Dette indlæg dækker PostgreSQL-partitioneringen. Vi vil diskutere de forskellige partitioneringsmuligheder, som du kan bruge, og give eksempler på, hvordan du bruger dem for bedre forståelse.
Sådan opretter du PostgreSQL-partitionerne
Enhver database kan indeholde adskillige tabeller med flere poster. For nem administration bør du partitionere tabellerne, hvilket er en fantastisk og anbefalet datavarehusrutine til databaseoptimering og for at hjælpe med pålidelighed. Du kan oprette forskellige partitioner, herunder listen, rækkevidden og hash. Lad os diskutere hver enkelt i detaljer.
1. Listepartitionering
Før vi overvejer en partitionering, skal vi oprette tabellen, som vi vil bruge til partitionerne. Når du opretter tabellen, skal du følge den givne syntaks for alle partitioner:
OPRET TABEL tabelnavn(kolonne1 datatype, kolonne2 datatype) PARTITION BY
'Tabelnavn' er navnet på din tabel sammen med de forskellige kolonner, som tabellen vil have, og deres datatyper. For 'partition_key' er det den kolonne, som partitioneringen vil finde sted. For eksempel viser følgende billede, at vi oprettede 'kurser'-tabellen med tre kolonner. Desuden er vores partitioneringstype LIST, og vi vælger fakultetskolonnen som vores partitioneringsnøgle:

Når tabellen er oprettet, skal vi oprette de forskellige partitioner, som vi har brug for. For at gøre det, fortsæt med følgende syntaks:
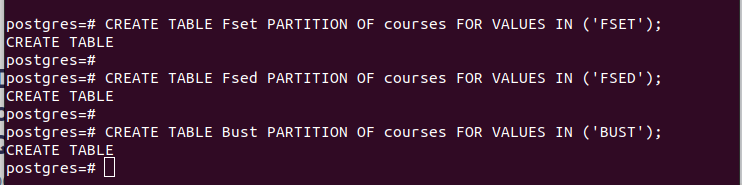
CREATE TABLE partition_table PARTITION AF main_table FOR VÆRDIER I (VÆRDI);For eksempel viser det første eksempel i det følgende billede, at vi oprettede en partitionstabel ved navn 'Fset', som indeholder alle værdier i kolonnen 'fakultet', som vi valgte som vores partitionsnøgle, hvis værdi er 'FSET'. Vi brugte en lignende logik til de to andre partitioner, som vi oprettede.
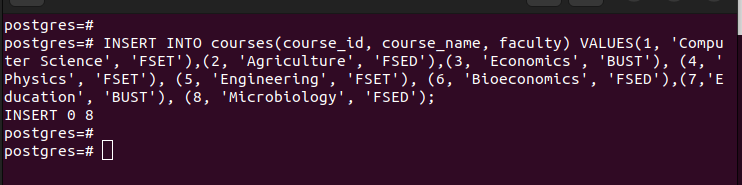
Når du har partitionerne, kan du indsætte værdierne i hovedtabellen, som vi oprettede. Hver værdi, du indsætter, matches med den respektive partitionering baseret på værdierne i den partitionsnøgle, du valgte.
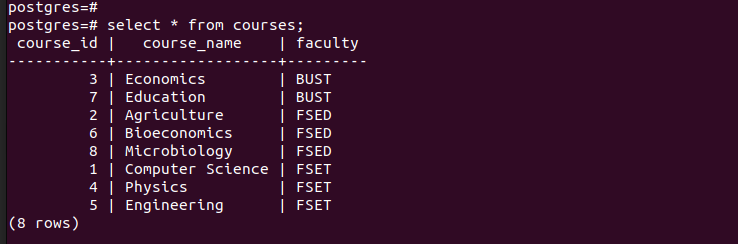
Hvis vi lister alle posterne i hovedtabellen, kan vi se, at den har alle de poster, vi har indsat.
For at bekræfte, at vi har oprettet partitionerne, lad os tjekke posterne i hver af de oprettede partitioner.
