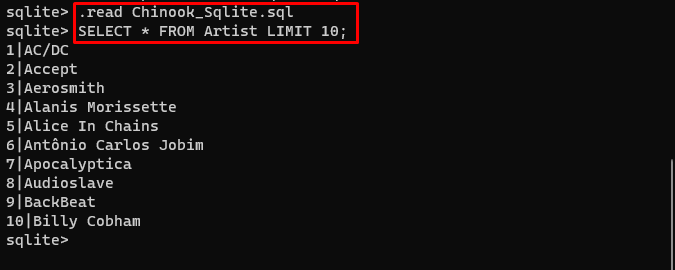
Brugeren kan blot downloade indholdet af databasen fra denne link i mappen og udfør følgende kommando for at bygge databasen:
. Læs Chinook_Sqlite. sqlVÆLG * FRA Artist LIMIT 10 ;
Databasen er blevet opbygget med succes, og brugeren kan søge efter data fra den ved hjælp af forskellige forespørgsler:
Trin 5: Upload af database
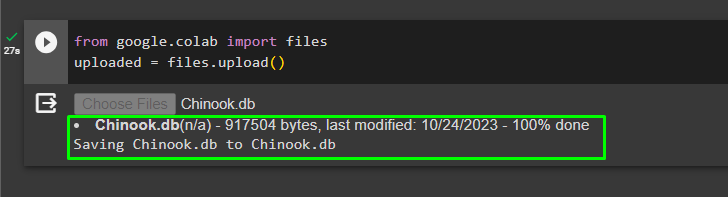
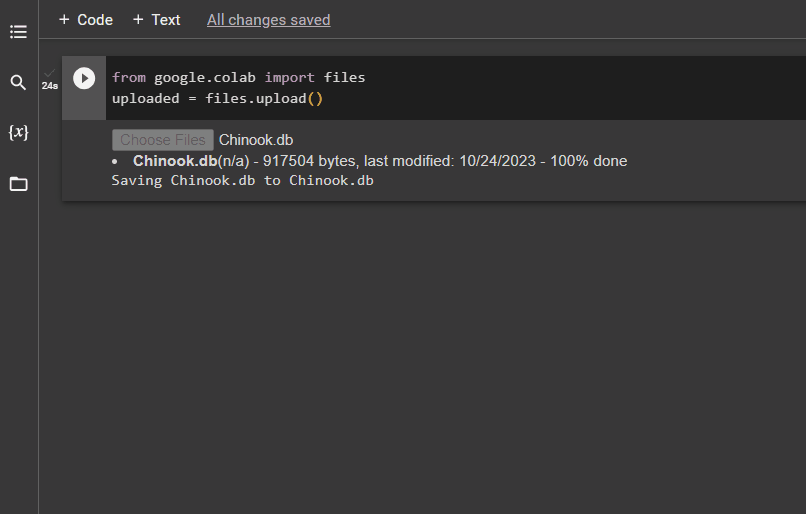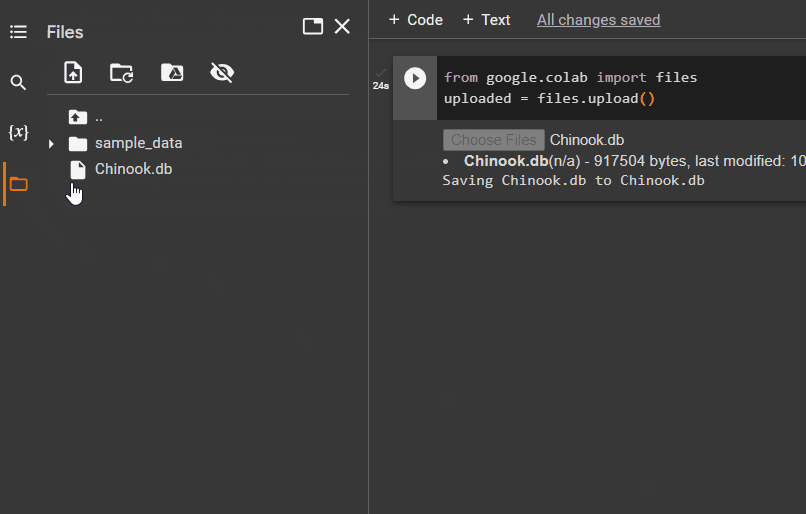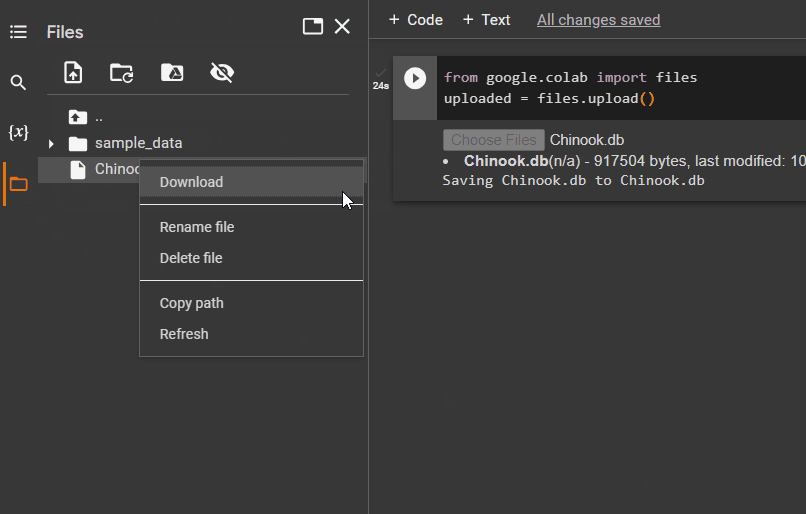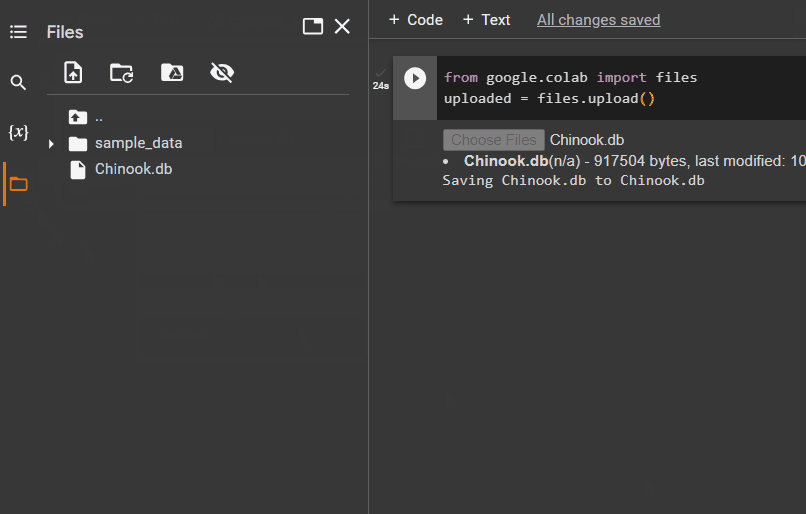
Når databasen er bygget med succes, skal du uploade '.db' fil til Google Collaboratory ved hjælp af følgende kode:
fra google. ET AL importere fileruploadet = filer. upload ( )
Vælg filen fra det lokale system ved at klikke på 'Vælg filer' knappen efter at have udført ovenstående kode:
Når filen er uploadet, skal du blot kopiere stien til filen, som skal bruges i næste trin:
Trin 6: Konfiguration af sprogmodel
