5.1 Indledning
Operativsystemet til Commodore-64 computeren leveres med computeren i Read Only Memory (ROM). Antallet af hukommelsesbyteplaceringer for Commodore-64 varierer fra $0000 til $FFFF (dvs. 000016 til FFFF16, som er 010 til 65,53510). Operativsystemet er fra $E000 til $FFFF (dvs. 57.34410 til 65.53610).
Hvorfor studere Commodore-64-operativsystemet
Hvorfor studere Commodore-64-operativsystemet i dag, når det var et operativsystem på en computer, der blev udgivet i 1982? Nå, Commodore-64 computeren bruger Central Processing Unit 6510, som er en opgradering (men ikke en stor opgradering) af 6502 µP.
6502 µP produceres stadig i dag i stort antal; det er ikke længere til hjemme- eller kontorcomputere, men til elektriske og elektroniske apparater (enheder). 6502 µP er også enkel at forstå og betjene sammenlignet med de andre mikroprocessorer på dens tid. Som et resultat af disse er det en af de bedste (hvis ikke den bedste) mikroprocessor, der skal bruges til at undervise i assemblersproget.
65C02 µP, stadig af 6502-mikroprocessorklassen, har 66 monteringssprogsinstruktioner, som alle endda kan læres udenad. Moderne mikroprocessorer har mange monteringssprogsinstruktioner og kan ikke læres udenad. Hver µP har sit eget assemblersprog for sig selv. Ethvert operativsystem, det være sig nyt eller gammelt, er et assemblersprog. Med det er assemblersproget 6502 godt at bruge til at lære styresystemet for begyndere. Efter at have lært et operativsystem, som det til Commodore-64, kan et moderne styresystem nemt læres ved at bruge det som grundlag.
Dette er ikke kun forfatterens (mig selv) mening. Det er en stigende tendens i verden. Der bliver skrevet flere og flere artikler på internettet til forbedret Commodore-64 styresystem for at få det til at ligne et moderne styresystem. Moderne operativsystemer er forklaret i kapitlet efter det næste.
Bemærk : Commodore-64 OS (Kernal) fungerer stadig godt med moderne input- og outputenheder (ikke alle).
Otte-bit computer
I en otte-bit mikrocomputer, såsom Commodore 64, lagres, overføres og manipuleres informationen i form af otte-bit binære koder.
Hukommelseskort
Et hukommelseskort er en skala, som opdeler hele hukommelsesområdet i mindre intervaller af forskellige størrelser og viser, hvad (subrutine og/eller variabel) der hører til hvilket sortiment. En variabel er en etiket, der svarer til en bestemt hukommelsesadresse, der har en værdi. Etiketter bruges også til at identificere starten af underrutiner. Men i dette tilfælde er de kendt som navnene på underrutinerne. En subrutine kan simpelthen omtales som en rutine.
Hukommelseskortet (layoutet) i det foregående kapitel er ikke detaljeret nok. Det er ret simpelt. Hukommelseskortet på Commodore-64 computeren kan vises med tre niveauer af detaljer. Når den vises på mellemniveau, har Commodore-64 computeren forskellige hukommelseskort. Standardhukommelseskort for Commodore-64 computeren på mellemniveau er:

Fig. 5.11 Commodore-64 Hukommelseskort
I de dage var der et populært computersprog kaldet BASIC. Mange computerbrugere havde brug for at kende nogle minimum BASIC sprogkommandoer, såsom at indlæse et program fra disketten (disken) til hukommelsen, at køre (udføre) et program i hukommelsen og at afslutte (lukke) et program. Når BASIC-programmet kører, skal brugeren indlæse dataene linje for linje. Det er ikke som i dag, hvor en applikation (en række programmer danner en applikation) er skrevet i et højt niveau sprog med vinduer, og brugeren skal bare passe de forskellige data ind på specialiserede steder i et vindue. I nogle tilfælde skal du bruge vi en mus til at vælge de forudbestilte data. BASIC var et højt niveau sprog på det tidspunkt, men er ret tæt på assemblersproget.
Bemærk, at det meste af hukommelsen optages af BASIC i standardhukommelseskortet. BASIC har kommandoer (instruktioner), som udføres af det, der er kendt som BASIC Interpreter. Faktisk er BASIC-fortolkeren i ROM fra $A000-lokationen til $BFFF (inklusive), som angiveligt er et RAM-område. Dette er 8 Kbytes er ret stort på det tidspunkt! Det er faktisk i ROM på det sted i hele hukommelsen. Det har samme størrelse som operativsystemet fra $E000 til $FFFF (inklusive). De programmer, der er skrevet i BASIC, er også placeret i intervallet $0200 til $BFFF.
RAM'en til brugersammensætningssprogprogrammet er fra $C000 til $CFFF, kun 4 Kbytes ud af 64 Kbytes. Så hvorfor bruger eller lærer vi assemblersproget? De nye og gamle operativsystemer er af assemblersprog. Operativsystemet på Commodore-64 er i ROM, fra $E000 til $FFFF. Det er skrevet i 65C02 µP (6510 µP) assemblersproget. Den består af subrutiner. Brugerprogrammet i assemblersprog skal kalde disse underrutiner for at kunne interagere med eksterne enheder (input- og outputenheder). At forstå Commodore-64-operativsystemet i assemblersprog gør det muligt for eleven at forstå operativsystemerne hurtigt, på en langt mindre kedelig måde. Igen, i de dage blev mange brugerprogrammer til Commodore-64 skrevet i BASIC og ikke i assemblersprog. Forsamlingssprogene i de dage blev brugt mere af programmører selv til tekniske formål.
Kernal, stavet som K-e-r-n-a-l, er operativsystemet til Commodore-64. Den leveres med Commodore-64 computeren i ROM og ikke på en disk (eller diskette). Kernal består af underrutiner. For at få adgang til periferiudstyret skal brugerprogrammet i assemblersprog (maskinsprog) bruge disse underrutiner. Kernal skal ikke forveksles med kerne, der staves som K-e-r-n-e-l i de moderne operativsystemer, selvom de næsten er det samme.
Hukommelsesområdet fra $C000 (49.15210) til $CFFF (6324810) på 4 Kbytes10 af hukommelsen er enten RAM eller ROM. Når det er RAM, bruges det til at få adgang til de eksterne enheder. Når det er ROM, bruges det til at udskrive tegnene på skærmen (monitoren). Det betyder, at tegnene enten udskrives på skærmen, eller at de eksterne enheder bliver tilgået ved brug af denne del af hukommelsen. Der er en bank af ROM (karakter-ROM) i systemenheden (bundkortet), som er koblet ind og ud af hele hukommelsespladsen for at opnå dette. Brugeren bemærker muligvis ikke skiftet.
Hukommelsesområdet fra $0100 (256 10 ) til $01FF (511 10 ) er stakken. Det bruges af både operativsystemet og brugerprogrammerne. Stakkens rolle blev forklaret i det forrige kapitel af dette online karrierekursus. Hukommelsens areal fra $0000 (0 10 ) til $00FF (255 10 ) bruges af operativsystemet. Der er tildelt mange pointers.
Kernal hoppebord
Kernal har rutiner, der kaldes af brugerprogrammet. Efterhånden som nye versioner af operativsystemet kom ud, ændrede adresserne på disse rutiner sig. Det betyder, at brugerprogrammerne ikke længere kunne fungere med de nye OS-versioner. Dette skete ikke, fordi Commodore-64 leverede et springbord. Springtabellen er en liste med 39 poster. Hver post i tabellen har tre adresser (bortset fra de sidste 6 bytes), som aldrig ændrede sig selv med versionsændringen af operativsystemet.
Den første adresse på en post har en JSR-instruktion. De næste to adresser består af en to-byte pointer. Denne to-byte pointer er adressen (eller den nye adresse) på en faktisk rutine, som stadig er i OS ROM'en. Pointerindholdet kunne ændre sig med de nye OS-versioner, men de tre adresser for hver springtabelpost ændres aldrig. Overvej f.eks. $FF81-, $FF82- og $FF83-adresserne. Disse tre adresser er til rutinen til at initialisere skærm- og tastaturkredsløbene (registrene) på bundkortet. $FF81-adressen har altid op-koden (én byte) af JSR. $FF82- og $FF83-adresserne har den gamle eller nye adresse på subrutinen (stadig i OS ROM) til at udføre initialiseringen. På et tidspunkt havde $FF82- og $FF83-adresserne indholdet (adressen) på $FF5B, som kunne ændre sig med den næste OS-version. $FF81-, $FF82- og $FF83-adresserne på jump-tabellen ændres dog aldrig.
For hver indtastning af tre adresser har den første adresse med JSR en etiket (navn). Etiketten til $FF81 er PCINT. PCINT ændres aldrig. Så for at initialisere skærm- og tastaturregistrene kan programmøren blot skrive 'JSR PCINT', som fungerer for alle versioner af Commodore-64 OS. Placeringen (startadressen) af den faktiske underrutine, f.eks. $FF5B, kan ændre sig over tid med forskellige operativsystemer. Ja, der er mindst to JSR-instruktioner involveret i brugerprogrammet, der bruger ROM OS. I brugerprogrammet er der en JSR-instruktion, der hopper til en post i springtabellen. Med undtagelse af de sidste seks adresser i springtabellen har den første adresse på en post i springtabellen en JSR-instruktion. I Kernal kan nogle underrutiner kalde de andre underrutiner.
Kernal-springtabellen begynder fra $FF81 (inklusive) og går opad i grupper af tre, bortset fra de sidste seks bytes, som er tre pointere med lavere byteadresser: $FFFA, $FFFC og $FFFE. Alle ROM OS-rutiner er genbrugelige koder. Så brugeren behøver ikke at omskrive dem.
Blokdiagram af Commodore-64 System Unit
Følgende diagram er mere detaljeret end det foregående kapitel:
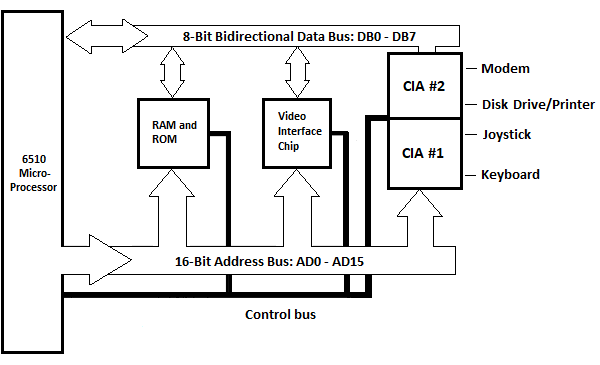
Fig. 5.12 Blokdiagram af Commodore_64 System Unit
ROM og RAM er vist som én blok her. Video Interface Chip (IC) til håndtering af information til skærmen, som ikke blev vist i forrige kapitel, er vist her. Den enkelte blok for input/output-enheder, som er vist i forrige kapitel, er vist her som to blokke: CIA #1 og CIA #2. CIA står for Complex Interface Adapter. Hver af dem har to parallelle otte-bit porte (ikke at forveksle med eksterne porte på en lodret overflade af systemetheden) kaldet port A og port B. CIA'erne er forbundet til fem eksterne enheder i denne situation. Enhederne er tastatur, joystick, diskdrev/printer og et modem. Printeren er tilsluttet bag på diskdrevet. Der er også et Sound Interface Device Circuit og et Programmerbart Logic Array Circuit, som ikke er vist.