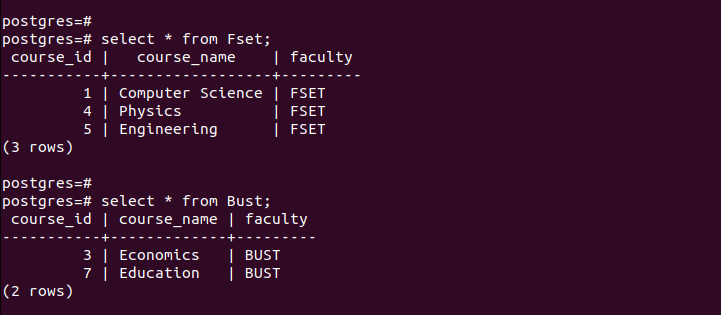
Bemærk, hvordan hver partitioneret tabel kun indeholder de poster, der matcher de kriterier, der er defineret ved partitionering. Sådan fungerer opdeling efter liste.
2. Rækkeviddeopdeling
Et andet kriterium for at oprette partitioner er at bruge RANGE-indstillingen. Til dette skal vi angive de start- og slutværdier, der skal bruges for området. Brug af denne metode er ideel, når du arbejder med datoer.
Dens syntaks til at oprette hovedtabellen er som følger:
OPRET TABEL tabelnavn(kolonne1 datatype, kolonne2 datatype) PARTITION BY RANGE (partitionsnøgle);Vi oprettede tabellen 'cust_orders' og specificerede den til at bruge datoen som vores 'partition_key'.

For at oprette partitionerne skal du bruge følgende syntaks:
CREATE TABLE partition_table PARTITION AF main_table FOR VÆRDIER FRA (start_værdi) TIL (slut_værdi);Vi definerede vores partitioner til at fungere kvartalsvis ved hjælp af kolonnen 'dato'.
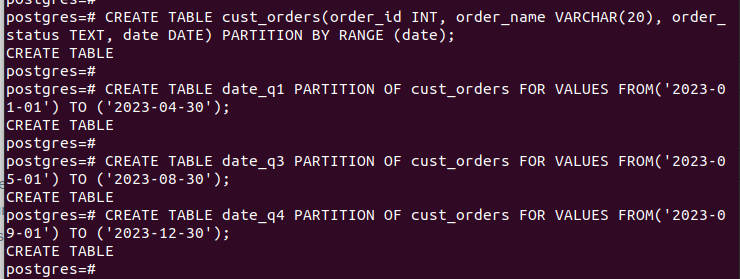
Efter at have oprettet alle partitionerne og indsat dataene, ser vores tabel sådan ud:
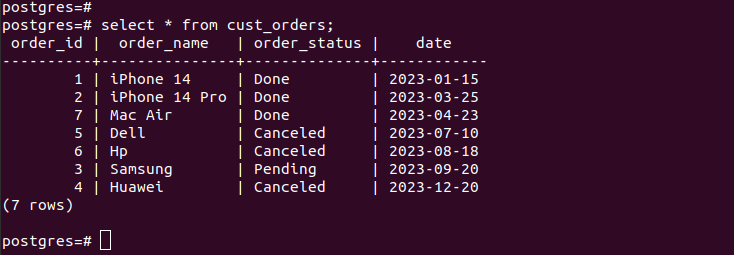
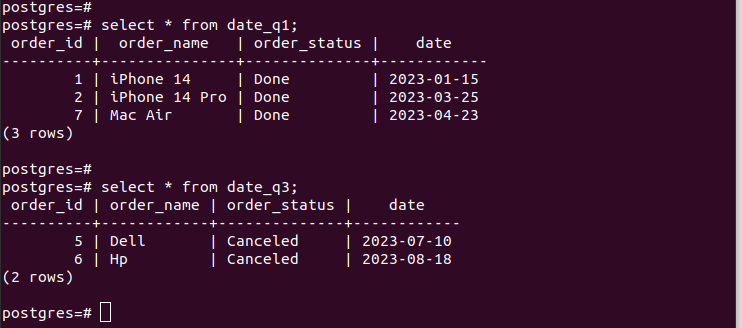
Hvis vi tjekker indtastningerne i de oprettede partitioner, verificerer vi, at vores partitionering fungerer, og vi har kun de relevante poster i henhold til de partitioneringskriterier, vi har angivet. For alle de nye poster, som du tilføjer til din tabel, tilføjes de automatisk til den respektive partition.
