'Pandas' er et højtydende værktøj til pythonmiljøet. Det er en 'åben' kildekode til analyse af data. Panda-sammenføjnings- og pandafletmetoden bruges til at forbinde de to datarammer til en enkelt dataramme. I begge metoder til pandaer er forskellen, at pandaernes 'join'-funktion forbinder datarammen ved hjælp af et indeks. Mens pandaernes 'fletnings'-funktion tilslutter sig datarammen ved at bruge indekset og kolonnemetoden, hvor vi selv kan vælge den ønskede kolonne. Sammenlægningsmetoden for pandaer bruges for det meste sammenlignet med pandaernes joinmetode. Den software, vi vil bruge til implementeringen, er 'spyder'-softwaren, som er i python-miljøet, som vil give os fordele for kodeimplementeringen af pandas join-metoden() og pandas merge()-metodefunktionen.
Syntaks for Pandas Join()-metoden
'df1. tilslutte ( df2 ) ”'df' i ovenstående syntaks er forkortelsen af 'dataframe'. Der er to datarammer i syntaksen med funktionen 'dot join', som er til at kalde metoden. Det er pandaernes metode til at forbinde to datarammer. Det fungerer ved at bruge indekset til at kombinere datarammerne i en enkelt.
Syntaks for Pandas Merge()-metoden
'df1. fusionere ( df2 , på = 'kolonne_navn' ) ”Syntaksen for pandas-fletningsmetoden har to datarammer som 'df1' og 'df2'. Funktionen 'dot merge' kalder metoden til at forbinde begge datarammer med udseendet af kolonner inverteret.
Vi vil dække følgende måder at kombinere to datarammer på for at bruge metoderne til panda-fusion og pandas join:
- Pandas Sammenføjningsmetode overlapper.
- Pandaer tilslutter sig metoden ved hjælp af en indeksnulstilling.
- Pandas flettemetode (kolonne 'venstre og højre').
- Pandas fusionsmetode eksplicit.
Oprettelse af datarammerne til implementering af Pandas Merge og Pandas Join-metoden
Først skal vi oprette en dataramme. Til det vil vi bruge 'spyder'-værktøjet. Når du har åbnet den, skal du begynde at skrive koden. Importer pandaer som 'pd' for pandas biblioteksforening. Vi har datarammevariablerne som 'x', 'y', 'p' og 'q tilsvarende og 'a' med værdierne '1' og 'b' med værdien tildelt som '2'.

Outputtet er en 'df' oprettet med de tildelte værdier. Vi kan gøre det så stort, som dataene er.
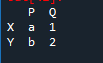
Oprettelse af en anden dataramme
Vi er nødt til at lave en anden dataramme, for at forstå metoderne til, hvordan pandaer går sammen og pandaer smelter sammen. Her har vi 'df' skabt det samme som ovenstående 'df', kun værdierne er variabler tildelt er forskellige. Vi har 'h', 'j', 's' og 'd', hvorimod værdierne 'b' tildeles værdien '8' og 'Y' med værdien '3'.

Outputtet viser en simpel 'df' oprettet.

