Multiprocessing kan sammenlignes med multithreading. Det adskiller sig dog ved, at vi kun kan udføre én tråd ad gangen på grund af den GIL, der bruges til trådning. Multiprocessing er processen med at udføre operationer sekventielt på tværs af flere CPU-kerner. Tråde kan ikke betjenes parallelt. Men multiprocessing giver os mulighed for at etablere processerne og køre dem samtidigt på forskellige CPU-kerner. Sløjfen, såsom for-loop, er et af de mest brugte scriptsprog. Gentag det samme arbejde med forskellige data, indtil et kriterium, såsom et forudbestemt antal iterationer, er nået. Sløjfen udfører hver iteration én efter én.
Eksempel 1: Brug af For-Loop i Python Multiprocessing Module
I dette eksempel bruger vi klasseprocessen for-loop og Python multiprocessing modul. Vi begynder med et meget ligetil eksempel, så du hurtigt kan forstå, hvordan Python multiprocessing for-loop fungerer. Ved at bruge en grænseflade, der kan sammenlignes med gevindmodulet, pakker multiprocessingen skabelsen af processer.
Ved at anvende underprocesserne i stedet for tråde, giver multiprocessing-pakken både lokal og fjern samtidighed og undgår dermed Global Interpreter Lock. Brug en for-loop, som kan være et strengobjekt eller en tupel, til løbende at iterere gennem en sekvens. Dette fungerer mindre som nøgleordet set i andre programmeringssprog og mere som en iteratormetode, der findes på andre programmeringssprog. Ved at starte en ny multiprocessing kan du køre en for-loop, der udfører en procedure samtidigt.
Lad os begynde med at implementere koden til kodeudførelse ved at bruge 'spyder' -værktøjet. Vi mener, at 'spyder' også er den bedste til at køre Python. Vi importerer en multiprocessing-modulproces, som koden kører. Multiprocessing i Python-konceptet kaldet en 'procesklasse' skaber en ny Python-proces, giver den en metode til at udføre kode og giver den overordnede applikation en måde at styre udførelsen på. Process-klassen indeholder start()- og join()-procedurerne, som begge er afgørende.
Dernæst definerer vi en brugerdefineret funktion kaldet 'func'. Da det er en brugerdefineret funktion, giver vi den et navn efter eget valg. Inde i kroppen af denne funktion sender vi 'emne'-variablen som et argument og 'matematik'-værdien. Dernæst kalder vi 'print()'-funktionen og sender sætningen 'Navnet på det fælles emne er' såvel som dets 'emne'-argument, der indeholder værdien. Derefter, i det følgende trin, bruger vi 'if name== _main_', som forhindrer dig i at køre koden, når filen importeres som et modul og kun tillader dig at gøre det, når indholdet udføres som et script.
Betingelsesafsnittet, du begynder med, kan i de fleste tilfælde opfattes som en placering til at levere det indhold, der kun bør udføres, når din fil kører som et script. Derefter bruger vi argumentet emnet og gemmer nogle værdier i det, som er 'videnskab', 'engelsk' og 'computer'. Processen får derefter navnet 'proces1[]' i det følgende trin. Derefter bruger vi 'proces(target=func)' til at kalde funktionen i processen. Target bruges til at kalde funktionen, og vi gemmer denne proces i 'P'-variablen.
Dernæst bruger vi 'proces1' til at kalde funktionen 'append()', som tilføjer et element til slutningen af listen, som vi har i funktionen 'func.' Fordi processen er gemt i 'P'-variablen, sender vi 'P' til denne funktion som dens argument. Til sidst bruger vi 'start()'-funktionen med 'P' for at starte processen. Derefter kører vi metoden igen, mens vi angiver 'emne'-argumentet og bruger 'for' i emnet. Derefter, ved at bruge 'proces1' og 'add()'-metoden igen, begynder vi processen. Processen kører derefter, og outputtet returneres. Proceduren får derefter besked på at afslutte ved at bruge 'join()'-teknikken. De processer, der ikke kalder 'join()'-proceduren, afsluttes ikke. Et afgørende punkt er, at søgeordsparameteren 'args' skal bruges, hvis du vil give nogen argumenter gennem processen.
