Hurtig disposition
Dette indlæg indeholder følgende sektioner:
- Sådan bruges en Async API Agent i LangChain
- Metode 1: Brug af seriel udførelse
- Metode 2: Brug af samtidig udførelse
- Konklusion
Hvordan bruger man en Async API Agent i LangChain?
Chatmodeller udfører flere opgaver samtidigt som at forstå strukturen af prompten, dens kompleksitet, udtrække information og mange flere. Ved at bruge Async API-agenten i LangChain kan brugeren bygge effektive chatmodeller, der kan besvare flere spørgsmål ad gangen. For at lære processen med at bruge Async API-agenten i LangChain skal du blot følge denne vejledning:
Trin 1: Installation af Frameworks
Først og fremmest skal du installere LangChain-rammeværket for at få dets afhængigheder fra Python-pakkehåndteringen:
pip installer langkæde
Derefter skal du installere OpenAI-modulet for at bygge sprogmodellen som llm og indstille dens miljø:
pip installer openai
Trin 2: OpenAI-miljø
Det næste trin efter installationen af moduler er opsætning af miljøet ved hjælp af OpenAI's API-nøgle og Serper API for at søge efter data fra Google:
importere du
importere getpass
du . rundt regnet [ 'OPENAI_API_KEY' ] = getpass . getpass ( 'OpenAI API-nøgle:' )
du . rundt regnet [ 'SERPER_API_KEY' ] = getpass . getpass ( 'Serper API-nøgle:' )
Trin 3: Import af biblioteker
Nu hvor miljøet er indstillet, skal du blot importere de nødvendige biblioteker som asyncio og andre biblioteker ved hjælp af LangChain-afhængighederne:
fra langkæde. agenter importere initialize_agent , indlæs_værktøjerimportere tid
importere asyncio
fra langkæde. agenter importere AgentType