Alligevel er der en Character ROM, som kan byttes med begge CIA'er, når et tegn sendes til skærmen, og det ikke vises i blokdiagrammet.
RAM-adresserne fra $D000 til $DFFF for input/output-kredsløb i mangel af tegn-ROM har følgende detaljerede hukommelseskort:
| Tabel 5.11 Detaljeret hukommelseskort fra $D000 til $DFFF |
||
|---|---|---|
| Underadresseområde | Kredsløb | Størrelse (bytes) |
| D000 – D3FF | VIC (Video Interface Controller (Chip)) | 1K |
| D400 – D7FF | SID (lydkredsløb) | 1K |
| D800 – DBFF | Farve RAM | 1K Nibbles |
| DC00 – DCFF | CIA #1 (tastatur, joystick) | 256 |
| DD00 – DDFF | CIA #2 (seriel bus, brugerport/RS-232) | 256 |
| DE00 – DEF | Åbn I/O-slot #1 | 256 |
| DF00 – DFFF | Åbn I/O-slot #2 | 256 |
5.2 De to komplekse grænsefladeadaptere
Der er to særlige integrerede kredsløb (IC'er) i Commodore-64 systemenheden, og hver af dem kaldes Complex Interface Adapter. Disse to chips bruges til at forbinde tastaturet og andre eksterne enheder til mikroprocessoren. Med undtagelse af VIC'en og skærmen passerer alle input/output-signaler mellem mikroprocessoren og periferiudstyret gennem disse to IC'er. Med Commodore-64 er der ingen direkte kommunikation mellem hukommelsen og enhver perifer enhed. Kommunikationen mellem hukommelsen og enhver perifer enhed passerer gennem mikroprocessorakkumulatoren, og en af disse er CIA-adaptere (IC'er). IC'erne omtales som CIA #1 og CIA #2. CIA står for Complex Interface Adapter.
Hver CIA har 16 registre. Med undtagelse af timer/tæller-registrene i CIA, er hvert register 8-bit bredt og har en hukommelsesadresse. Hukommelsesregisteradresserne for CIA #1 er fra $DC00 (56320 10 ) til $DC0F (56335 10 ). Hukommelsesregisteradresserne for CIA #2 er fra $DD00 (56576 10 ) til $DD0F (56591 10 ). Selvom disse registre ikke er i ICs hukommelse, er de en del af hukommelsen. I det mellemliggende hukommelseskort inkluderer I/O-området fra $D000 til $DFFF CIA-adresserne fra $DC00 til $DC0F og fra $DD00 til $DD0F. Det meste af RAM I/O-hukommelsesområdet fra $D000 til $DFFF kan udskiftes med hukommelsesbanken for tegn-ROM'en til skærmtegn. Det er derfor, når karaktererne sendes til skærmen, kan periferiudstyret ikke fungere; selvom brugeren måske ikke bemærker dette, da skiftningen frem og tilbage er hurtig.
Der er to registre i CIA #1 kaldet Port A og Port B. Deres adresser er henholdsvis $DC00 og $DC01. Der er også to registre i CIA #2 kaldet Port A og Port B. Selvfølgelig er deres adresser forskellige; de er henholdsvis $DD00 og $DD01.
Port A eller Port B i begge CIA er en parallelport. Det betyder, at den kan sende data til den perifere enhed i otte bit på én gang eller modtage data fra mikroprocessoren i otte bit på én gang.
Tilknyttet port A eller port B er et Data Direction Register (DDR). Dataretningsregisteret for port A i CIA #1 (DDRA1) er ved hukommelsesbyte-placeringen på $DC02. Dataretningsregisteret for port B i CIA #1 (DDRB1) er ved hukommelsesbyteplaceringen $DC03. Dataretningsregistret for port A på CIA #2 (DDRA2) er ved hukommelsesbyte-placeringen på $DD02. Dataretningsregisteret for port B i CIA #2 (DDRB2) er ved hukommelsesbyteplaceringen $DD03.
Nu kan hver bit for port A eller port B indstilles af det tilsvarende dataretningsregister til at være input eller output. Input betyder, at informationen går fra den perifere enhed til mikroprocessoren gennem en CIA. Output betyder, at informationen går fra mikroprocessoren til den perifere enhed gennem en CIA.
Hvis en celle i en port (register) skal indtastes, er den tilsvarende bit i dataretningsregisteret 0. Hvis en celle i en port (register) skal udlæses, er den tilsvarende bit i dataretningsregisteret 1. I de fleste tilfælde er alle 8-bits af en port programmeret til enten at være input eller output. Når computeren er tændt, er port A programmeret til output, og port B er programmeret til input. Følgende kode gør CIA #1 port A som output og CIA #1 port B som input:
LDA #$FF
STA DDRA1 ; $DC00 er instrueret af $DC02
LDA #$00
STA DDRB1; $DC01 er instrueret af $DC03
DDRA1 er etiketten (variabelnavn) for hukommelsesbyteplaceringen af $DC02, og DDRB1 er etiketten (variabelnavn) for hukommelsesbyteplaceringen af $DC03. Den første instruktion indlæser 11111111 til akkumulatoren af µP. Den anden instruktion kopierer dette til dataretningsregisteret for port A i CIA-nr. 1. Den tredje instruktion indlæser 00000000 til akkumulatoren af µP. Den fjerde instruktion kopierer dette til dataretningsregisteret for port B i CIA-nr. 1. Denne kode er i en af underrutinerne i operativsystemet, der udfører denne initialisering ved computerens opstart.
Hver CIA har en afbrydelsestjenesteanmodningslinje til mikroprocessoren. Den fra CIA #1 går til IRQ pin af µP. Den fra CIA #2 går til NMI pin af µP. Huske på, at NMI er af højere prioritet end IRQ .
5.3 Keyboard Assembly Sprogprogrammering
Der er kun tre mulige interrupts for Commodore-64: IRQ , BRK og NMI . Hop tabel pointer til IRQ er på $FFFE- og $FFFF-adresserne i ROM (operativsystem), hvilket svarer til en underrutine, der stadig er i OS (ROM). Springtabelmarkøren for BRK er på $FFFC- og $FFFD-adresserne i OS, hvilket svarer til en underrutine, der stadig er i OS (ROM). Hop tabel pointer til NMI er på $FFFA- og $FFFB-adresserne i OS, hvilket svarer til en underrutine, der stadig er i OS (ROM). For IRQ , der er faktisk to underrutiner. Så BRK-softwareafbrydelsen (instruktionen) har sin egen springtabelmarkør. Hop tabel pointer til IRQ fører til koden, som afgør, om det er hardwareafbrydelsen eller softwareafbrydelsen, der er aktiveret. Hvis det er hardwareafbrydelsen, skal rutinen for IRQ Hedder. Hvis det er softwareafbrydelsen (BRK), kaldes rutinen for BRK. I en af OS-versionerne er subrutinen til IRQ er på $EA31 og subrutinen for BRK er på $FE66. Disse adresser er under $FF81, så de er ikke hoppetabelposter, og de kan ændre sig med OS-versionen. Der er tre rutiner af interesse i dette emne: den, der kontrollerer, om der er trykket på en tast eller en BRK, den, der er på $FE43, og den, der også kan ændre sig med OS-versionen.
Commodore-64 computeren er som en enorm skrivemaskine (opad) i udseende uden udskrivningssektionen (hoved og papir). Tastaturet er tilsluttet CIA #1. CIA #1 scanner tastaturet hver 1/60 af et sekund på egen hånd uden programmeringsinterferens, som standard. Så hvert 1/60 af et sekund sender CIA #1 en IRQ til µP. Der er kun én IRQ pin ved µP, som kun kommer fra CIA #1. Den ene indgangspin af NMI af µP, som er forskellig fra IRQ , kommer kun fra CIA #2 (se den følgende illustration). BRK er faktisk en assemblerinstruktion, der er kodet i et brugerprogram.
Så hvert 1/60 sekund IRQ rutine, der peges på af $FFFE og $FFFF kaldes. Rutinen kontrollerer, om der trykkes på en tast, eller om BRK-instruktionen stødes på. Hvis der trykkes på en tast, kaldes rutinen til at håndtere tastetrykket. Hvis det er en BRK-instruktion, kaldes rutinen til at håndtere BRK. Er det ingen af delene, sker der ikke noget. Ingen af dem kan forekomme, men CIA #1 sender IRQ til µP hvert 1/60 sekund.
Tastaturkøen, også kendt som tastaturbufferen, er en række RAM-byteplaceringer fra $0277 til $0280 inklusive; 1010 bytes i alt. Dette er en First-IN-First-Out buffer. Det betyder, at den første karakter, der kommer, er den første, der forlader. Et vesteuropæisk tegn tager en byte.
Så mens programmet ikke bruger nogen tegn, når der trykkes på en tast, går nøglekoden ind i denne buffer (kø). Bufferen bliver ved med at blive fyldt, indtil der er ti tegn. Ethvert tegn, der trykkes på efter det tiende tegn, optages ikke. Det ignoreres, indtil mindst ét tegn er hentet (forbrugt) fra køen. Springtabellen har en indgang til en underrutine, som får det første tegn fra køen til mikroprocessoren. Det betyder, at den tager det første tegn, der går ind i køen, og sætter det i akkumulatoren af µP. Hop-tabel-underrutinen til at gøre dette kaldes GETIN (for Get-In). Den første byte for tre-byte-indgangen i springtabellen er mærket som GETIN (adresse $FFE4). De næste to bytes er pointeren (adressen), der peger på den faktiske rutine i ROM (OS). Det er programmørens ansvar at kalde denne rutine. Ellers vil tastaturbufferen forblive fuld, og alle de nyligt trykket på taster vil blive ignoreret. Værdien, der går ind i akkumulatoren, er den tilsvarende nøgle-ASCII-værdi.