Byg sprogmodellen, kæderne, værktøjerne og kæderne ved hjælp af følgende kode:
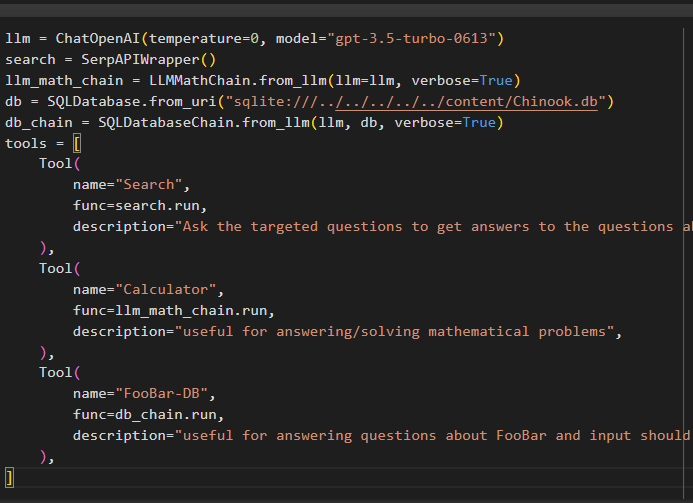
llm = ChatOpenAI ( temperatur = 0 , model = 'gpt-3.5-turbo-0613' )Søg = SerpAPIWrapper ( )
llm_math_chain = LLMMathChain. fra_llm ( llm = llm , ordrig = Rigtigt )
db = SQLDatabase. fra_uri ( 'sqlite:///../../../../../content/Chinook.db' )
db_kæde = SQLDatabaseChain. fra_llm ( llm , db , ordrig = Rigtigt )
værktøjer = [
Værktøj (
navn = 'Søg' ,
func = Søg. løb ,
beskrivelse = 'Stil de målrettede spørgsmål for at få svar på spørgsmålene om de seneste affærer' ,
) ,
Værktøj (
navn = 'Lommeregner' ,
func = llm_math_chain. løb ,
beskrivelse = 'nyttigt til at besvare/løse matematiske problemer' ,
) ,
Værktøj (
navn = 'FooBar-DB' ,
func = db_kæde. løb ,
beskrivelse = 'nyttigt til at besvare spørgsmål om FooBar, og input bør være i form af et spørgsmål, der indeholder fuld kontekst' ,
) ,
]
- Det llm variabel indeholder konfigurationerne af sprogmodellen ved hjælp af ChatOpenAI()-metoden med navnet på modellen.
