'I 'pandas' kan vi nemt læse tekstfilen ved hjælp af 'pandas'-metoden. 'Pandas' giver os mulighed for at læse tekstfilen. 'Pandas' giver forskellige indbyggede metoder til at læse tekstfilen. Vi vil diskutere alle metoder i denne tutorial sammen med alle parametre her og vil forklare dem i detaljer. Vi vil også læse tekstfilen i 'pandas' ved at bruge metoderne til 'pandas' i vores koder her.'
Metoder til at læse tekstfilen i 'pandaer'
I 'pandaer' har vi tre metoder, der hjælper os med at læse tekstfilen. Vi har også lavet nogle eksempler her, hvor vi læser tekstfilen. Metoderne, som 'pandaerne' giver, diskuteres nedenfor:
-
- Ved at bruge pd.read_csv() metoden.
- Ved at bruge pd.read_table() metoden.
- Ved at bruge pd.read_fwf() metoden.
Nu forklarer vi syntaksen for alle disse metoder og diskuterer også parametrene for alle metoder i detaljer i denne tutorial.
Syntaks for read_csv()
pd.read_csv ( 'filnavn.txt', sep =' ', header = Ingen, navne = [ “Col_name1”, “Col_name2, “Col_name2”, ………….. ] )
I denne metode tilføjer vi først navnet på den tekstfil, hvis data vi vil læse, og det er den første parameter i denne metode. Derefter placerer vi 'sep', som er en separator i denne metode, og vi placerer rummet her som tegnet, så det vil betragte rummet som separatoren. Efter dette har vi header-parameteren, og 'Ingen'-værdien af denne parameter bruges, så den vil oprette standardheaderen, og hvis vi ikke tilføjer denne parameter, vil den overveje den første linje i tekstfilen som overskrift. I parameteren 'navne' kan vi tilføje kolonnenavne, som vi skal tilføje som overskrift.
Syntaks for read_table()
pd.læse_tabel ( 'filnavn.txt' , afgrænsning = ' ' )
I denne metode sætter vi filnavnet på tekstfilen som den første parameter. I afgrænsningstegnet, når vi placerer ' ', vil det tage mellemrumstegnet som separator.
Syntaks for read_fwf()
pd.read_fwf ( 'filnavn.txt' )
Denne metode tager kun én parameter, som er navnet på tekstfilen.
Nu vil vi bruge disse metoder til at læse tekstfilerne i 'pandas' koder og vise tekstfilens data på terminalen.
Eksempel #01
'Spyder'-appen er her, hvor vi har lavet alle disse koder, som præsenteres i denne tutorial. Tekstfilen, hvis data vi ønsker at læse, er vist nedenfor. Vi vil bruge 'read_csv()'-metoden til at læse denne tekstfil i 'pandas'.
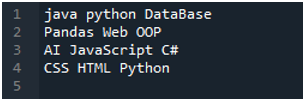
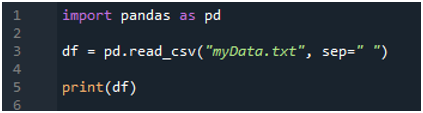
Vi importerer først 'pandas'-biblioteket, fordi vi ønsker at bruge 'read_csv()'-metoden, og det er metoden for 'pandas'. Vi får kun adgang til denne metode, når vi har importeret biblioteket af 'pandaer'. Her nævner vi 'pandaer som pd', så denne 'pd' er placeret med navnet på metoden til at bruge det. Herefter opretter vi en variabel 'df', som bruges til at gemme tekstfilens data efter læsning. Vi placerer 'pd.read_csv()'-metoden her, som hjælper med at læse tekstfilen og konvertere tekstfildataene til DataFrame og gemme dem i 'df'-variablen.
Vi har sendt filnavnet, som er 'myData.txt,' her, og så bruger vi 'sep' og tildeler det tomme tegn til denne 'sep'. Så dette tomme tegn fungerer som separator i tekstfilen. Derefter brugte vi 'print()' nedenfor, som bruges til at udskrive dataene i tekstfilen. Det vil vise dataene i tekstfilen i DataFrame-formen.
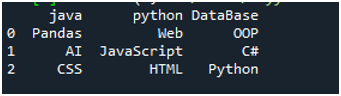
For at udføre denne kode skal vi trykke på 'Shift+Enter', og outputtet vil blive gengivet på 'Spyders' terminalen. Resultatet af ovenstående kode vises i det givne skærmbillede, og du kan se, at dataene i tekstfilen vises som DataFrame, og den første linje i vores tekstfil præsenteres her som kolonnenavnene på den DataFrame. Den adskiller også de data, hvor mellemrumstegnet er til stede i tekstfilen.
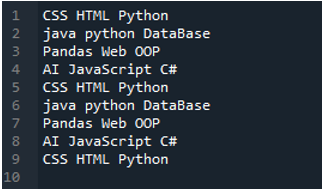
Eksempel #02
Tekstfilen, som vi vil læse i dette eksempel, er vist her, og vi vil igen bruge metoden 'read_csv()', men med andre parametre.
“Pandas” metoden “pd.read_csv()” bruges, og vi sender tre parametre her. Først placerer vi filnavnet, som er 'Record.txt'. Den anden parameter er 'sep'-parameteren og tildeler den tomme karakter til den, og så har vi den tredje parameter, hvor vi indstiller 'headeren' og justerer den til 'Ingen', så den vil oprette standardoverskriften for DataFrame når vi udfører denne kode. Vi har gemt alt dette i 'My_Record'-variablen og også tilføjet 'My_Record' i 'print()'-funktionen til udskrivning.