Hvordan kommer nøglekoderne i køen i første omgang? Der er en jump table-rutine kaldet SCNKEY (til scanningsnøgle). Denne rutine kan kaldes af både software og hardware. I dette tilfælde kaldes det af et elektronisk (fysik) kredsløb i mikroprocessoren, når det elektriske signal IRQ er lav. Hvordan det præcist gøres, behandles ikke i dette online karrierekursus.
Koden til at hente den første nøglekode fra tastaturbufferen ind i akkumulatoren A er kun én linje:
HOP IND
Hvis tastaturbufferen er tom, placeres $00 i akkumulatoren. Husk at ASCII-koden for nul ikke er $00; det er $30. $00 betyder Nul. I et program kan der være et punkt, hvor programmet skal vente på et tastetryk. Koden til dette er:
VENT JSR GETIN
CMP #$00
FRØVENT
I den første linje er 'WAIT' en etiket, der identificerer RAM-adressen, hvor JSR-instruktionen er sat (tastet) ind. GETIN er også en adresse. Det er adressen på den første af de tilsvarende tre bytes i springtabellen. GETIN-posten, såvel som alle indtastningerne i springtabellen (undtagen de sidste tre), består af tre bytes. Den første byte af posten er JSR-instruktionen. De næste to bytes er adressen på kroppen af den faktiske GETIN-subrutine, som stadig er i ROM (OS), men under springtabellen. Så posten siger, at man skal hoppe til GETIN-underrutinen. Hvis tastaturkøen ikke er tom, sætter GETIN ASCII-nøglekoden for First-In-First-Out-køen i akkumulatoren. Hvis køen er tom, sættes Null ($00) i akkumulatoren.
Den anden instruktion sammenligner akkumulatorværdien med $00. Hvis det er $00, betyder det, at tastaturkøen er tom, og CMP-instruktionen sender 1 til Z-flaget i processorstatusregisteret (simpelthen kaldet statusregister). Hvis værdien i A ikke er $00, sender CMP-instruktionen 0 til Z-flaget i statusregistret.
Den tredje instruktion, som er 'BEQ WAIT', sender programmet tilbage til den første instruktion, hvis Z-flaget i statusregistret er 1. Den første, anden og tredje instruktion udføres gentagne gange i rækkefølge, indtil der trykkes på en tast på tastaturet . Hvis der aldrig trykkes på en tast, gentages cyklussen i det uendelige. Et kodesegment som dette skrives normalt med et tidskodesegment, som forlader løkken efter nogen tid, hvis der aldrig trykkes på en tast (se den følgende diskussion).
Bemærk : Tastaturet er standardinputenheden, og skærmen er standardoutputenheden.
5.4 Kanal, enhedsnummer og logisk filnummer
De ydre enheder, som dette kapitel bruger til at forklare Commodore-64-operativsystemet, er tastaturet, skærmen (skærmen), diskdrevet med diskette, printeren og modemmet, som forbindes via RS-232C-grænsefladen. For at kommunikationen kan finde sted mellem disse enheder og systemenheden (mikroprocessor og hukommelse), skal der etableres en kanal.
En kanal består af en buffer, enhedsnummer, et logisk filnummer og eventuelt en sekundær adresse. Forklaringen af disse udtryk er som følger:
En buffer
Bemærk fra det foregående afsnit, at når der trykkes på en tast, skal dens kode gå til en byteplacering i RAM med en serie på ti på hinanden følgende placeringer. Denne serie på ti placeringer er tastaturbufferen. Hver input- eller outputenhed (perifer enhed) har en række på hinanden følgende placeringer i RAM kaldet en buffer.
Enhedsnummer
Med Commodore-64 er enhver perifer enhed givet med et enhedsnummer. Følgende tabel viser de forskellige enheder og deres numre:
| Tabel 5.41 Commodore 64 enhedsnumre og deres enheder |
|
|---|---|
| Nummer | Enhed |
| 0 | Tastatur |
| 1 | Bånddrev |
| 2 | RS 232C interface til f.eks. et modem |
| 3 | Skærm |
| 4 | Printer #1 |
| 5 | Printer #2 |
| 6 | Plotter #1 |
| 7 | Plotter #2 |
| 8 | Diskdrev |
| 9 ¦ ¦ ¦ 30 |
Fra 8 (inklusive) op til 22 flere lagerenheder |
Der er to typer porte til en computer. Én type er ekstern, på den lodrette overflade af systemenheden. Den anden type er intern. Denne interne port er et register. Commodore-64 har fire interne porte: Port A og port B til CIA 1 og port A og Port B til CIA 2. Der er én ekstern port til Commodore-64, som kaldes den serielle port. Enhederne med nummer 3 opad er forbundet til den serielle port. De er forbundet i en serie af kæder (en, der er forbundet bag den anden), som hver kan identificeres ved deres enhedsnummer. Enhederne med tallet 8 opad er generelt lagerenhederne.
Bemærk : Standardinputenheden er tastaturet med enhedsnummeret 0. Standardoutputenheden er skærmen med enhedsnummeret 3.
Logisk filnummer
Et logisk filnummer er et nummer givet for en enhed (perifer enheder) i den rækkefølge, de åbnes for adgang. De spænder fra 010 til 255 10 .
Sekundær adresse
Forestil dig, at to filer (eller mere end én fil) er åbnet på disken. For at skelne mellem disse to filer bruges de sekundære adresser. Sekundære adresser er tal, der varierer fra enhed til enhed. Betydningen af 3 som en sekundær adresse for en printer er forskellig fra betydningen af 3 som en sekundær adresse for et diskdrev. Betydningen afhænger af funktioner som når en fil åbnes til læsning, eller hvornår en fil åbnes til skrivning. De mulige sekundære tal er fra 0 10 til 15 10 for hver enhed. For mange enheder bruges tallet 15 til at sende kommandoer.
Bemærk : Enhedsnummeret er også kendt som enhedsadresse, og det sekundære nummer er også kendt som sekundær adresse.
Identifikation af et perifert mål
For standard Commodore-hukommelseskort bruges hukommelsesadresserne fra $0200 til $02FF (side 2) udelukkende af operativsystemet i ROM (Kernal) og ikke af operativsystemet plus BASIC-sproget. Selvom BASIC stadig kan bruge placeringerne gennem ROM OS.
Modemmet og printeren er to forskellige perifere mål. Hvis to filer åbnes fra disken, er det to forskellige mål. Med standardhukommelseskortet er der tre på hinanden følgende tabeller (lister), som kan ses som én stor tabel. Disse tre tabeller indeholder forholdet mellem logiske filnumre, enhedsnumre og sekundære adresser. Dermed bliver en specifik kanal eller input/output-mål identificerbar. De tre tabeller kaldes File Tables. RAM-adresserne og hvad de har er:
$0259 - $0262: Tabel med etiket, LAT, med op til ti aktive logiske filnumre.
$0263 — $026C: Tabel med etiket, FAT, med op til ti tilsvarende enhedsnumre.
$026D — $0276: Tabel med etiket, SAT, med ti tilsvarende sekundære adresser.
Her betyder '—' 'til', og et tal tager en byte.
Læseren kan spørge: 'Hvorfor er bufferen for hver enhed ikke inkluderet i identifikation af en kanal?' Nå, svaret er, at med commodore-64 har hver ekstern enhed (perifer enhed) en fast række af bytes i RAM (hukommelseskort). Uden nogen åben kanal er deres positioner der stadig i hukommelsen. Bufferen for tastaturet er for eksempel fastsat fra $0277 til $0280 (inklusive) for standardhukommelseskort.
Kernal SETLFS- og SETNAM-underrutinerne
SETLFS og SETNAM er Kernal-rutiner. En kanal kan ses som en logisk fil. For at en kanal skal åbnes, skal det logiske filnummer, enhedsnummer og en valgfri sekundær adresse fremvises. Et valgfrit filnavn (tekst) kan også være nødvendigt. SETLFS-rutinen opsætter det logiske filnummer, enhedsnummer og en valgfri sekundær adresse. Disse tal er sat i deres respektive tabeller. SETNAM-rutinen opsætter et strengnavn for filen, som kan være obligatorisk for én kanal og valgfrit for en anden kanal. Denne består af en pointer (to-byte adresse) i hukommelsen. Markøren peger på begyndelsen af strengen (navnet), som kan være et andet sted i hukommelsen. Strengnavnet begynder med en byte, der har længden af strengen, efterfulgt af teksten (navn). Navnet er maksimalt seksten bytes (langt).
For at kalde SETLFS-rutinen skal brugerprogrammet hoppe (JSR) til $FFBA-adressen for springtabellen for OS i ROM for standardhukommelseskort. Husk, at med undtagelse af de sidste seks bytes i springtabellen, består hver post af tre bytes. Den første byte er JSR-instruktionen, som derefter hopper til subrutinen, begynder på adressen i de næste to bytes. For at kalde SETNAM-rutinen skal brugerprogrammet hoppe (JSR) til $FFBD-adressen på springtabellen for OS i ROM. Brugen af disse to rutiner er vist i den følgende diskussion.
5.5 Åbning af en kanal, åbning af en logisk fil, lukning af en logisk fil og lukning af alle I/O-kanaler
En kanal består af en hukommelsesbuffer, et logisk filnummer, enhedsnummer (enhedsadresse) og en valgfri sekundær adresse (et nummer). En logisk fil (en abstraktion), som er identificeret ved et logisk filnummer, kan referere til en perifer enhed, såsom en printer, et modem, et diskdrev osv. Hver af disse forskellige enheder bør have forskellige logiske filnumre. Der er mange filer på disken. En logisk fil kan også referere til en bestemt fil på disken. Den pågældende fil har også et logisk filnummer, som er forskelligt fra de eksterne enheder, såsom printeren eller modemet. Det logiske filnummer gives af programmøren. Det kan være et hvilket som helst tal fra 010 ($00) til 25510 ($FF).
OS SETLFS-rutinen
OS SETLFS-rutinen, som tilgås ved at hoppe (JSR) til OS ROM-springtabellen ved $FFBA, opsætter kanalen. Den skal indsætte det logiske filnummer i filtabellen, som er LAT ($0259 - $0262). Den skal indsætte det tilsvarende enhedsnummer i filtabellen, som er FAT ($0263 - $026C). Hvis filen (enheden) har brug for et sekundært nummer, skal den indsætte den tilsvarende sekundære adresse (nummer) i filtabellen, som er SAT ($026D — $0276).
For at kunne fungere skal SETLFS-underrutinen hente det logiske filnummer fra µP-akkumulatoren; den skal hente enhedsnummeret fra µP X-registret. Hvis det er nødvendigt af kanalen, skal den hente den sekundære adresse fra µP Y-registret.
