Pandaer er blandt de mest populære værktøjer, der i dag bruges af dataforskere til at analysere tabeldata. For at håndtere tabelindhold tilbyder den en hurtigere og mere effektiv API. Når vi ser datarammer under analyse, indstiller Pandas automatisk forskellige visningsadfærd til standardværdier. Disse visningsadfærd omfatter, hvor mange rækker og kolonner der skal vises, nøjagtigheden af flydende data i hver dataramme, kolonnestørrelser osv. Afhængigt af kravene kan vi lejlighedsvis være nødt til at ændre disse standardindstillinger. Pandaer har en række forskellige tilgange til at ændre standardadfærd. Udnyttelse af pandaernes 'optioner'-attribut gjorde det muligt for os at ændre denne adfærd.
Pandaer viser maksimalt antal rækker
Når du forsøger at udskrive en enorm dataramme, der indeholder flere rækker og kolonner end den foruddefinerede tærskel, vil outputtet blive trimmet. For at vise alle rækker i DataFrame lærer du, hvordan du ændrer Pandas' visningsmuligheder i denne vejledning. Pandaer pålægger som standard en grænse for antallet af kolonner og rækker, den udviser. Selvom dette kan være nyttigt til at læse indhold, forårsager det ofte frustration, hvis de oplysninger, du skal se, ikke vises. Her vil vi bruge metoderne givet nedenfor med deres syntaks til at vise alle kolonnerne i datarammen.
to_string()

set_option()

option_context()

Vi vil lære at bruge alle disse metoder med praktisk implementering for at vise maksimale rækker i den medfølgende dataramme.
Eksempel # 1: Brug af Pandas to_string() metode
Denne demonstration vil lære os at vise maksimale rækker i en dataramme på terminalen ved at bruge pandas 'to_string()' metoden.
Til kompilering og udførelse af prøveprogrammerne har vi valgt 'Spyder'-værktøjet. I denne guide vil vi bruge dette værktøj til at udføre alle vores eksempler. Vi har lanceret 'Spyder'-værktøjet for at begynde at skrive python-scriptet. Begyndende med koden skal vi først indlæse de nødvendige biblioteker i vores python-fil, så vi får lov til at bruge dens funktioner. Modulbiblioteket, vi har brug for her, er 'Pandas'. Så vi importerede det til vores python-fil og aliaserede det til 'pd'.
Da hovedoperationen i denne artikel er at vise de maksimale rækker af en dataramme, har vi først brug for en dataramme. Det er nu op til dig, om du foretrækker at generere en dataramme eller importere en CSV-fil. Vi har importeret en eksempel-CSV-fil. For at læse en CSV-fil ind i python-programmet har vi brugt pandas 'pd.read_csv()'-funktionen. Mellem parenteserne af denne funktion har vi leveret den CSV-fil, vi ønsker, til at læse displayet, som er 'industry.csv'. Vi har konstrueret en variabel 'df' til at gemme output genereret fra læsning af den medfølgende CSV-fil. Derefter påberåbte vi 'print()'-metoden for at vise datarammen.
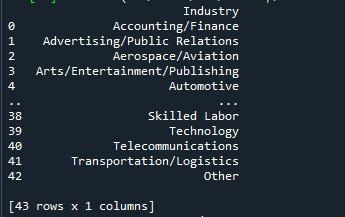
Når vi kører dette python-program ved at trykke på 'Kør fil', vises en dataramme på konsollen. Du kan se, at der er 43 rækker i resultatet nedenfor, men kun ti vises. Dette skyldes, at Pandas-bibliotekets standardværdi kun er 10 rækker.
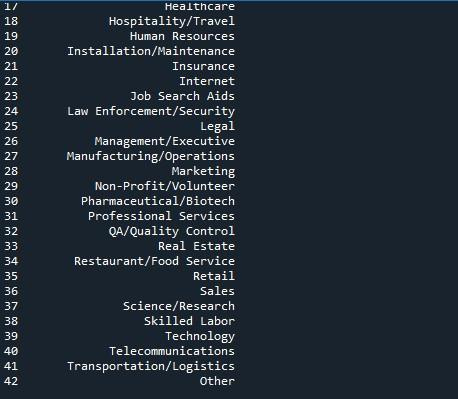
Vi vil bruge panda-metoden 'to_string' til at vise alle rækker her. Den mest ligetil måde at vise maksimale rækker fra en dataramme på er med denne teknik. Men da det forvandler hele datarammen til en enkelt streng, anbefales det ikke til meget store datasæt (i millioner). Ikke desto mindre virker dette effektivt for datasæt, der er i længden af tusinder.
Vi har fulgt syntaksen ovenfor for funktionen 'to_string()'. Vi påberåbte simpelthen metoden 'to_string()' med navnet på vores dataramme. Derefter placerede vi denne metode i 'print()'-funktionen for at vise den, når den blev kaldt.

Output-øjebliksbilledet viser os en dataramme med alle rækkerne, der vises på terminalen.
Eksempel # 2: Brug af Pandas set_option metode
Den anden metode, vi vil øve i denne vejledning, er pandaerne 'set_option()' for at vise de maksimale rækker af den medfølgende dataramme.
I python-filen har vi importeret pandas-biblioteket for at få adgang til ovennævnte funktion. Vi har brugt pandaerne 'pd.read_csv()' til at læse den medfølgende CSV-fil. Vi påkaldte 'pd.read_CSV()'-funktionen med navnet på den CSV-fil, vi vil bruge mellem dens parentes, som er 'Sampledata.csv'. Når du importerer CSV-filen, skal du huske den aktuelle arbejdsmappe for Python-programmet. Din CSV-fil skal placeres i samme mappe; ellers vil du få en fejlmeddelelse 'filen blev ikke fundet'. Vi har lavet en variabel 'sample' til at gemme datarammen fra CSV-filen. Vi kaldte 'print()'-metoden for at vise denne dataramme.
Her har vi vores output, hvor kun ti rækker vises. Det maksimale antal rækker, der er angivet, er 99. Alle de andre rækker mellem de første 5 og de sidste fem rækker er afkortet.