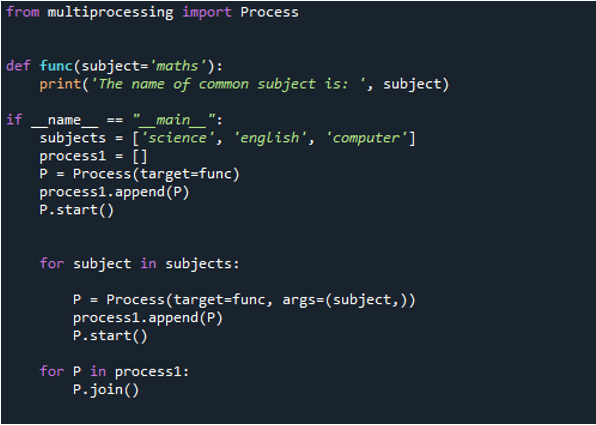
Nu kan du se i outputtet, at sætningen vises først ved at overføre værdien for 'matematik'-faget, som vi overfører til 'func'-funktionen, fordi vi først kalder det ved hjælp af 'proces'-funktionen. Derefter bruger vi kommandoen 'append()' til at have værdier, der allerede var på listen, som tilføjes til sidst. Derefter blev 'videnskab', 'computer' og 'engelsk' præsenteret. Men som du kan se, er værdierne ikke i den rigtige rækkefølge. Dette skyldes, at de gør det, så hurtigt som proceduren er afsluttet, og rapporterer deres besked.
Eksempel 2: Konvertering af sekventiel for-loop til multiprocessing parallel for-loop
I dette eksempel udføres multiprocessing-loop-opgaven sekventielt, før den konverteres til en parallel for-loop-opgave. Du kan bladre gennem sekvenser som en samling eller streng i den rækkefølge, de opstår, ved at bruge for-loops.
Lad os nu begynde at implementere koden. Først importerer vi 'søvn' fra tidsmodulet. Ved at bruge 'sleep()'-proceduren i tidsmodulet kan du suspendere udførelsen af den kaldende tråd, så længe du vil. Derefter bruger vi 'random' fra det tilfældige modul, definerer en funktion med navnet 'func', og sender nøgleordet 'argu'. Derefter opretter vi en tilfældig værdi ved hjælp af 'val' og indstiller den til 'tilfældig'. Derefter blokerer vi i en lille periode ved at bruge 'sleep()'-metoden og sender 'val' som en parameter. Derefter, for at sende en meddelelse, kører vi 'print()'-metoden, sender ordene 'ready' og nøgleordet 'arg' som parameter, såvel som 'created' og sender værdien ved hjælp af 'val'.
Til sidst bruger vi 'flush' og indstiller den til 'True'. Brugeren kan beslutte, om outputtet skal bufferes eller ej ved at bruge flush-indstillingen i Pythons printfunktion. Denne parameters standardværdi på False angiver, at outputtet ikke vil blive bufferet. Outputtet vises som en række linjer efter hinanden, hvis du indstiller det til sandt. Derefter bruger vi 'if name== main' for at sikre indgangspunkterne. Dernæst udfører vi jobbet sekventielt. Her sætter vi området til '10', hvilket betyder, at løkken slutter efter 10 iterationer. Dernæst kalder vi 'print()'-funktionen, sender den 'ready' input-sætningen og bruger 'flush=True'-indstillingen.