Det logiske filnummer bestemmes af programmøren. De logiske filnumre, der henviser til forskellige enheder, er forskellige. Nu, før du kalder SETLFS-rutinen, skal programmøren indsætte nummeret for den logiske fil i µP-akkumulatoren. Enhedsnummeret læses fra en tabel (dokument) som i tabel 5.41. Programmeringsenheden skal også indsætte enhedsnummeret i µP X-registret. Leverandøren af en enhed såsom en printer, et diskdrev osv. giver de mulige sekundære adresser og deres betydning for enheden. Hvis kanalen har brug for en sekundær adresse, skal programmøren hente den fra det dokument, der leveres med enheden (perifert). Hvis den sekundære adresse (nummer) er nødvendig, skal programmøren placere den i µP Y-registret, før den kalder SETLFS-underrutinen. Hvis der ikke er behov for en sekundær adresse, skal programmøren indsætte $FF-nummeret i µP Y-registret, før han kalder SETLFS-subrutinen.
SETLFS-underrutinen kaldes uden argumenter. Dens argumenter er allerede i de tre registre af 6502 µP. Efter at have lagt de relevante numre ind i registrene, kaldes rutinen i programmet blot med følgende i en separat linje:
JSR SETLFS
Rutinen sætter de forskellige numre passende ind i deres filtabeller.
OS SETNAM-rutinen
OS SETNAM-rutinen tilgås ved at hoppe (JSR) til OS ROM-springtabellen ved $FFBD. Ikke alle destinationer har filnavne. For dem, der har destinationer (som filerne på disken), skal filnavnet konfigureres. Antag at filnavnet er 'mydocum', som består af 7 bytes uden anførselstegn. Antag, at dette navn er på $C101 til $C107-lokationerne (inklusive), og at længden af $07 er på $C100-lokationen. Startadressen for strengtegnene er $C101. Den nederste byte af startadressen er $01, og den højere byte er $C1.
Før du kalder SETNAM-rutinen, skal programmøren indsætte $07-nummeret (strengens længde) i µP-akkumulatoren. Den nederste byte af strengens startadresse på $01 sættes i µP X-registret. Den højere byte af strengens startadresse på $C1 sættes i µP Y registeret. Subrutinen kaldes simpelthen med følgende:
JSR SETNAM
SETNAM-rutinen forbinder værdierne fra de tre registre med kanalen. Værdierne behøver ikke forblive i registrene derefter. Hvis kanalen ikke har brug for et filnavn, skal programmøren lægge $00 i µP-akkumulatoren. I dette tilfælde ignoreres de værdier, der er i X- og Y-registrene.
OS OPEN-rutinen
OS OPEN-rutinen tilgås ved at hoppe (JSR) til OS ROM-springtabellen ved $FFC0. Denne rutine bruger det logiske filnummer, enhedsnummeret (og bufferen), en mulig sekundær adresse og et muligt filnavn til at tilvejebringe en forbindelse mellem commodore-computeren og filen i den eksterne enhed eller selve den eksterne enhed.
Denne rutine, ligesom alle andre Commodore OS ROM-rutiner, tager ingen argumenter. Selvom den bruger µP-registrene, skulle ingen af registrene være forudindlæst med argumenter (værdier) for det. For at kode det skal du bare skrive følgende efter SETLFS og SETNAM kaldes:
JSR ÅBEN
Der kan opstå fejl med OPEN-rutinen. Filen kan f.eks. ikke findes til læsning. Når der opstår en fejl, fejler rutinen og indsætter det tilsvarende fejlnummer i µP-akkumulatoren og sætter bæreflaget (til 1) for µP-statusregisteret. Følgende tabel viser fejlnumrene og deres betydning:
| Tabel 5.51 Kernal fejlnumre og deres betydning for OS ROM OPEN Rutine |
||
|---|---|---|
| Fejlnummer | Beskrivelse | Eksempel |
| 1 | FOR MANGE FILER | ÅBN, når ti filer allerede er åbne |
| 2 | FIL ÅBEN | ÅBEN 1,3: ÅBEN 1,4 |
| 3 | FIL IKKE ÅBEN | PRINT#5 uden OPEN |
| 4 | FIL IKKE FUNDET | LOAD “NONEXISTENF”,8 |
| 5 | ENHEDEN IKKE TILSTEDE | ÅBEN 11,11: UDSKRIV#11 |
| 6 | IKKE INDFØR FIL | ÅBN 'SEQ,S,W': GET#8,X$ |
| 7 | IKKE OUTPUT-FIL | ÅBEN 1,0: UDSKRIV #1 |
| 8 | MANGLER FILNAVN | LOAD “”,8 |
| 9 | ULOVLIG ENHED NR. | INDLÆS “PROGRAM”,3 |
Denne tabel er præsenteret på en måde, som læseren sandsynligvis vil se mange andre steder.
OS CHKIN-rutinen
OS CHKIN-rutinen tilgås ved at hoppe (JSR) til OS ROM-springtabellen ved $FFC6. Efter åbning af en fil (logisk fil), skal det besluttes, om åbningen er til input eller output. CHKIN-rutinen gør åbningen til en inputkanal. Denne rutine skal læse det logiske filnummer fra µP X-registret. Så programmøren skal indsætte det logiske filnummer i X-registret, før han kalder denne rutine. Det kaldes ganske enkelt som:
JSR CHKIN
OS CHKOUT-rutinen
OS CHKOUT-rutinen tilgås ved at hoppe (JSR) til OS ROM-springtabellen ved $FFC9. Efter åbning af en fil (logisk fil), skal det besluttes, om åbningen er til input eller output. CHKOUT-rutinen gør åbningen til en udgangskanal. Denne rutine skal læse det logiske filnummer fra µP X-registret. Så programmøren skal indsætte det logiske filnummer i X-registret, før han kalder denne rutine. Det kaldes ganske enkelt som:
JSR CHKOUT
OS LUK-rutinen
OS CLOSE-rutinen tilgås ved at hoppe (JSR) til OS ROM-springtabellen ved $FFC3. Efter at en logisk fil er åbnet, og bytes er overført, skal den logiske fil lukkes. Lukning af den logiske fil frigør bufferen i systemetheden til at blive brugt af en anden logisk fil, som stadig skal åbnes. De tilsvarende parametre i de tre filtabeller slettes også. RAM-placeringen for antallet af åbne filer nedsættes med 1.
Når strømmen er tændt for computeren, nulstilles der hardware til mikroprocessoren og andre hovedchips (integrerede kredsløb) på bundkortet. Dette efterfølges af initialisering af nogle RAM-hukommelsesplaceringer og nogle registre i nogle chips på bundkortet. I initialiseringsprocessen er bytehukommelsesplaceringen for $0098-adressen på side nul angivet med NFILES- eller LDTND-etiketten, afhængigt af versionen af operativsystemet. Mens computeren kører, indeholder denne én-byte placering på 8 bit antallet af logiske filer, der åbnes, og startadresseindekset for de tre på hinanden følgende filtabeller. Med andre ord har denne byte antallet af åbne filer, som nedsættes med 1, når den logiske fil lukkes. Når den logiske fil er lukket, er adgangen til terminalenheden (destinationsenheden) eller den faktiske fil på disken ikke længere mulig.
For at lukke en logisk fil skal programmøren indsætte det logiske filnummer i µP-akkumulatoren. Dette er det samme logiske filnummer, som bruges til at åbne filen. CLOSE-rutinen har brug for det for at lukke den pågældende fil. Ligesom andre OS ROM-rutiner tager CLOSE-rutinen ikke et argument, selvom den værdi, der bruges fra akkumulatoren, i nogen grad er et argument. Instruktionslinjen for samlesprog er ganske enkelt:
JSR LUK
De brugerdefinerede eller foruddefinerede 6502 assemblersprog subrutiner (rutiner) tager ikke argumenter. Argumenterne kommer dog uformelt ved at sætte de værdier, som subrutinen vil bruge, i mikroprocessorregistrene.
CLRCHN-rutinen
OS CLRCHN-rutinen tilgås ved at hoppe (JSR) til OS ROM-springtabellen ved $FFCC. CLRCHN står for CLeaR CHanneL. Når en logisk fil lukkes, slettes dens parametre for logisk filnummer, enhedsnummer og mulig sekundær adresse. Så kanalen for den logiske fil er ryddet.
Manualen siger, at OS CLRCHN-rutinen rydder alle de åbne kanaler og gendanner standardenhedsnumrene og andre standardindstillinger. Betyder det, at enhedsnummeret for en perifer enhed kan ændres? Nå, ikke helt. Under initialiseringen af operativsystemet angives byteplaceringen af $0099-adressen med DFLTI-etiketten for at holde det aktuelle inputenhedsnummer, når computeren er i drift. Commodore-64 kan kun få adgang til én perifer enhed ad gangen. Under initialiseringen af operativsystemet angives byteplaceringen af $009A-adressen med DFLTO-etiketten for at holde det aktuelle outputenhedsnummer, når computeren er i drift.
Når CLRCHN-underrutinen kaldes, sætter den DFLTI-variablen til 0 ($00), som er standardinput-enhedsnummeret (tastatur). Den indstiller DFLTO-variablen til 3 ($03), som er standardudgangsenhedens nummer (skærm). Andre enhedsnummervariabler nulstilles på samme måde. Det er meningen med at nulstille (eller gendanne) input/output-enhederne til normal (standardværdier).
Commodore-64-manualen siger, at efter CLRCHN-rutinen er kaldt, forbliver de åbnede logiske filer åbne og kan stadig overføre bytes (data). Dette betyder, at CLRCHN-rutinen ikke sletter de tilsvarende poster i filtabellerne. CLRCHN-navnet er ret tvetydigt for dets betydning.
5.6 Sende karakteren til skærmen
Det integrerede hovedkredsløb (IC) til at håndtere visningen af tegn og grafik på skærmen kaldes Video Interface Controller (chip), som er forkortet som VIC i Commodore-64 (faktisk VIC II til VIC version 2). For at en information (værdier) skal gå til skærmen, skal den passere gennem VIC II, før den når skærmen.
Skærmen består af 25 rækker og 40 kolonner med karakterceller. Dette giver 40 x 25 = 1000 tegn, der kan vises på skærmen. VIC II læser de tilsvarende 1000 hukommelses-RAM konsekutive byteplaceringer for tegn. Disse 1000 steder tilsammen er kendt som skærmhukommelse. Det, der går ind på disse 1000 steder, er tegnkoderne. For Commodore-64 er tegnkoderne forskellige fra ASCII-koderne.