Alle data gemmes i DataFrame, og den adskiller de data, hvor mellemrumstegnet er til stede i tekstfilens data. Det oprettede også standardoverskriften for DataFrame her, fordi vi justerede 'header'-parameteren til 'Ingen'.
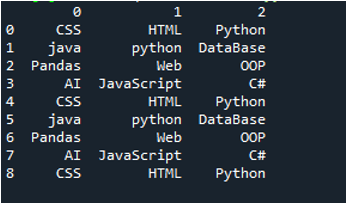
Eksempel #03
Dette eksempels tekstfil vises, og vi vil igen bruge 'read_csv()'-metoden med ændrede parametre.
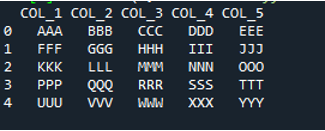
I denne kode sendes fire parametre her til 'pandas'-metoden 'pd.read_csv()'. Tekstfilens navn er den første parameter. Parameteren 'sep' får det tomme tegn i den anden parameter. Parameteren 'header' er sat til 'Ingen' i det tredje argument, og som den fjerde parameter har vi sat 'navnene', som vil fremstå som kolonnenavnene på DataFrame efter læsning af tekstfilen, og disse kolonnenavne er 'COL_1, COL_2, COL_3, COL_4 og COL_5'. Alle disse oplysninger er blevet gemt i 'My_Record'-variablen, og 'My_Record' er også blevet tilføjet til 'print()'-metoden, så den udskrives på terminalen.

Al information i tekstfilen gengives her som DataFrame, og den adskiller også dataene, hvor mellemrummene er tilføjet i tekstfilen. Det tilføjer også kolonnenavnene i overensstemmelse hermed, som vi har tilføjet ovenfor i koden.
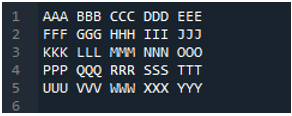
Eksempel #04
Dette er den tekstfil, vi vil læse i dette eksempel ved at bruge en anden metode, 'pd.read_table()'-metoden.
Metoden 'pd.read_table()' tilføjes her for at læse tekstfilen, og vi tilføjer 'ABC.txt', som er tekstfilens navn. Denne metode hjælper med at læse tekstfilen, og vi har også justeret parameteren 'delimiter' til mellemrumstegnet, så det vil også fungere som separatoren, som vi har forklaret ovenfor. Derefter gemmes al tekstens fildata i variablen 'My_Data' og udskrives også her.

Den indledende linje i vores tekstfil vises her som kolonnenavnene på DataFrame, og dataene i tekstfilen udskrives som DataFrame. Derudover adskiller den dataene i tekstfilen, hvor mellemrumstegnet er til stede i den.
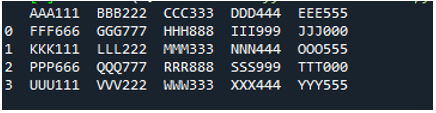
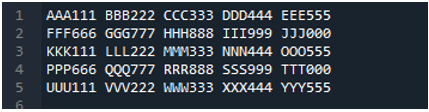
Eksempel #05
Nu indeholder tekstfilen dataene, som vises nedenfor. Vi vil anvende 'read_fwf()' denne gang og vil vise, hvordan den gengiver data efter at have læst tekstfilen.
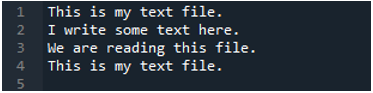
Som vi ved, at denne 'read_fwf()'-metode kun tager én parameter, som er det filnavn, vi ønsker at læse. Vi tilføjer 'textfile.txt' her, som er navnet på vores tekstfil, og tildeler denne pandas-metode til 'File_Data'-variablen, som gemmer dataene i denne tekstfil. Så sætter vi 'print(File_Data)', så det også udskriver disse data.

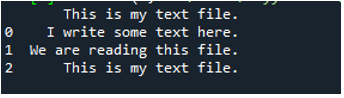
Her vises alle data i tekstfilen. Den adskilte ikke dataene, hvor der er mellemrumstegn, fordi der ikke er nogen parameter som 'Sep' eller 'afgrænser' i denne funktion.
Konklusion
Denne vejledning forklarer, hvordan man læser tekstfilen i 'pandaer', og hvilke metoder der bruges til at læse tekstfilen i 'pandaer'. Vi har diskuteret alle metoder, der hjælper os med at læse tekstfilen i 'pandaer'. Vi har udforsket tre forskellige metoder til 'pandaer' til at læse vores tekstfiler i 'pandaer' i denne vejledning. Vi har også forklaret syntaksen for alle metoder samt parametrene for alle metoder i detaljer her og har læst mange tekstfiler ved at anvende forskellige metoder med alle mulige parametre i denne tutorial.