3. Hash-partitionering
Det sidste partitioneringskriterium, som vi vil diskutere, er at bruge hash. Lad os hurtigt oprette hovedtabellen ved hjælp af følgende syntaks:
OPRET TABEL tabelnavn(kolonne1 datatype, kolonne2 datatype) PARTITION BY HASH (partitionsnøgle); 
Når du partitionerer med hash, skal du angive modulet og resten, rækkerne, der skal divideres med hashværdien af din specificerede 'partition_key'. I vores tilfælde bruger vi et modul på 4.
Vores syntaks er som følger:
CREATE TABLE partition_table PARTITION AF main_table FOR VÆRDIER MED (MODUL num1, REMAINDER num2);Vores skillevægge er som følger:
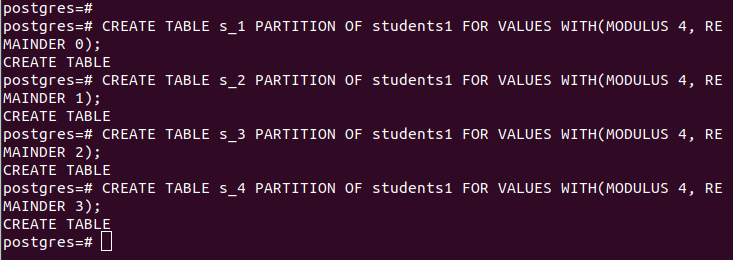
For 'main_table' indeholder den de poster, der er vist i følgende:
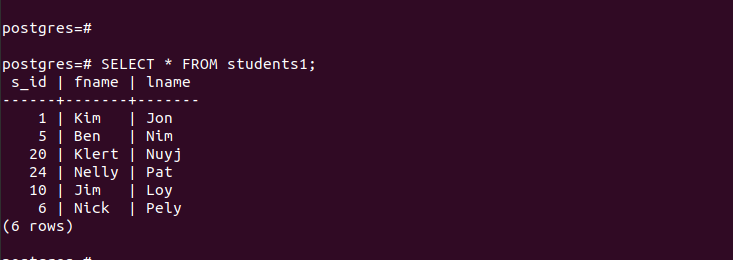
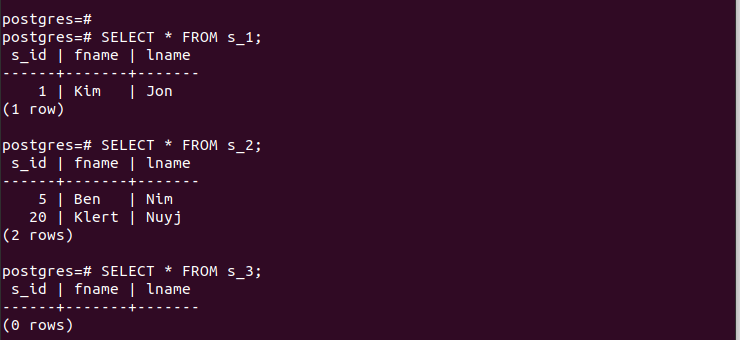
For de oprettede partitioner kan vi hurtigt få adgang til deres poster og kontrollere, at vores partitionering fungerer.
Konklusion
PostgreSQL-partitioner er en praktisk måde at optimere databasen for at spare tid og øge pålideligheden. Vi diskuterede partitioneringen i detaljer, herunder de forskellige tilgængelige muligheder. Desuden gav vi eksempler på, hvordan man implementerer partitionerne. Prøv dem!