En tegnkode er ikke et tegnmønster. Der er også det, der er kendt som karakter-ROM. Tegn-ROM'en består af alle mulige tegnmønstre, hvoraf nogle svarer til tegnmønstrene på tastaturet. Tegn-ROM'en er forskellig fra skærmens hukommelse. Når et tegn skal vises på skærmen, sendes tegnkoden til en position blandt de 1000 positioner i skærmhukommelsen. Derfra vælges det tilsvarende mønster fra den tegn-ROM, der skal vises på skærmen. Valg af det korrekte mønster i tegn-ROM'en fra en tegnkode udføres af VIC II (hardware).
Mange hukommelsesplaceringer mellem $D000 og $DFFF har to formål: de bruges til at håndtere andre input/output-operationer end skærmen eller bruges som tegn-ROM for skærmen. Der er tale om to hukommelsesblokke. Den ene er RAM og den anden er ROM for tegn ROM. Udskiftningen af bankerne til at håndtere enten input/output eller tegnmønstrene (karakter-ROM) udføres af software (rutine af OS i ROM fra $F000 til $FFFF).
Bemærk : VIC'en har registre, der er adresseret med adresser på hukommelsespladsen inden for området $D000 og $DFFF.
CHROUT-rutinen
OS CHROUT-rutinen tilgås ved at hoppe (JSR) til OS ROM-springtabellen ved $FFD2. Denne rutine, når den kaldes, tager den byte, som programmøren har lagt i µP-akkumulatoren, og udskriver på skærmen, hvor markøren er. Kodesegmentet til at udskrive 'E'-tegnet er for eksempel:
LDA #$05
KRØDE
0516 er ikke ASCII-koden for 'E'. Commodore-64 har sine egne tegnkoder til skærmen, hvor $05 betyder 'E'. #$05-nummeret placeres i skærmens hukommelse, før VIC sender det til skærmen. Disse to kodningslinjer skulle komme efter, at kanalen er sat op, den logiske fil er åbnet, og CHKOUT-rutinen kaldes for output. Den komplette kode er:
; Indstil kanal
LDA #$40 ; logisk filnummer
LDX #$03 ; enhedsnummer for skærmen er $03
LDY #$FF ; ingen sekundær adresse
JSR SETLFS ; opsætte kanal korrekt
; ingen SETNAM, da skærmen ikke behøver et navn
;
; Åbn logisk fil
JSR ÅBEN
; Indstil kanal for output
LDX #$40 ; logisk filnummer
JSR CHKOUT
;
; Output char til skærmen
LDA #$05
JSR CHROUT
; Luk logisk fil
LDA #$40
JSR LUK
Åbningen skal lukkes, før et andet program køres. Antag, at computerbrugeren skriver et tegn på tastaturet, når det forventes. Følgende program udskriver et tegn fra tastaturet til skærmen:
; Indstil kanal
LDA #$40 ; logisk filnummer
LDX #$03 ; enhedsnummer for skærmen er $03
LDY #$FF ; ingen sekundær adresse
JSR SETLFS ; opsætte kanal korrekt
; ingen SETNAM, da skærmen ikke behøver et navn
;
; Åbn logisk fil
JSR ÅBEN
; Indstil kanal for output
LDX #$40 ; logisk filnummer
JSR CHKOUT
;
; Indtast tegn fra tastaturet
WAIT JSR GETIN ; sætter $00 i A, hvis tastaturkøen er tom
CMP #$00 ; Hvis $00 gik til A, så er Z 1 med sammenligningen
BEQ WAIT ; GETIN fra køen igen, hvis 0 gik til akkumulator
BNE PRNSCRN ; gå til PRNSCRN hvis Z er 0, fordi A ikke længere har $00
; Output char til skærmen
PRNSCRN JSR CHROUT ; send char i A til skærmen
; Luk logisk fil
LDA #$40
JSR LUK
Bemærk : WAIT og PRNSCRN er etiketterne, der identificerer adresserne. Byten fra tastaturet, der ankommer til µP-akkumulatoren, er en ASCII-kode. Den tilsvarende kode, der skal sendes til skærmen af Commodore-64, skal være anderledes. Det er der for forenklingens skyld ikke taget højde for i det tidligere program.
5.7 Afsendelse og modtagelse af bytes til diskdrev
Der er to komplekse interface-adaptere i systemenheden (bundkortet) på Commodore-64 kaldet VIA #1 og CIA #2. Hver CIA har to parallelle porte, der kaldes Port A og Port B. Der er en ekstern port på den lodrette overflade bag på Commodre-64-systemet, som kaldes den serielle port. Denne port har 6 ben, hvoraf den ene er til data. Dataene kommer ind i eller forlader systemenheden i serie, en bit ad gangen.
Otte parallelle bits fra den interne port A i CIA #2 kan for eksempel gå ud af systemetheden gennem den eksterne serielle port efter at være blevet konverteret til de serielle data af et skifteregister i CIA. Otte-bit serielle data fra den eksterne serielle port kan gå ind i den interne port A i CIA #2 efter at være blevet konverteret til paralleldata af et skifteregister i CIA.
Commodore-64 systemenheden (basisenheden) bruger et eksternt diskdrev med en diskette. En printer kan sluttes til dette diskdrev i seriekæde (forbinder enheder i serie som en streng). Datakablet til diskdrevet er tilsluttet den eksterne serielle port på Commodore-64-systemet. Det betyder, at en serieforbundet printer også er tilsluttet den samme serielle port. Disse to enheder identificeres af to forskellige enhedsnumre (typisk henholdsvis 8 og 4).
Afsendelse eller modtagelse af data til diskdrevet følger samme procedure som tidligere beskrevet. Det er:
- Indstilling af navnet på den logiske fil (nummer), som er det samme som navnet på den faktiske diskfil ved hjælp af SETNAM-rutinen.
- Åbning af den logiske fil ved hjælp af OPEN-rutinen.
- Beslutning om det er input eller output ved hjælp af CHKOUT eller CHKIN rutinen.
- Afsendelse eller modtagelse af data ved hjælp af STA- og/eller LDA-instruktionen.
- Lukning af den logiske fil ved hjælp af CLOSE-rutinen.
Den logiske fil skal lukkes. Lukning af den logiske fil lukker effektivt den pågældende kanal. Når du opsætter kanalen for diskdrevet, bestemmes det logiske filnummer af programmøren. Det er et tal mellem $00 og $FF (inklusive). Det bør ikke være et nummer, der allerede er valgt for en anden enhed (eller faktisk fil). Enhedsnummeret er 8, hvis der kun er ét diskdrev. Den sekundære adresse (nummer) er hentet fra manualen til diskdrevet. Følgende program bruger 2. Programmet skriver bogstavet 'E' (ASCII) til en fil på disken kaldet 'mydoc.doc'. Dette navn antages at starte ved hukommelsesadressen $C101. Så den lavere byte på $01 skal være i X-registret, og den højere byte af $C1 skal være i Y-registret, før SETNAM-rutinen kaldes. A-registret bør også have $09-nummeret, før SETNAM-rutinen kaldes.
; Indstil kanal
LDA #$40 ; logisk filnummer
LDX #$08 ; enhedsnummer for første diskdrev
LDY #$02 ; sekundær adresse
JSR SETLFS ; opsætte kanal korrekt
;
; Fil på diskdrev skal have et navn (allerede i hukommelsen)
LDA #$09
LDX #$01
LDY#$C1
JSR SETNAM
; Åbn logisk fil
JSR ÅBEN
; Indstil kanal for output
LDX #$40 ; logisk filnummer
JSR CHKOUT ;til skrivning
;
; Output tegn til disk
LDA #$45
JSR CHROUT
; Luk logisk fil
LDA #$40
JSR LUK
For at læse en byte fra disken ind i µP Y-registret skal du gentage det foregående program med følgende ændringer: I stedet for 'JSR CHKOUT ; til skrivning', brug 'JSR CHKIN ; til læsning”. Erstat kodesegmentet for '; Output char til disk' med følgende:
; Indtast tegn fra disk
JSR CHRIS
OS CHRIN-rutinen tilgås ved at hoppe (JSR) til OS ROM-springtabellen ved $FFCF. Denne rutine, når den kaldes, får en byte fra en kanal, der allerede er sat op som en inputkanal og sætter den ind i µPA-registret. GETIN ROM OS-rutinen kan også bruges i stedet for CHRIN.
Sende en byte til printeren
At sende en byte til printeren foregår på samme måde som at sende en byte til en fil på disken.
5.8 OS SAVE-rutinen
OS SAVE-rutinen tilgås ved at hoppe (JSR) til OS ROM-springtabellen ved $FFD8. OS SAVE-rutinen i ROM gemmer (dumper) en del af hukommelsen til disken som en fil (med et navn). Startadressen for sektionen i hukommelsen skal kendes. Slutadressen for sektionen skal også kendes. Den nederste byte af startadressen er placeret på siden nul i RAM ved $002B-adressen. Den højere byte af startadressen placeres i den næste byte-hukommelsesplacering ved $002C-adressen. På side nul refererer TXTTAB-etiketten til disse to adresser, selvom TXTTAB faktisk betyder $002B-adressen. Den nederste byte af slutadressen placeres i µP X-registret. Den højere byte af slutadressen plus 1 placeres i µP Y-registret. µP A-registret tager værdien af $2B for TXTTAB ($002B). Med det kan SAVE-rutinen kaldes med følgende:
JSR SPAR
Den del af hukommelsen, der skal gemmes, kan være et assemblersprogsprogram eller et dokument. Et eksempel på et dokument kan være et brev eller et essay. For at bruge gemmerutinen skal følgende procedure følges:
- Indstil kanalen ved hjælp af SETLFS-rutinen.
- Indstil navnet på den logiske fil (nummer), som er det samme som navnet på den faktiske diskfil ved hjælp af SETNAM-rutinen.
- Åbn den logiske fil ved hjælp af OPEN-rutinen.
- Gør det til fil til output ved hjælp af CHKOUT.
- Koden til at gemme filen går her, som ender med 'JSR SAVE'.
- Luk den logiske fil ved hjælp af CLOSE-rutinen.