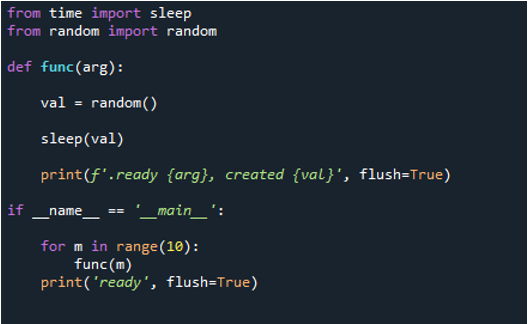
Du kan nu se, at når vi udfører koden, får loopen funktionen til at køre '10' gange. Den gentager sig 10 gange, starter ved indeks nul og slutter ved indeks ni. Hver besked indeholder et opgavenummer, som er et funktionsnummer, som vi indtaster som et 'arg' og et oprettelsesnummer.
Denne sekventielle sløjfe er nu ved at blive transformeret til en multiprocessing parallel for-loop. Vi bruger den samme kode, men vi skal til nogle ekstra biblioteker og funktioner til multiprocessing. Derfor skal vi importere processen fra multiprocessing, ligesom vi forklarede tidligere. Dernæst opretter vi en funktion kaldet 'func' og sender nøgleordet 'arg', før vi bruger 'val=random' for at få et tilfældigt tal.
Derefter, efter at have påkaldt 'print()'-metoden for at vise en meddelelse og givet 'val'-parameteren for at forsinke en lille periode, bruger vi funktionen 'if name= main' til at sikre indgangspunkterne. Hvorefter vi opretter en proces og kalder funktionen i processen ved hjælp af 'process' og videregiver 'target=func'. Derefter sender vi 'func', 'arg', sender værdien 'm' og passerer området '10', hvilket betyder, at løkken afslutter funktionen efter '10' iterationer. Derefter starter vi processen ved at bruge 'start()'-metoden med 'proces'. Derefter kalder vi 'join()'-metoden for at vente på udførelsen af processen og for at fuldføre hele processen efter.
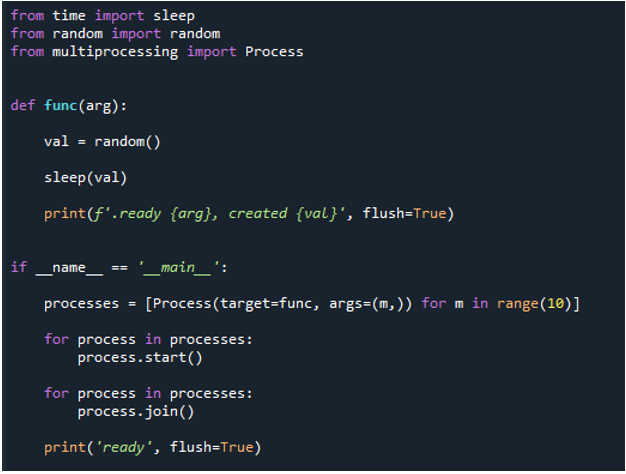
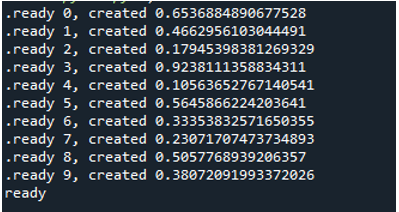
Derfor, når vi udfører koden, kalder funktionerne hovedprocessen og begynder deres eksekvering. De udføres dog, indtil alle opgaverne er udført. Det kan vi se, fordi hver opgave udføres samtidigt. Den rapporterer sin besked, så snart den er færdig. Dette betyder, at selvom meddelelserne er ude af funktion, slutter løkken efter alle '10' iterationer er gennemført.
Konklusion
Vi dækkede Python multiprocessing for-loop i denne artikel. Vi præsenterede også to illustrationer. Den første illustration viser, hvordan man bruger en for-loop i Pythons loop-multiprocessing-bibliotek. Og den anden illustration viser, hvordan man ændrer en sekventiel for-loop til en parallel multiprocessing for-loop. Før vi konstruerer scriptet til Python multiprocessing, skal vi importere multiprocessing modulet.