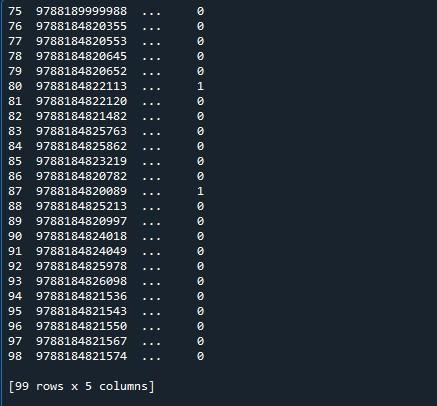
For at vise de maksimale rækker, som er 99 for denne dataramme, vil vi bruge funktionen 'set_option()' i pandas-modulet. Pandaer kommer med et operativsystem, der giver dig mulighed for at ændre adfærd og visning. Denne metode gør det muligt for os at indstille skærmen til at vise en fuld dataramme i stedet for en trunkeret. Pandaer har funktionen 'set_ option()' til at vise alle rækker i datarammen.
Vi har påberåbt 'pd.set_option()'. Denne funktion har parametrene 'display.max_rows'. 'display.max_rows' angiver det maksimale antal rækker, der vil blive vist, når en dataramme vises. Værdien af 'max_rows' er som standard sat til 10. Hvis 'Ingen' er valgt, betyder det alle rækker i datarammen. Da vi ønsker at vise alle rækkerne, sætter vi det til 'Ingen'. Til sidst brugte vi 'print()'-funktionen til at vise datarammen med maks. rækker.

Dette giver resultatet i nedenstående øjebliksbillede.
Eksempel # 3: Brug af Pandas option_context() metode
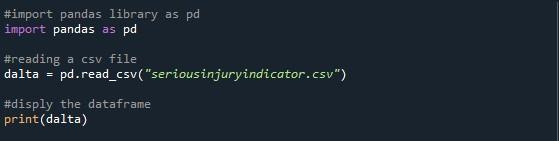
Den sidste metode, vi diskuterer her, er 'option_context()' for at vise alle datarammens rækker. Til dette importerede vi pandas-pakken til python-filen og begyndte at skrive koden. Vi har brugt 'pd.read_csv()'-funktionen til at læse den CSV-fil, vi har specificeret. Vi oprettede en variabel 'dalta' for at gemme datarammen fra den angivne CSV-fil. Derefter udskrev vi blot datarammen med metoden 'print()'.
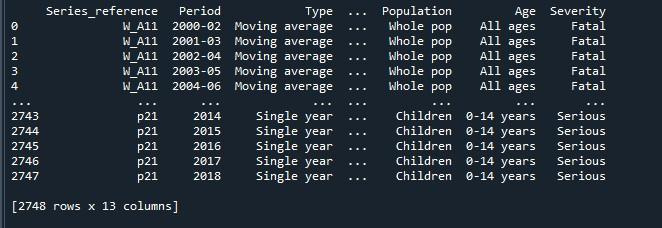
Det resultat, vi opnåede ved at udføre ovenstående kode, viser os en dataramme med trunkerede rækker.
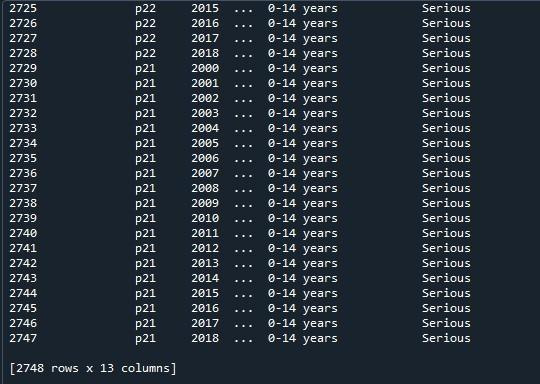
Vi vil nu anvende pandaerne 'pd.option_context()' på denne dataramme. Denne funktion er identisk med 'set_option()'. Den eneste forskel mellem de to tilgange er, at 'set_option()' ændrer indstillingerne permanent, hvorimod 'option _context()' bare ændrede dem inden for sit omfang. Denne metode tager også display.max rows som en parameter, som vi indstiller til 'None' for at gengive alle rækker i datarammen. Efter at have påkaldt denne funktion, viste vi den bare gennem 'print()'-metoden.

Her kan vi se den komplette dataramme med dens maksimale rækker, som er 2747.
Konklusion
Denne artikel fokuserer på pandaernes visningsmuligheder. Vi kan nogle gange have brug for at se hele datarammen på terminalen. Pandaer giver os en række muligheder til det formål. I denne guide har vi brugt tre af disse strategier. Det første eksempel var baseret på at bruge metoden 'to_string()'. Vores anden instans lærer os at implementere 'set_option()', mens den sidste illustration udfører metoden 'option_context()'. Alle disse teknikker er demonstreret for at gøre dig fortrolig med de alternative måder, pandaer giver os for at opnå det ønskede resultat.