'Pandaerne' er et fantastisk sprog til at udføre analyse af data på grund af dets store økosystem af datacentrerede pythonpakker. Det gør analysen og importen af begge faktorer nemmere. Standardafvigelsen er en 'typisk' afvigelse afledt af middelværdien. Det bruges meget, da det returnerer de originale måleenheder for datarammen. Pandaerne brugte std() til beregningen af standardafvigelsen. Standardafvigelsen kan beregnes ud fra de givne værdier, der kan være i datarammen i form af en række eller kolonne. Vi vil implementere alle mulige måder, hvorpå pandas standardafvigelse bruges. Til implementering af koden vil vi bruge værktøjet 'spyder', som det er skrevet i et python-venligt miljø.'
Syntaks
“df.std ( ) ”
Følgende syntaks bruges til at beregne standardafvigelsen i datarammen. 'df' i datarammen er forkortelsen af 'dataframe'. Hvad gør standardafvigelsen? Det måler, hvor udvidet de nødvendige data er. Jo mere udvidede høje værdier, jo højere skal standardafvigelsen forekomme.
Vend tilbage
Pandas standardafvigelse returnerer datarammen, hvis niveauet er angivet baseret på kravet.
Bemærk, at funktionen 'std()' automatisk vil ignorere 'NaN'-værdierne i 'df', mens pandaernes standardafvigelse beregnes. 'NaN' kan forklares som 'ikke et tal', hvilket betyder, at der ikke er tildelt nogen værdi til en bestemt.
Følgende er de metoder, der vil blive udført med eksempler på pandaernes standardafvigelse:
-
- Pandas standardafvigelsesberegning i en enkelt kolonne.
- Pandas standardafvigelsesberegning i flere kolonner.
- Pandas standardafvigelsesberegning af alle numeriske kolonner.
- pandas standardafvigelse ved hjælp af aksen = 1.
- pandas standardafvigelse ved hjælp af aksen = 0.
Oprettelse af datarammen til beregning af standardafvigelse i pandaer
Åbn først 'spyder'-softwaren. Importer nu pandas-biblioteket som pd. Vi vil skabe en dataramme, der består af en resultattavle med termer som 'x', 'y' og 'z' med deres point som '22', '10', '11', '16', '12', '45 ', '36' og '40'. Vi har også deres assist-værdier som '8', '9', '13', '7', '22', '24', '4' og '6', med værdien af rebounds som '17', ' 14”, “3”, 5”, “9”, “8”, “7” og “4”.
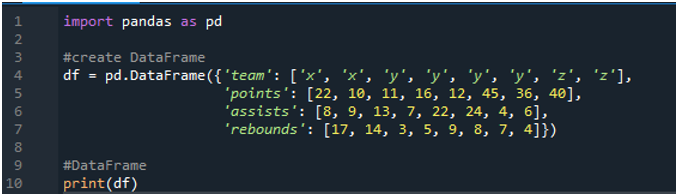
Displayene viser den oprettede dataramme i henhold til de værdier, der er tildelt i koden:

Eksempel # 01: Pandas standardafvigelsesberegning i en enkelt kolonne
I dette eksempel vil vi beregne standardafvigelsen for en enkelt kolonne i pandas-datarammen. Datarammen har holdets værdier som 'u', 'v' og 'b' med deres point som '44', '33', '22', '44', '45', '88', '96 ' og '78'. Værdierne for assists er som '7', '8', '9', '10', '11', '14', '18' og '17' med værdierne for rebounds som '11', ' 9”, “8”, “7”, “6”, “5”, “4” og “3”. Kolonnen 'punkter' vælges fra datarammen for at beregne standardafvigelsen i enkelt kolonne.
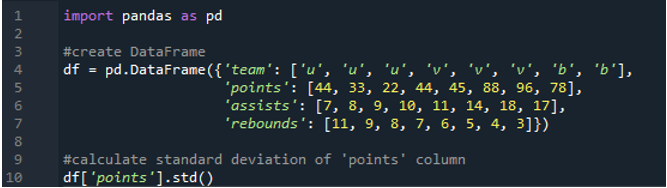
Outputtet viser standardafvigelsen beregnet for kolonnen 'punkter':

Eksempel # 02: Pandas standardafvigelsesberegning i flere kolonner
I dette eksempel vil vi udføre pandaernes standardafvigelsesberegninger i flere kolonner. I denne dataramme er dataene igen fra sportsresultattavlen med holdets værdier som 'n', 'w' og 't' med score som '33', '22', '66', '55', '44', '88', '99' og '77'. Assists som '9', '7', '8', '11', '16', '14', '12' og '13' og rebounds som '5', '8', '1', ' 2”, “3”, “4”, “6” og “7”. Her vil vi beregne standardafvigelsen for de to kolonner 'points' og 'rebounds' ved at bruge funktionen std() anvendt på datarammen.