Følgende program gemmer en fil, der starter fra hukommelsesplaceringerne $C101 til $C200:
; Indstil kanal
LDA #$40 ; logisk filnummer
LDX #$08 ; enhedsnummer for første diskdrev
LDY #$02 ; sekundær adresse
JSR SETLFS ; opsætte kanal korrekt
;
; Navn på fil i diskdrev (allerede i hukommelsen på $C301)
LDA #$09 ; længden af filnavnet
LDX #$01
LDY #$C3
JSR SETNAM
; Åbn logisk fil
JSR ÅBEN
; Indstil kanal for output
LDX #$40 ; logisk filnummer
JSR CHKOUT ; til at skrive
;
; Output fil til disk
LDA #$01
STA $2B ; TXTTAB
LDA #$C1
STA $2C
LDX #$00
LDY#$C2
LDA #$2B
JSR SPAR
; Luk logisk fil
LDA #$40
JSR LUK
Bemærk, at dette er et program, der gemmer en anden del af hukommelsen (ikke programsektionen) på disken (diskette til Commodore-64).
5.9 OS LOAD-rutinen
OS LOAD-rutinen tilgås ved at hoppe (JSR) til OS ROM-springtabellen ved $FFD5. Når en sektion (stort område) af hukommelsen gemmes på disken, gemmes den med en header, der har startadressen for sektionen i hukommelsen. OS LOAD-underrutinen indlæser bytes af en fil i hukommelsen. Med denne LOAD operation skal værdien af akkumulatoren være 010 ($00). For at LOAD-operationen kan læse startadressen i filoverskriften på disken og lægge filbytes i RAM begyndende fra den adresse, skal den sekundære adresse for kanalen være 1 eller 2 (følgende program bruger 2). Denne rutine returnerer adressen plus 1 for den højeste RAM-placering, der er indlæst. Dette betyder, at den lave byte af filens sidste adresse i RAM plus 1 sættes i µP X-registret, og den høje byte af filens sidste adresse i RAM plus 1 sættes i µP Y-registeret.
Hvis indlæsningen ikke lykkes, indeholder µP A-registret fejlnummeret (muligvis 4, 5, 8 eller 9). C-flaget for mikroprocessorstatusregisteret er også indstillet (lavet 1). Hvis indlæsningen lykkes, er den sidste værdi af A-registret ikke vigtig.
Nu, i det forrige kapitel af dette online karrierekursus, er den første instruktion i assemblersprogprogrammet på adressen i RAM, hvor programmet startede. Det behøver ikke være sådan. Det betyder, at den første instruktion af et program ikke behøver at være i begyndelsen af programmet i RAM. Startinstruktionen for et program kan være hvor som helst i filen i RAM. Programmøren rådes til at mærke den startende assembly-sprog-instruktion med START. Med det, efter at programmet er indlæst, kører det igen (udført) med følgende assemblersprogsinstruktion:
JSR START
'JSR START' er i det assemblersprogsprogram, der indlæser det program, der skal køres. Et assemblersprog, der indlæser en anden assemblersprogfil og kører den indlæste fil, har følgende kodeprocedure:
- Indstil kanalen ved hjælp af SETLFS-rutinen.
- Indstil navnet på den logiske fil (nummer), som er det samme som navnet på den faktiske diskfil ved hjælp af SETNAM-rutinen.
- Åbn den logiske fil ved hjælp af OPEN-rutinen.
- Gør det til filen til input ved hjælp af CHKIN.
- Koden til indlæsning af filen går her og slutter med 'JSR LOAD'.
- Luk den logiske fil ved hjælp af CLOSE-rutinen.
Følgende program indlæser en fil fra disken og kører den:
; Indstil kanal
LDA #$40 ; logisk filnummer
LDX #$08 ; enhedsnummer for første diskdrev
LDY #$02 ; sekundær adresse
JSR SETLFS ; opsætning af kanal korrekt
;
; Navn på fil i diskdrev (allerede i hukommelsen på $C301)
LDA #$09 ; længden af filnavnet
LDX #$01
LDY #$C3
JSR SETNAM
; Åbn logisk fil
JSR ÅBEN
; Indstil kanal for input
LDX #$40 ; logisk filnummer
JSR CHKIN ; til læsning
;
; Input fil fra disk
LDA #$00
JSR LOAD
; Luk logisk fil
LDA #$40
JSR LUK
; Start indlæst program
JSR START
5.10 Modemet og RS-232-standarden
Modemmet er en enhed (perifert), der konverterer bits fra computeren til de tilsvarende elektriske lydsignaler, der skal transmitteres over telefonlinjen. I den modtagende ende er der et modem før en modtagende computer. Dette andet modem konverterer de elektriske lydsignaler til bits for den modtagende computer.
Et modem skal tilsluttes en computer ved en ekstern port (ved computerens lodrette overflade). RS-232-standarden refererer til en bestemt type stik, som forbinder et modem til computeren (tidligere). Med andre ord havde mange computere tidligere en ekstern port, der var et RS-232-stik eller et RS-232-kompatibelt stik.
Commodore-64 System Unit (computer) har en ekstern port på dens bagerste lodrette overflade, som kaldes brugerporten. Denne brugerport er RS-232-kompatibel. Der kan tilsluttes et modem. Commodore-64 kommunikerer med et modem gennem denne brugerport. ROM-operativsystemet til Commodore-64 har underrutiner til at kommunikere med et modem kaldet RS-232-rutiner. Disse rutiner har poster i springtabellen.
Baud rate
Den otte-bit byte fra computeren konverteres til en serie på otte bit, før den sendes til modemmet. Det omvendte sker fra modemmet til computeren. Baudrate er antallet af bits, der transmitteres pr. sekund, i serie.
Bunden af Hukommelsen
Udtrykket 'Bund af hukommelsen' refererer ikke til hukommelsesbyte-placeringen af $0000-adressen. Det refererer til den laveste RAM-placering, hvor brugeren kan begynde at lægge sine data og programmer. Som standard er det $0800. Husk fra den tidligere diskussion, at mange af placeringerne mellem $0800 og $BFFF bruges af BASIC computersproget og dets programmører (brugere). Kun $C000 til $CFFF adresseplaceringerne er tilbage til brug for assemblersprogprogrammerne og data; dette er 4Kbytes ud af de 64 Kbytes i hukommelsen.
Top of Memory
I de dage, da kunderne købte Commodore-64-computere, kom nogle ikke med alle hukommelsesplaceringerne. Sådanne computere havde ROM med sit operativsystem fra $E000 til $FFFF. De havde RAM fra $0000 til en grænse, som ikke er $DFFF, ved siden af $E000. Grænsen var under $DFFF, og den grænse kaldes 'Top of Memory'. Så top-of-memory refererer ikke til $FFFF-placeringen.
Commodore-64 buffere til RS-232 kommunikation
Sender buffer
Bufferen til RS-232 transmission (output) tager 256 bytes fra toppen af hukommelsen og nedad. Markøren for denne sendebuffer er mærket som ROBUF. Denne pointer er på side nul med $00F9-adresserne efterfulgt af $00FA. ROBUF identificerer faktisk $00F9. Så hvis adressen for starten af bufferen er $BE00, er den nederste byte af $BE00, som er $00, på $00F9-placeringen, og den højere byte af $BE00, som er $BE, er i $00FA Beliggenhed.
Modtager buffer
Bufferen til at modtage RS-232 bytes (input) tager 256 bytes fra bunden af sendebufferen. Markøren for denne modtagebuffer er mærket som RIBUF. Denne markør er på side nul med $00F7-adresserne efterfulgt af $00F8. RIBUF identificerer faktisk $00F7. Så hvis adressen for starten af bufferen er $BF00, er den nederste byte af $BF00, som er $00, på $00F7-placeringen, og den højere byte af $BF00, som er $BF, er i $00F8 Beliggenhed. Så 512 bytes fra toppen af hukommelsen bruges som den samlede RS-232 RAM-buffer.
RS-232 kanal
Når et modem er tilsluttet den (eksterne) brugerport, er kommunikationen til modemmet kun RS-232 kommunikation. Proceduren for at have en komplet RS-232-kanal er næsten den samme som i den foregående diskussion, men med en vigtig forskel: filnavnet er en kode og ikke en streng i hukommelsen. Koden $0610 er et godt valg. Det betyder en baudrate på 300 bit/sek og nogle andre tekniske parametre. Desuden er der ingen sekundær adresse. Bemærk, at enhedsnummeret er 2. Proceduren for at opsætte en komplet RS-232-kanal er:
- Indstilling af kanalen ved hjælp af SETLFS rutine.
- Indstilling af navnet på den logiske fil, $0610.
- Åbning af den logiske fil ved hjælp af OPEN-rutinen.
- Gør det til filen til output ved hjælp af CHKOUT eller fil til input ved hjælp af CHKIN.
- Sender de enkelte bytes med CHROUT eller modtager de enkelte bytes med GETIN.
- Lukning af den logiske fil ved hjælp af CLOSE-rutinen.
OS GETIN-rutinen tilgås ved at hoppe (JSR) til OS ROM-springtabellen ved $FFE4. Denne rutine, når den kaldes, tager den byte, der sendes ind i modtagerbufferen, og sætter (returnerer) den ind i µP-akkumulatoren.
Følgende program sender byten 'E' (ASCII) til modemmet, som er tilsluttet den bruger RS-232-kompatible port:
; Indstil kanal
LDA #$40 ; logisk filnummer
LDX #$02 ; enhedsnummer for RS-232
LDY #$FF ; ingen sekundær adresse
JSR SETLFS ; opsætte kanal korrekt
;
; Navn for RS-232 er en kode f.eks. $0610
LDA #$02 ; kodens længde er 2 bytes
LDX #$10
LDY #$06
JSR SETNAM
;
; Åbn logisk fil
JSR ÅBEN
; Indstil kanal for output
LDX #$40 ; logisk filnummer
JSR CHKOUT
;
; Output char til RS-232 f.eks. modem
LDA #$45
JSR CHROUT
; Luk logisk fil
LDA #$40
JSR LUK
For at modtage en byte er koden meget ens, bortset fra at 'JSR CHKOUT' er erstattet af 'JSR CHKIN' og:
LDA #$45
JSR CHROUT
erstattes af 'JSR GETIN', hvor resultatet placeres i A-registret.
Kontinuerlig afsendelse eller modtagelse af bytes udføres af en løkke til henholdsvis afsendelse eller modtagelse af kodesegment.
Bemærk, at input og output med Commodore er ens for de fleste af dens tilfælde bortset fra tastaturet, hvor nogle af rutinerne ikke kaldes af programmøren, men de kaldes af operativsystemet.
5.11 Tælling og timing
Overvej nedtællingssekvensen, som er:
2, 1, 0
Dette tæller ned fra 2 til 0. Overvej nu den gentagne nedtællingssekvens:
2, 1, 0, 2, 1, 0, 2, 1, 0, 2, 1, 0
Dette er den gentagne nedtælling af den samme sekvens. Sekvensen gentages fire gange. Fire gange betyder, at timingen er 4. Inden for én sekvens tæller. At gentage den samme sekvens er timing.