- Søgningen variablen indeholder metoden SerpAPIWrapper() til at bygge værktøjerne til agenten.
- Byg den llm_math_chain for at få svarene relateret til Mathematics-domænet ved hjælp af LLMMathChain()-metoden.
- Variablen db indeholder stien til filen, som har indholdet af databasen. Brugeren skal kun ændre den sidste del, som er 'content/Chinook.db' af stien holder “sqlite:///../../../../../” det samme.
- Byg en anden kæde til at besvare forespørgsler fra databasen ved hjælp af db_kæde variabel.
- Konfigurer værktøjer som f.eks Søg , lommeregner , og FooBar-DB til henholdsvis at søge i svaret, besvare matematiske spørgsmål og forespørgsler fra databasen:
Trin 7: Tilføjelse af hukommelse
Når du har konfigureret OpenAI-funktionerne, skal du blot bygge og tilføje hukommelsen til agenten:
fra langchain. prompter importere Beskeder Pladsholderfra langchain. hukommelse importere ConversationBufferMemory
agent_kwargs = {
'extra_prompt_meddelelser' : [ Beskeder Pladsholder ( variabel_navn = 'hukommelse' ) ] ,
}
hukommelse = ConversationBufferMemory ( memory_key = 'hukommelse' , return_beskeder = Rigtigt )
Trin 8: Initialisering af agenten
Den sidste komponent, der skal bygges og initialiseres, er agenten, der indeholder alle komponenter som f.eks llm , værktøj , OPENAI_FUNCTIONS og andre, der skal bruges i denne proces:
agent = initialize_agent (værktøjer ,
llm ,
agent = AgentType. OPENAI_FUNCTIONS ,
ordrig = Rigtigt ,
agent_kwargs = agent_kwargs ,
hukommelse = hukommelse ,
)
Trin 9: Test af agenten
Til sidst skal du teste agenten ved at starte chatten ved at bruge ' Hej ” besked:
agent. løb ( 'Hej' ) 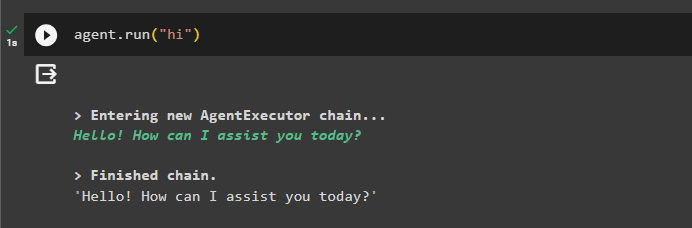
Tilføj nogle oplysninger til hukommelsen ved at køre agenten med den:
agent. løb ( 'mit navn er John snow' ) 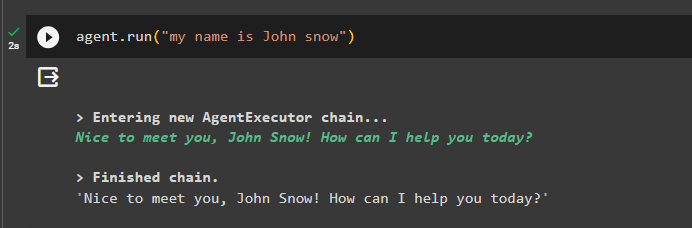
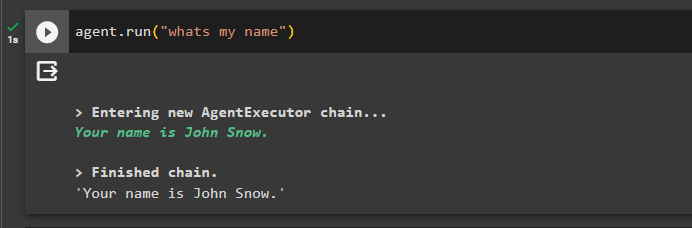
Test nu hukommelsen ved at stille spørgsmålet om den forrige chat:
agent. løb ( 'hvad er mit navn' )Agenten har svaret med navnet hentet fra hukommelsen, så hukommelsen kører med agenten:
Det er alt for nu.
Konklusion
For at tilføje hukommelsen til OpenAI-funktionsagenten i LangChain skal du installere modulerne for at få afhængighederne til at importere bibliotekerne. Derefter skal du blot bygge databasen og uploade den til Python-notesbogen, så den kan bruges med modellen. Konfigurer modellen, værktøjerne, kæderne og databasen, før du tilføjer dem til agenten og initialiser den. Før du tester hukommelsen, skal du bygge hukommelsen ved hjælp af ConversationalBufferMemory() og tilføje den til agenten, før du tester den. Denne vejledning har uddybet, hvordan man tilføjer hukommelse til OpenAI-funktionsagenten i LangChain.