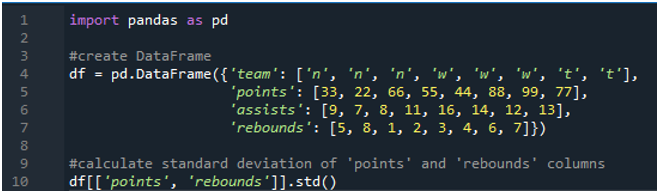
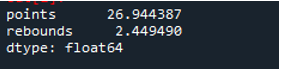
Som vi ser, viser outputtet, at standardafvigelsen kom op som henholdsvis 26,944387 i point-kolonnen og 2,449490 i rebound-kolonnen.
Eksempel # 03: Pandas standardafvigelsesberegning af alle numeriske kolonner
Nu har vi lært, hvordan man beregner standardafvigelsen for enkelte og flere rækker. Hvad hvis vi ikke ønsker at angive alle kolonnenavnene i datarammen og beregne hele datarammen? Dette er muligt med blot en simpel funktionsimplementering af pandaernes standardafvigelse til beregning af hele datarammen i resultaterne. Datarammen her består af 'l', 'm' og 'o' med scoringsværdierne '33', '36', '79', '78', '58', '55', og to hold scorer det samme det er '25'. Assists er som '1', '2', '3', '4', '6', '9', '5' og '7' og deres rebounds som '14', '10', '2' , '5', '8', '3', '6' og '9'. Vi kan beregne alle standardkolonneafvigelser fra pandaer i datarammen ved hjælp af pandaernes 'std()'-funktion.
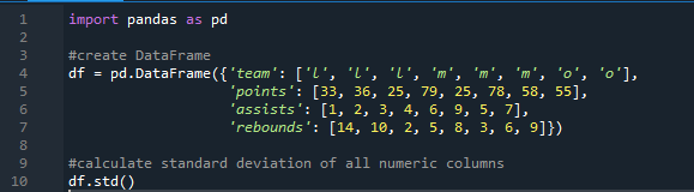
Displayet har den beregnede standardafvigelse for hele 'df' vist nedenfor; vi kan også bemærke, at pandaerne ikke har beregnet standardafvigelsen for den første kolonne, som er 'hold', fordi det ikke er en numerisk kolonne.
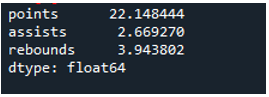
Eksempel # 04: Pandas standardafvigelse ved hjælp af aksen = 0
I dette eksempel har datarammerne sportens hold som 'g', 'h' og 'k' med yderligere data. Her vil vi beregne standardafvigelsen ved at bruge aksen som '0', en parameter brugt i pandaernes standardafvigelse. Dette argument beregner standardafvigelsen kolonnevis for datarammen.
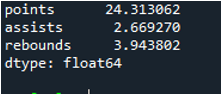
Følgende output viser resultaterne i kolonner af den beregnede standardafvigelse. Pointkolonnen har den beregnede standardafvigelse som '24.0313062', assists-kolonnen har den beregnede standardafvigelse som '2.669270', og rebound-kolonnens beregnede standardafvigelse er vist som '3.943802'.
Eksempel # 05: Pandas standardafvigelse ved brug af aksen = 1
Her vil vi bruge akseparameteren tildelt som '1' til at beregne standardafvigelsen i pandaer. Hvilken forskel kan akse '1' gøre? Argumentet '1'-akse beregner den rækkevise standardafvigelse af de numeriske værdier i datarammen. Datarammen har de tre hold som 's', 'd' og 'e', med tilføjelse af datakolonner, der er oprettet som point for teamet, assists fra teamet og rebounds for teamet. Retninger er alle tildelt forskellige værdier i datarammen. Denne akseparameter er sådan en game changer, da vi på det tidspunkt skal arbejde på dataene, hvor vi ønsker det skal være i en kolonne plus point beregnet af udført standardafvigelse.
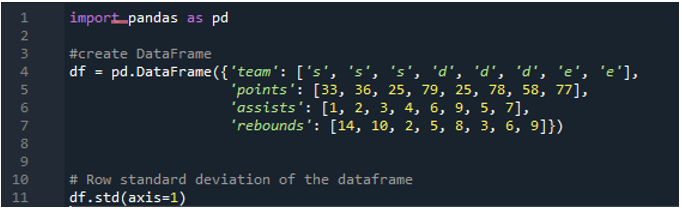
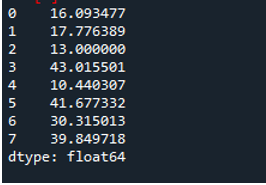
Følgende output viser standardafvigelsen beregnet i en række af datarammen:
Konklusion
Pandas standardafvigelse er en meget teknisk funktion, hvilket er en meget gavnlig funktion, da den finder standardafvigelsen fra pandas dataframes entusiasmepagt. I denne leder har vi studeret metoderne til at beregne standardafvigelsen hos pandaer. Vi har lavet enkelt-kolonne beregninger af standardafvigelse og flere kolonner og også beregnet standardafvigelsen for hele datarammen sammen. Alle strategierne fungerer godt, så længe de bruges konsekvent og med de ønskede resultater.