Der er to komplekse interface-adaptere i systemenheden på Commodore-64. Hver CIA har to tæller-/timerkredsløb kaldet Timer A (TA) og Timer B (TB). Tællekredsløbet er ikke forskelligt fra tidskredsløbet. Tælleren eller timeren i Commodore-64 refererer til det samme. Faktisk refererer begge i det væsentlige til et 16-bit register, som altid tæller ned til 0 ved systemets urimpulser. Forskellige værdier kan indstilles i 16-bit registeret. Jo større værdi, jo længere tid tager det at tælle ned til nul. Hver gang en af timerne går forbi nul, vil IRQ afbrydelsessignal sendes til mikroprocessoren. Når optællingen går ned over nul, kaldes det underløb.
Afhængigt af hvordan timerkredsløbet er programmeret, kan en timer køre i engangstilstand eller i kontinuerlig tilstand. Med den foregående illustration betyder engangstilstand 'gør 2, 1, 0' og stop, mens urimpulserne fortsætter. Kontinuerlig tilstand er som '2, 1, 0, 2, 1, 0, 2, 1, 0, 2, 1, 0 osv.' som fortsætter med urets pulser. Det betyder, at når den går forbi nul, hvis der ikke gives nogen instruktion, gentages nedtællingssekvensen. Det største tal er normalt meget større end 2.
Timer A (TA) af CIA #1 genererer IRQ med jævne mellemrum (varigheder) for at servicere tastaturet. Faktisk er dette faktisk hver 1/60 af et sekund som standard. IRQ sendes til mikroprocessoren hvert 1/60 sekund. Det er kun hvornår IRQ sendes, at et program kan læse en nøgleværdi fra tastaturkøen (buffer). Husk at mikroprocessoren kun har én pin til IRQ signal. Mikroprocessoren har også kun én pin til NMI signal. ¯NMI-signalet til mikroprocessoren kommer altid fra CIA #2.
16-bit timerregisteret har to hukommelsesadresser: en for den lavere byte og en for den højere byte. Hver CIA har to timerkredsløb. De to CIA'er er identiske. For CIA #1 er adresserne for de to timere: DC04 og DC05 for TA og DC06 og DC07 for TB. For CIA #2 er adresserne for de to timere: DD04 og DD05 for TA og DD06 og DD07 for TB.
Antag, at nummeret 25510 skal sendes til TA-timeren i CIA #2 for at tælle ned. 25510 = 00000000111111112 er i seksten bit. 00000000111111112 = $000FFF er i hexadecimal. I dette tilfælde sendes $FF til registret på $DD04-adressen, og $00 sendes til registret på $DD05-adressen – little endianness. Følgende kodesegment sender nummeret til registret:
LDA #$FF
OPLYS $DD04
LDA #$00
OPLYS $DD05
Selvom registrene i en CIA har RAM-adresser, er de fysisk i CIA, og CIA er en separat IC fra RAM eller ROM.
Det er ikke alt! Når timeren har fået et tal til nedtælling, som med den forrige kode, starter nedtællingen ikke. Nedtællingen starter, når en otte-bit byte er blevet sendt ind i det tilsvarende kontrolregister for timeren. Den første bit af denne byte til kontrolregisteret angiver, om nedtællingen skal starte eller ej. En værdi på 0 for denne første bit betyder at stoppe med at tælle ned, mens en værdi på 1 betyder at begynde at tælle ned. Byten skal også angive, om nedtællingen er i et skud (engangstilstand) eller i friløbstilstand (kontinuerlig tilstand). One-shot-tilstand tæller ned og stopper, når værdien af timerregistret bliver nul. Med friløbstilstanden gentages nedtællingen efter at have nået 0. Den fjerde (indeks 3) bit af byten, der sendes til kontrolregisteret, angiver tilstanden: 0 betyder friløbstilstand og 1 betyder one-shot mode.
Et passende tal til at begynde at tælle i one-shot-tilstand er 000010012 = $09 i hexadecimal. Et passende tal til at begynde at tælle i friløbstilstand er 000000012 = $01 i hexadecimal. Hvert timerregister har sit eget kontrolregister. I CIA #1 har kontrolregisteret for timer A RAM-adressen DC0E16, og kontrolregisteret for timer B har RAM-adressen DC0F16. I CIA #2 har kontrolregisteret for timer A RAM-adressen DD0E16, og kontrolregisteret for timer B har RAM-adressen DD0F16. For at begynde at tælle seksten-bit-tallet ned i TA af CIA #2, i one-shot-tilstand, skal du bruge følgende kode:
LDA #$09
STA $DD0E
For at begynde at tælle seksten-bit-tallet ned i TA af CIA #2, i frit kørende tilstand, skal du bruge følgende kode:
LDA #$01
STA $DD0E
5.12 IRQ og NMI Forespørgsler
6502 mikroprocessoren har IRQ og NMI linjer (stifter). Både CIA #1 og CIA #2 har hver IRQ pin til mikroprocessoren. Det IRQ pin af CIA #2 er forbundet til NMI pin af µP. Det IRQ pin af CIA #1 er forbundet til IRQ pin af µP. Det er de eneste to afbrydelseslinjer, der forbinder mikroprocessoren. Så IRQ pin af CIA #2 er NMI kilde og kan også ses som ¯NMI-linjen.
CIA #1 har fem mulige umiddelbare kilder til at generere IRQ signal for µP. CIA #2 har samme struktur som CIA #1. Så CIA #2 har de samme fem mulige umiddelbare kilder til at generere afbrydelsessignalet denne gang, hvilket er NMI signal. Husk, at når µP modtager NMI signal, hvis den håndterer IRQ anmodning, suspenderer den det og håndterer NMI anmodning. Når den er færdig med at håndtere NMI anmodning, genoptager den derefter håndteringen af IRQ anmodning.
CIA #1 er normalt tilsluttet eksternt til tastaturet og en spilenhed såsom et joystick. Tastaturet bruger mere af port A på CIA #1 end port B. Spilleenheden bruger mere af CIA #1 port B end port A. CIA #2 er normalt tilsluttet eksternt til diskdrevet (daisy chained til printeren) og modemmet. Diskdrevet bruger mere af port A på CIA #2 (dog gennem den eksterne serielle port) end port B. Modemmet (RS-232) bruger mere af CIA #2 port B end port A.
Med alt det, hvordan ved systemenheden, hvad der forårsager IRQ eller NMI afbryde? CIA #1 og CIA #2 har fem umiddelbare kilder til afbrydelse. Hvis afbrydelsessignalet til µP er NMI , kilden er en af de umiddelbare fem kilder fra CIA #2. Hvis afbrydelsessignalet til µP er IRQ , kilden er en af de umiddelbare fem kilder fra CIA #1.
Det næste spørgsmål er: 'Hvordan skelner systemenheden mellem de fem umiddelbare kilder til hver CIA?' Hver CIA har et otte-bit register, som kaldes Interrupt Control Register (ICR). ICR betjener begge CIAs havne. Følgende tabel viser betydningen af de otte bits i interrupt-kontrolregisteret, begyndende fra bit 0:
| Tabel 5.13 Afbrydelseskontrolregister |
|
|---|---|
| Bitindeks | Betyder |
| 0 | Indstillet (lavet 1) ved underløb af timer A |
| 1 | Indstillet af underløb af timer B |
| 2 | Indstil når klokkeslætsur er lig med alarm |
| 3 | Indstil når den serielle port er fuld |
| 4 | Indstillet af ekstern enhed |
| 5 | Ikke brugt (lavet 0) |
| 6 | Ikke brugt (lavet 0) |
| 7 | Indstil når nogen af de første fem bit er indstillet |
Som det kan ses af tabellen, er hver af de umiddelbare kilder repræsenteret af en af de første fem bits. Så når afbrydelsessignalet modtages ved µP, skal koden udføres for at læse indholdet af afbrydelseskontrolregisteret for at kende den nøjagtige kilde til afbrydelsen. RAM-adressen for ICR'en for CIA #1 er DC0D16. RAM-adressen for ICR af CIA #2 er DD0D16. For at læse (returnere) indholdet af ICR'en for CIA #1 til µP-akkumulatoren skal du skrive følgende instruktion:
LDA$DC0D
For at læse (returnere) indholdet af ICR'en for CIA #2 til µP-akkumulatoren skal du skrive følgende instruktion:
LDA $DD0D
5.13 Afbrydelsesdrevet baggrundsprogram
Tastaturet afbryder normalt mikroprocessoren hver 1/60 af et sekund. Forestil dig, at et program kører, og det når en position til at vente på en tast fra tastaturet, før det kan fortsætte med kodesegmenterne nedenfor. Antag, at hvis der ikke trykkes på en tast fra tastaturet, laver programmet kun en lille løkke, og venter på en tast. Forestil dig, at programmet kører og bare forventede en tast fra tastaturet lige efter tastaturafbrydelsen er udstedt. På det tidspunkt stopper hele computeren indirekte og gør ikke andet end at vente looping. Forestil dig, at der trykkes på en tastaturtast lige før næste nummer af den næste tastaturafbrydelse. Det betyder, at computeren intet har gjort i omkring en tresindstyvendedel af et sekund! Det er lang tid for en computer ikke at gøre noget, selv i Commodore-64's dage. Computeren kunne have lavet noget andet i den tid (varighed). Der er mange sådanne varigheder i et program.
Et andet program kan skrives til at fungere ved sådanne 'tomgangstider'. Et sådant program siges at fungere i baggrunden af hovedprogrammet (eller det første). En nem måde at gøre dette på er blot at gennemtvinge en modificeret BRK-afbrydelseshåndtering, når en tast forventes fra tastaturet.
Pointer til BRK Instruktion
På de fortløbende RAM-placeringer af $0316- og $0317-adresserne er markøren (vektor) for den faktiske BRK-instruktionsrutine. Standardmarkøren sættes der, når computeren tændes af operativsystemet i ROM. Denne standardpointer er en adresse, der stadig peger på standard BRK-instruktionsbehandleren i OS ROM'en. Markøren er en 16-bit adresse. Den nederste byte af pointeren er placeret i byte-placeringen af $0306-adressen, og den højere byte af pointeren er placeret i $0317-byte-placeringen.
Et andet program kan skrives sådan, at når systemet er 'tomt', udføres nogle koder i det andet program af systemet. Det betyder, at det andet program skal bestå af underrutiner. Når systemet er 'tomt', der venter på en tast fra tastaturet, udføres en næste underrutine for det andet program. Menneskelig interaktion med computeren er langsom sammenlignet med systemenhedens drift.