Eksempel # 01: Panda-sammenføjningsmetode (overlappende)
Nu vil vi se, hvordan man forbinder to datarammer med pandas join-metoden. Til denne metode kan vi vælge den kolonne efter dit valg, vi vil arbejde på fra datarammen. Vi har taget eksemplet med den overlappende kolonne 'venstre' fra 'df', så vi kan rette dette med 'suffikset' for at overvinde overlapningen af data. Her er de anvendte variabler 'x', 'z', 'v', 'd'. 'p', 'o', 'l' og 'y' med værdierne tildelt som '3', '6', '7' og '9'. '.join' kalder metoden, med align sat til venstre join med det højre 'df' suffiks. ”. 'Suffikset' brugt i koden skyldes, at der i datarammen er to kolonner, der har det samme navn, som er 'nøgle', og som ikke vil overlappe dataene.
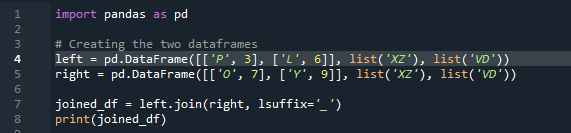
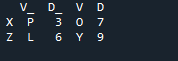
Outputtet viser ingen overlappede data med metoden til at forbinde to 'df' ved hjælp af pandas join-metoden.
Eksempel # 02: Panda-tilslutningsmetode ved hjælp af en indeksnulstilling
I dette eksempel vil vi separat specificere kolonnen med parameteren 'on' for at bruge som 'nøgle' i metodesammenføjningen, der hjælper med at forbinde de to datarammer. det kombinerede gøres med denne parameter. Indekset for en af de to 'df' bør også ligne for at slutte sig til dem. Lignende typer data eller data, der bruges til samme formål, kan være sammen til behandling. Dette vil bruge indekset stadig ved at bruge fra højre. Variablerne er 's', 't', 'u', 'v', 'n', 'w', 'k' og 'q'. De tildelte værdier er '3', '6', '7' og '9'. 'Nulstil punktindekset' er en pandametode til at nulstille indekset for 'df'. Nulstillingsindekset indstiller alle heltal i din datarammeliste fra 0, indtil datarammedataene er der forlænget.
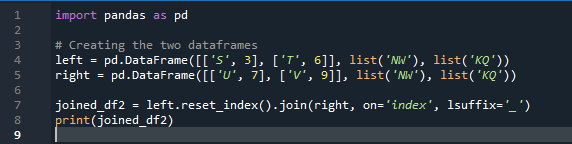
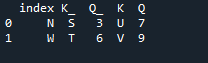
Her er output, der vises med pandaernes indeks 'nøgle'-tilslutningsmetode.
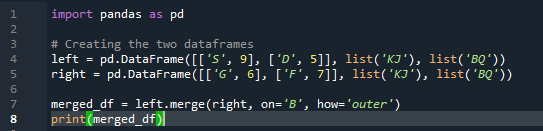
Eksempel # 03: Pandas fletningsmetode (kolonne 'venstre og højre')
Merge-metoden udfører en lignende operation som pandas join-metoden. Begge metoder er til at kombinere data på en lignende dataramme. Fletningsmetoden er mere alsidig og kræver specificering af nøglen. Vi kan også angive det i venstre og højre kolonne afhængigt af arbejdet i din dataramme. Variablerne i koden er 's', 'd', 'g', 'f', 'k', 'j', 'b' og 'q'. de tildelte værdier er '9', '5', '6' og '7'. Den ydre 'join'-implementering udføres på begge 'df' ved at bruge parameteren 'how' i pandaernes flettemetodefunktion.
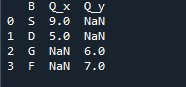
Det output, vi ser, viser de fusionerede data for de to datarammer. 'NaN' repræsenterer 'ikke et tal', hvilket betyder, at hvor der ikke er tildelt et tal i dataene, viser 'NaN' der.
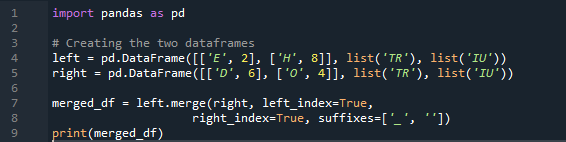
Eksempel # 04: Merge-metoden eksplicit
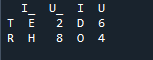
Her, i dette eksempel, er flettemetoden ødelæggelsen af indekset, og indeksværdien antages ikke på datarammen. Vi vil gøre denne metode i henhold til det arbejde, der skal udføres, hvor den specificerende eksplicitte skal følge op. Det vil flette dataene baseret på et venstre indeks eller højre indeks med parameteren. Variablerne i denne dataramme er 't', 'r', 'I', 'u', 'h', 'o', 'e' og 'e'. De tildelte værdier er '2', '4', '6' og '4'. Ovenstående eksempel på pandaernes fusionsmetode med kolonnevalg efter behov er den mest præsentable og værdifulde metode til at forbinde de to datarammer. Kontrollerer i slutningen af kodelinjen om flettenøglen er unik i datasættet.
I nedenstående output vises indekset ikke uden indekset, men funktionen udføres baseret på højre og venstre indeks.
Konklusion
Merge()- og join()-metoderne er begge metoder, der er meget praktiske og effektive. Begge disse funktioner bruges til at forbinde de to separate dataramme på den samme dataramme, men har forskellig anvendelse afhængigt af sagen. I denne artikel har vi lært de vigtigste forskelle mellem pandaernes join- og merge-metoden. Efter at have gennemgået eksemplerne og forstået pandas-sammenføjningsmetoden, vil vi afslutte det med den viden, at hvis vi ønsker mere fleksibel sammenføjning i databasestil, er det at foretrække at gå med pandas-sammenføjningsmetoden. På den anden side, hvis vi ønsker at kombinere datarammen med indekset i vid udstrækning, kan vi gå med pandas join() metodefunktionen.