fra langkæde. llms importere OpenAI
fra langkæde. tilbagekald . stdout importere StdOutCallbackHandler
fra langkæde. tilbagekald . sporstoffer importere LangChainTracer
fra aiohttp importere ClientSession
Trin 4: Opsætningsspørgsmål
Indstil et spørgsmålsdatasæt, der indeholder flere forespørgsler relateret til forskellige domæner eller emner, der kan søges på internettet (Google):
spørgsmål = ['Hvem er vinderen af U.S. Open mesterskabet i 2021' ,
'Hvad er alderen på Olivia Wildes kæreste' ,
'Hvem er vinderen af Formel 1-verdenstitlen' ,
'Hvem vandt US Open kvindernes finale i 2021' ,
'Hvem er Beyonces mand, og hvad er hans alder' ,
]
Metode 1: Brug af seriel udførelse
Når alle trinene er fuldført, skal du blot udføre spørgsmålene for at få alle svarene ved hjælp af den serielle udførelse. Det betyder, at ét spørgsmål vil blive udført/vist ad gangen og også returnere den fulde tid, det tager at udføre disse spørgsmål:
llm = OpenAI ( temperatur = 0 )værktøjer = indlæs_værktøjer ( [ 'google-header' , 'llm-matematik' ] , llm = llm )
agent = initialize_agent (
værktøjer , llm , agent = AgentType. ZERO_SHOT_REACT_DESCRIPTION , ordrig = Rigtigt
)
s = tid . perf_counter ( )
#configuring time counter for at få tiden brugt til hele processen
til q i spørgsmål:
agent. løb ( q )
forløbet = tid . perf_counter ( ) - s
#print den samlede tid, som agenten brugte til at få svarene
Print ( f 'Serie udført på {elapsed:0.2f} sekunder.' )
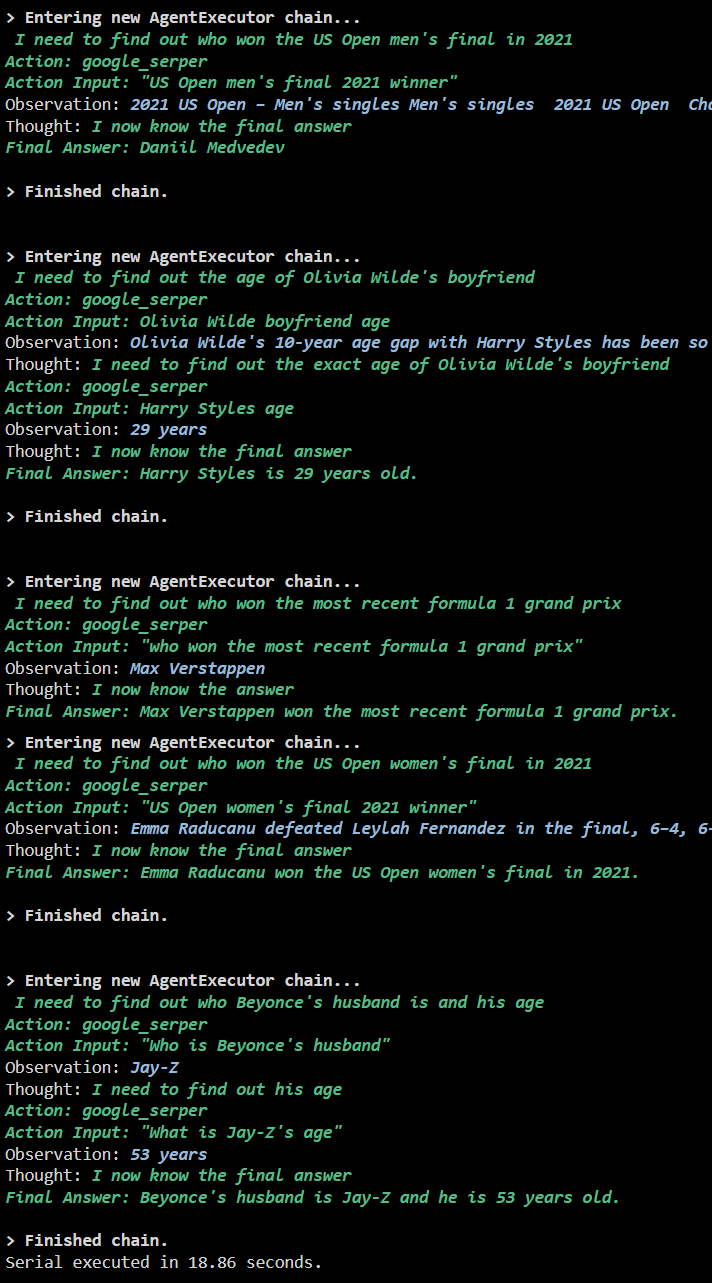
Produktion
Følgende skærmbillede viser, at hvert spørgsmål besvares i en separat kæde, og når den første kæde er færdig, bliver den anden kæde aktiv. Serieudførelsen tager længere tid at få alle svarene individuelt:
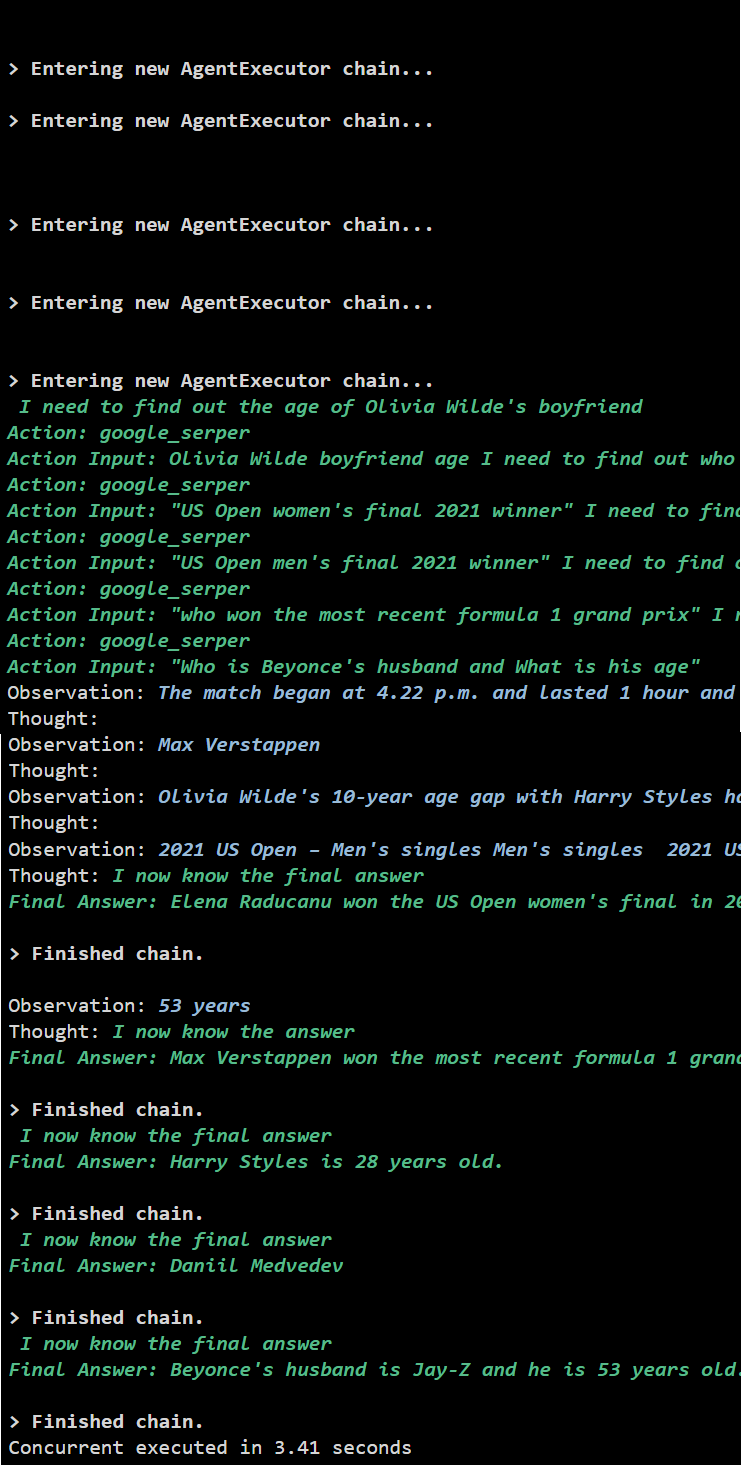
Metode 2: Brug af samtidig udførelse
Concurrent execution-metoden tager alle spørgsmålene og får deres svar samtidigt.
llm = OpenAI ( temperatur = 0 )værktøjer = indlæs_værktøjer ( [ 'google-header' , 'llm-matematik' ] , llm = llm )
#Konfiguration af agent ved hjælp af ovenstående værktøjer for at få svar samtidigt
agent = initialize_agent (
værktøjer , llm , agent = AgentType. ZERO_SHOT_REACT_DESCRIPTION , ordrig = Rigtigt
)
#configuring time counter for at få tiden brugt til hele processen
s = tid . perf_counter ( )
opgaver = [ agent. sygdom ( q ) til q i spørgsmål ]
afvent asyncio. samle ( *opgaver )
forløbet = tid . perf_counter ( ) - s
#print den samlede tid, som agenten brugte til at få svarene
Print ( f 'Samtidig udført i {elapsed:0.2f} sekunder' )
Produktion
Den samtidige udførelse udtrækker alle data på samme tid og tager meget kortere tid end den serielle udførelse:
Det handler om at bruge Async API-agenten i LangChain.
Konklusion
For at bruge Async API-agenten i LangChain skal du blot installere modulerne for at importere bibliotekerne fra deres afhængigheder for at få asyncio-biblioteket. Derefter skal du konfigurere miljøerne ved hjælp af OpenAI- og Serper API-nøglerne ved at logge ind på deres respektive konti. Konfigurer sættet af spørgsmål relateret til forskellige emner og eksekver kæderne serielt og samtidigt for at få deres eksekveringstid. Denne vejledning har uddybet processen med at bruge Async API-agenten i LangChain.