Det er nemt at løse dette problem: Hver gang computeren skal vente på en nøgle fra tastaturet, indsæt en BRK-instruktion i koden og udskift markøren på $0316 (og $0317) med markøren for den næste subrutine af den anden ( brugerdefineret) program. På den måde ville begge programmer køre i en varighed, der ikke er meget længere end hovedprogrammet, der kører alene.
5.14 Samling og kompilering
Montøren udskifter alle etiketter med adresser. Et assemblersprogsprogram er normalt skrevet til at starte på en bestemt adresse. Resultatet fra assembleren (efter montering) kaldes 'objektkoden' med alt i binært. Dette resultat er den eksekverbare fil, hvis filen er et program og ikke et dokument. Et dokument er ikke eksekverbart.
En applikation består af mere end ét (assemblersprog) program. Der er normalt et hovedprogram. Situationen her bør ikke forveksles med situationen for de interruptdrevne baggrundsprogrammer. Alle programmerne her er forgrundsprogrammer, men der er et første- eller hovedprogram.
En compiler er nødvendig i stedet for assembleren, når der er mere end ét forgrundsprogram. Compileren samler hvert af programmerne til en objektkode. Der ville dog være et problem: nogle af kodesegmenterne vil overlappe, fordi programmerne sandsynligvis er skrevet af forskellige personer. Løsningen fra compileren er at flytte alle de overlappende programmer på nær det første på hukommelsespladsen, så programmerne ikke overlapper hinanden. Nu, når det kommer til lagring af variabler, vil nogle variable adresser stadig overlappe hinanden. Løsningen her er at erstatte de overlappende adresser med de nye adresser (bortset fra det første program), så de ikke længere overlapper hinanden. På denne måde vil de forskellige programmer passe ind i de forskellige dele (områder) af hukommelsen.
Med alt det er det muligt for en rutine i et program at kalde en rutine i et andet program. Så compileren linker. Linking refererer til at have startadressen for en underrutine i et program og derefter kalde den i et andet program; som begge er en del af ansøgningen. Begge programmer skal bruge den samme adresse til dette. Slutresultatet er én stor objektkode med alt i binært (bits).
5.15 Gemme, indlæse og køre et program
Et assemblersprog er normalt skrevet i et eller andet editor-program (som kan leveres med assembler-programmet). Editorprogrammet angiver, hvor programmet starter og slutter i hukommelsen (RAM). Kernal SAVE-rutinen i OS ROM'en på Commodore-64 kan gemme et program i hukommelsen på disken. Den dumper bare den sektion (blok) af hukommelsen, som kan indeholde dets instruktionskald til disken. Det er tilrådeligt at have kaldeinstruktionen til SAVE adskilt fra det program, der bliver gemt, så når programmet indlæses i hukommelsen fra disken, vil det ikke gemme sig selv igen, når det køres. At indlæse et assemblersprogsprogram fra disken er en anden slags udfordring, fordi et program ikke kan indlæse sig selv.
Et program kan ikke indlæse sig selv fra disken til hvor det starter og slutter i RAM. Commodore-64 i de dage blev normalt forsynet med en BASIC-tolk til at køre BASIC-sprogprogrammerne. Når maskinen (computeren) tændes, afregner den med kommandoprompten: KLAR. Derfra kan BASIC-kommandoerne eller instruktionerne indtastes ved at trykke på 'Enter'-tasten efter indtastning. BASIC-kommandoen (instruktionen) til at indlæse en fil er:
LOAD “filnavn”,8,1
Kommandoen begynder med det BASIC reserverede ord, som er LOAD. Dette efterfølges af et mellemrum og derefter filnavnet i dobbelte anførselstegn. Enhedsnummeret 8 er efterfulgt af et komma foran. Den sekundære adresse for disken, som er 1, efterfølges, efterfulgt af et komma. Med en sådan fil er startadressen for assemblersprogprogrammet i overskriften på filen på disken. Når BASIC er færdig med at indlæse programmet, returneres den sidste RAM-adresse plus 1 af programmet. Ordet 'returneret' betyder her, at den nederste byte af den sidste adresse plus 1 sættes i µP X-registret, og den højere byte af den sidste adresse plus 1 sættes i µP Y-registret.
Efter indlæsning af programmet skal det køres (udføres). Brugeren af programmet skal kende startadressen for udførelse i hukommelsen. Igen, et andet BASIC-program er nødvendigt her. Det er SYS-kommandoen. Efter at have udført SYS-kommandoen, vil assemblersprogprogrammet køre (og stoppe). Hvis der kræves input fra tastaturet under kørsel, bør assemblersprogprogrammet angive det til brugeren. Efter at brugeren har indtastet dataene på tastaturet og trykket på 'Enter'-tasten, fortsætter assemblersprogprogrammet ved at bruge tastaturindgangen uden forstyrrelser fra BASIC-fortolkeren.
Hvis det antages, at starten af den kørende RAM-adresse for Assembly Language-programmet er C12316, konverteres C123 til base ti, før den bruges med SYS-kommandoen. Konvertering af C12316 til base ti er som følger:
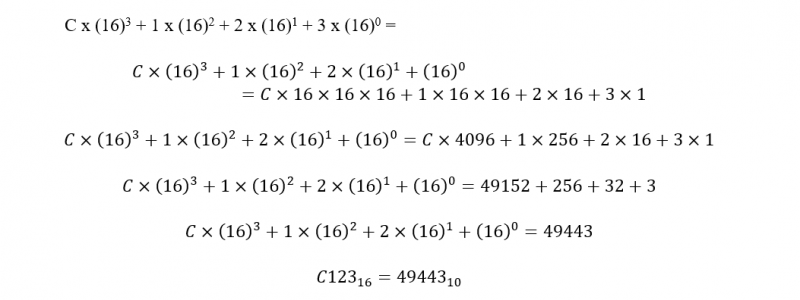
Så BASIC SYS kommandoen er:
SYS 49443
5.16 Opstart til Commodore-64
Opstart af Commodore-64 består af to faser: hardwarenulstillingsfasen og operativsysteminitieringsfasen. Operativsystemet er kernen i ROM (og ikke på en disk). Der er en nulstillingslinje (faktisk RES ), der forbinder til en pin ved 6502 µP og til det samme pinnavn i alle de specielle skibe, såsom CIA 1, CIA 2 og VIC II. I nulstillingsfasen, på grund af denne linje, nulstilles alle registre i µP og i specielle chips til 0 (gjort nul for hver bit). Dernæst gives stakmarkøren og processorstatusregisteret af mikroprocessorhardwaren med deres begyndelsesværdier i mikroprocessoren. Programtælleren gives derefter med værdien (adressen) i $FFFC og $FFFD lokationerne. Husk, at programtælleren indeholder adressen på den næste instruktion. Indholdet (adressen), der opbevares her, er til den underrutine, der starter softwareinitialiseringen. Alt indtil videre er udført af mikroprocessorens hardware. Hele hukommelsen bliver ikke rørt i denne fase. Den næste fase af initialiseringen begynder derefter.
Initialiseringen udføres af nogle rutiner i ROM OS. Initialisering betyder at give start- eller standardværdierne til nogle registre i de specielle chips. Initialisering begynder med at give start- eller standardværdierne til nogle registre i de specielle chips. IRQ skal for eksempel begynde at udstede hver 1/60 af et sekund. Så dens tilsvarende timer i CIA #1 skal indstilles til standardværdien.
Dernæst udfører Kernal en RAM-test. Den tester hver placering ved at sende en byte til placeringen og læse den tilbage. Hvis der er en forskel, er den placering i det mindste dårlig. Kernal identificerer også toppen af hukommelsen og bunden af hukommelsen og sætter de tilsvarende pointere på side 2. Hvis toppen af hukommelsen er $DFFF, sættes $FF i $0283-placeringen, og $DF sættes i $0284-byte-placeringen. Både $0283 og $0284 har HIRAM-mærket. Hvis bunden af hukommelsen er $0800, sættes $00 i $0281 placeringen, og $08 sættes i $0282 placeringen. Både $0281 og $0282 har LORAM-mærket. RAM-testen begynder faktisk fra $0300 til toppen af hukommelsen (RAM).
Til sidst sættes input/output vektorerne (pegerne) til deres standardværdier. RAM-testen begynder faktisk fra $0300 til toppen af hukommelsen (RAM). Det betyder, at side 0, side 1 og side 2 initialiseres. Især side 0 har mange OS ROM-pointere, og side 2 har mange BASIC-pointere. Disse pointere omtales som variabler. Husk at side 1 er stakken. Pointerne omtales som variable, fordi de har navne (etiketter). På dette tidspunkt ryddes skærmens hukommelse for skærmen (monitoren). Dette betyder at sende koden på $20 for plads (hvilket tilfældigvis er det samme som ASCII $20) til de 1000 RAM-skærmplaceringer. Til sidst starter Kernal BASIC-fortolkeren for at vise BASIC-kommandoprompten, som er KLAR øverst på skærmen (skærmen).
5.17 Problemer
Læseren rådes til at løse alle problemerne i et kapitel, før de går videre til næste kapitel.
- Skriv en assemblersprogkode, der gør alle bits af CIA #2 port A som output og CIA #2 port B som input.
- Skriv en 6502-assembly sprogkode, der venter på en tastaturtast, indtil der trykkes på den.
- Skriv et 6502-assembly-sprogprogram, der sender 'E'-tegnet til Commodore-64-skærmen.
- Skriv et 6502-assembly-sprogprogram, der tager et tegn fra tastaturet og sender det til Commodore-64-skærmen, og ignorer nøglekoden og timingen.
- Skriv et 6502-assembly-sprogprogram, der modtager en byte fra Commodore-64-disketten.
- Skriv et 6502-assembly-sprogprogram, der gemmer en fil på Commodore-64-disketten.
- Skriv et 6502-assembly-sprogprogram, der indlæser en programfil fra Commodore-64-disketten og starter den.
- Skriv et 6502-assembly-sprogprogram, der sender byten 'E' (ASCII) til modemmet, som er forbundet til den bruger-RS-232-kompatible port på Commodore-64.
- Forklar, hvordan tælling og timing foregår i Commodore-64 computeren.
- Forklar, hvordan Commodore-64-systemenheden kan identificere 10 forskellige kilder til øjeblikkelig afbrydelsesanmodning, inklusive de ikke-maskerbare afbrydelsesanmodninger.
- Forklar hvordan et baggrundsprogram kan køre med et forgrundsprogram i Commodore-64 computeren.
- Forklar kort, hvordan assemblersprog-programmerne kan kompileres til én applikation til Commodore-64-computeren.
- Forklar kort opstartsprocessen for Commodore-64 computeren.